







Neo4j 入门
一、什么是图形数据库
图数据库是基于图论实现的一种新型 nosql 数据库,其数据库存储结构和数据的查询方式都是以图论为基础的。图论中图的基本元素为节点和边,在图数据库中对应的就是节点和关系。

neo4j 基本元素与概念
-
标签:在Neo4j中,一个节点可以有一个以上的标签,从现实世界的角度去看,一个标签可以认为节点的某个类别,比如BOOK、MOVIE等等。
-
节点:节点是指一个实实在在的对象,这个对象可以有好多的标签,表示对象的种类,也可以有好多的属性,描述其特征,节点与节点之间还可以形成多个有方向(或者没有方向)的关系。

-
关系:用来描述节点与节点之间的关系,这也是图数据与与普通数据库最大的区别,正是因为有这些关系的存在,才可以描述那些我们普通行列数据库所很难表示的网状关系,比如我们复杂的人际关系网,所谓的六度理论,就可以很方便的用图数据库进行模拟,比如我们大脑神经元之间的连接方式,都是一张复杂的网。关系可以拥有属性。

-
属性:描述节点的特性,采用的是Key-Value结构,可以随意设定来描述节点的特征。
关于图论?
图论是数学的一个分支,它以图为研究对象,图论中的图是由若干个给定的点及连接两点的线所构成的图型,这种图形通常用来描绘某些事物之间的某种特定关系,用点代表事务,用连接两点的线表示相应两个事物间具有这种关系。
二、Neo4j 图形理论基础
图形是一组节点和连接这些节点的关系。 图形以属性的形式将数据存储在节点和关系中。 属性是用于表示数据的键值对。
在图形理论中,我们可以表示一个带有圆的节点,节点之间的关系用一个箭头标记表示。
最简单的可能图是单个节点。
我们可以使用节点表示社交网络(如Google+(GooglePlus)个人资料)。 它不包含任何属性。
向 Google+个人资料添加一些属性

此节点包含一组属性。 属性是一个名称:值对。
在两个节点之间创建关系
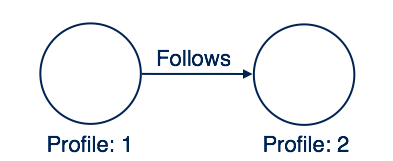
此处在两个配置文件之间创建关系名称“跟随”。 这意味着 Profile-1遵循 Profile-2。
复杂的示例图

这里节点用关系连接。 关系是单向或双向的。
从PQR到XYZ的关系是单向关系。
从ABC到PQR的关系是双向关系。
三、什么是Neo4j
Neo4j是一个高性能的,NOSQL图形数据库,它将结构化数据存储在网络上而不是表中。它是一个嵌入式的、基于磁盘的、具备完全的事务特性的Java持久化引擎,但是它将结构化数据存储在网络(从数学角度叫做图)上而不是表中。
Neo4j也可以被看作是一个高性能的图引擎,该引擎具有成熟数据库的所有特性。
优点:
- 它很容易表示连接的数据
- 检索/遍历/导航更多的连接数据是非常容易和快速的
- 它非常容易地表示半结构化数据
- Neo4j CQL查询语言命令是人性化的可读格式,非常容易学习
- 使用简单而强大的数据模型
- 它不需要复杂的连接来检索连接的/相关的数据,因为它很容易检索它的相邻节点或关系细节没有连接或索引
四、Neo4j 安装
- 检查 jdk 环境 必须为 jdk 11
- 下载安装包
- 解压
tar -zxvf neo4j-chs-community-4.2.4-unix.tar.gz
- 修改配置文件
vim conf/neo4j.conf
- 放开访问权限
dbms.connectors.default_listen_address=0.0.0.0
- 启动
./bin/neo4j start
- 停止
./bin/neo4j stop
- 访问 web 管理页面
http://ip:7474/browser
neo4j 自带示例:Movie Graph
- 节点创建
- 节点查询
- 关系查询

五、Cypher 查询语言
概念:
Cypher 是一种声明式图数据库查询语言,类似关系数据库中当中 SQL,Python 语言惯用做法。
- MATCH:匹配图模式
- WHERE:过滤条件
- RETURN:定义返回结果
基本语法:
| 关键字 | 作用 |
|---|---|
| CREATE | 创建 |
| MATCH | 匹配 |
| RETURN | 加载 |
| WHERE | 过滤检索条件 |
| DELETE | 删除节点和关系 |
| REMOVE | 删除节点和关系的属性 |
| ORDER BY | 排序 |
| SET | 添加或更新属性 |
create 语法 |
CREATE (<node-name>:<label-name>)
# 创建一个带有标签名“Employee”的节点“emp”。
CREATE (emp:Employee)
CREATE (
<node-name>:<label-name>
{
<Property1-name>:<Property1-Value>
........
<Propertyn-name>:<Propertyn-Value>
}
)
# 创建具有一些属性(deptno,dname,位置)的Dept节点
CREATE (dept:Dept { deptno:10,dname:"Accounting",location:"Hyderabad" })
match 语法
MATCH
(
<node-name>:<label-name>
)
# 查询Dept下的内容
MATCH (dept:Dept) return dept
# 查询Employee标签下 id=123,name="Lokesh"的节点
MATCH (p:Employee {id:123,name:"Lokesh"}) RETURN p
## 查询Employee标签下name="Lokesh"的节点,使用(where命令)
MATCH (p:Employee)
WHERE p.name = "Lokesh"
RETURN p
return 语法
RETURN
<node-name>.<property1-name>,
........
<node-name>.<propertyn-name>
RETURN dept.deptno
delete 语法
# 删除节点子句
DELETE <node-name-list>
# 删除节点和关系子句
DELETE <node1-name>,<node2-name>,<relationship-name>
MATCH (e: Employee) DELETE e
MATCH (cc: CreditCard)-[rel]-(c:Customer)
DELETE cc,c,rel
match(aa:pig{name:"猪爷爷",age:12})-[r:夫妻]-(bb:pig{name:"猪奶奶",age:12}) delete aa,bb,r
remove 语法
删除节点或关系的标签
删除节点或关系的属性
REMOVE <property-name-list>
REMOVE <label-name-list>
MATCH (book { id:122 })
REMOVE book.price
RETURN book
MATCH (m:Movie)
REMOVE m:Picture
union 语法
它将两组结果中的公共行组合并返回到一组结果中。 它不从两个节点返回重复的行。
限制:结果列类型和来自两组结果的名称必须匹配,这意味着列名称应该相同,列的数据类型应该相同。
<MATCH Command1>
UNION
<MATCH Command2>
MATCH (cc:CreditCard) RETURN cc.id,cc.number
UNION
MATCH (dc:DebitCard) RETURN dc.id,dc.number

union all 语法
它结合并返回两个结果集的所有行成一个单一的结果集。它还返回由两个节点重复行。
限制:结果列类型,并从两个结果集的名字必须匹配,这意味着列名称应该是相同的,列的数据类型应该是相同的。
<MATCH Command1>
UNION ALL
<MATCH Command2>
MATCH (cc:CreditCard)
RETURN cc.id as id,cc.number as number,cc.name as name,
cc.valid_from as valid_from,cc.valid_to as valid_to
UNION ALL
MATCH (dc:DebitCard)
RETURN dc.id as id,dc.number as number,dc.name as name,
dc.valid_from as valid_from,dc.valid_to as valid_to

limit 语法
LIMIT”子句来过滤或限制查询返回的行数
LIMIT <number>
MATCH (emp:Employee)
RETURN emp
LIMIT 2
skip 语法
SKIP”子句来过滤或限制查询返回的行数。
SKIP<number>
MATCH (emp:Employee)
RETURN emp
SKIP 2
基本查找 match return
# 创建两个节点,猪爸爸与猪妈妈,他们之间是属于夫妻关系
# 其中create表示新建
# p 表示这个节点的别名
# pig表示节点p的标签pig的属性
# {} 大括号中间的键值对,表示p这个节点作为pig这个标签类别所拥有的属性
# -[r:夫妻]-> 表示节点p指向节点f,他们之间的关系是夫妻,这个关系的别名是r,r可以拥有属于自己的属性
# return 表示执行这段语句之后,需要返回的对象,return p,r,f 表示返回 节点p,节点f,以及他们之间的关系r
CREATE (p:pig{name:"猪爸爸",age:5})-[r:夫妻]->(f:pig{name:"猪妈妈",age:4}) RETURN p,r,f;
查找指定节点、指定属性、指定关系的节点、关系
# MATCH 匹配命令
# return 后面的别名p还可以利用as 设置指定返回值名称,如:p as username
MATCH (p:pig{name:"猪爸爸"})-[r]-(n) RETURN p,r,n;
对查找结果进行排序order by,并限制返回条数 limit
order by关键字与SQL里面是一样的操作,后面跟上需要根据排序的关键字,limit的操作是指定输出前几条
# 这里利用order by来指定返回按照Person.name来排序
# limit 表示只返回前3条数据
match(p:pig) return p order by p.name limit 3
删除节点 delete 命令
删除节点的操作也是通过dlete来操作,如果被删除的节点存在Relationship,那么单独删除该节点的操作会不成功,所以如果想删除一个已经存在关系的节点,需要同时将关系进行删除。
# 删除指定条件的节点
# 先通过匹配关键字match找到匹配元素,然后通过delete关键字指定删除
MATCH (p:pig{name:"猪爸爸"}) delete p;
# 删除节点和节点相关的关系
MATCH (p:pig{name:"猪爸爸"})-[r]-() delete p,r;
删除属性 remove 命令
remove命令是用来删除节点或者关系的属性
neo4j 字符串函数
upper,lower,substring,replac四种字符串的操作,其中upper与lower在将来的版本中会被修改为toupper/tolower
//大写转换操作
MATCH (p:pig) return toupper(p.name);
聚合函数
常用的聚合函数有COUNT、MAX、MIN、AVG、SUM等五种。
MATCH (p:pig) return p.name as name,p.age as age,count(p) as count,max(p.age) as maxAge,min(p.age) as minAge,avg(p.age) as avgAge,sum(p.age) as sumAge;
关系函数
| 函数名 | 功能描述 |
|---|---|
| STARTNODE | 查找关系起点 |
| ENDNODE | 查找关系终点 |
| ID | 查找关系id |
| TYPE | 查找关系的类型,也就是我们在图中看到的名称 |
# 先获取关系,然后通过关系函数来获取关系 id,type,起始节点,终止节点等信息
MATCH ()-[r:父子]-() return stratnode(r).name as start_node,endnode(r).name as end_node,id(r) as relationship_id,type(r) as realtionship_type

小猪佩奇家庭族谱示例:

- 猪爷爷、猪奶奶
- 猪爸爸、猪妈妈
- 乔治、佩奇
- 猪爸爸、猪妈妈
- 猪外公、猪外婆
//创建基础节点
CREATE (:pig{name:"猪爷爷",age:12}),(:pig{name:"猪奶奶",age:9})
//基于现有节点创建关系
MATCH(a:pig{name:"猪爷爷",age:12}) MATCH(b:pig{name:"猪奶奶",age:9}) CREATE (a) -[r:夫妻]->(b) RETURN r;
//创建关系加节点
CREATE (:pig{name:"猪爸爸",age:5})-[:夫妻]->(:pig{name:"猪妈妈",age:4})
//创建佩奇,乔治以及关系
CREATE (:pig{name:"佩奇",age:2})-[:姐弟]->(:pig{name:"乔治",age:1})
//创建猪爷爷,猪爸爸关系
MATCH(c:pig{name:"猪爸爸",age:5}) MATCH(d:pig{name:"猪爷爷",age:12}) CREATE (d) -[r:父子]->(c) RETURN r;
//创建猪爸爸与佩奇关系
MATCH(c:pig{name:"猪爸爸",age:5}) MATCH(d:pig{name:"佩奇",age:2}) CREATE (c) -[r:父女]->(d) RETURN r;
//创建猪爷爷与佩奇关系
MATCH(c:pig{name:"猪爷爷",age:12}) MATCH(d:pig{name:"佩奇",age:2}) CREATE (c) -[r:孙女]->(d) RETURN r;
//创建猪奶奶与佩奇关系
MATCH(c:pig{name:"猪奶奶",age:9}) MATCH(d:pig{name:"佩奇",age:2}) CREATE (c) -[r:孙女]->(d) RETURN r;
//创建猪奶奶与猪爸爸关系
MATCH(c:pig{name:"猪奶奶",age:9}) MATCH(d:pig{name:"猪爸爸",age:5}) CREATE (c) -[r:母子]->(d) RETURN r;
//修改属性
MATCH (a:pig{name:"猪爸爸",age:5}) SET a.age=4;
//创建多标签节点
CREATE (a:die:pig{name:"猪祖父",age:15}) RETURN a.name;
//删除节点
MATCH (n:die) DELETE n;
六、Neo4j 程序开发
-
java 嵌入式开发模式:
neo4j 基于 java 语言开发的,在第一版发布之初是专门针对java 领域的,所以它能够与 java 开发天然结合, java 程序可以直接集成 neo4j 库至应用当中。

-
各语言驱动包开发模式:
毕竟 neo4j 是一门数据库,其使用范围 肯定不能局限于java 应用,为了满足其他语言的调用,Neo4j 引入了驱动开发模式。

















 969
969











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











