






偏好优化(preference optimization )算法大全:

本篇介绍下SimPO
SimPO(Simple Preference Optimization)的设计核心在于简化偏好优化过程,同时提升模型的表现。其设计主要围绕两个关键点展开:长度归一化的奖励和目标奖励边际。以下是对SimPO设计的详细展开:
1. 长度归一化的奖励(Length-Normalized Reward)
1.1 背景与问题
在传统的偏好优化方法(如DPO)中,奖励函数通常基于模型生成的对数概率。然而,直接使用对数概率作为奖励会导致长度偏差(length bias):较长的序列往往具有较低的对数概率,因为每个额外的token都会降低整体的对数概率。这可能导致模型倾向于生成较短的响应,从而影响生成质量。
1.2 SimPO的解决方案
SimPO通过长度归一化来解决这一问题。具体来说,SimPO使用平均对数概率作为奖励,而不是总对数概率。公式如下:

其中:
-
πθ(y∣x) 是模型在给定输入 x 下生成响应 y 的概率。
-
∣y∣是响应 y 的长度(token数量)。
-
β 是一个缩放因子,用于控制奖励的幅度。
通过将奖励归一化为每个token的平均对数概率,SimPO避免了长度偏差,使得模型不会因为生成长度较长的响应而受到惩罚。
1.3 长度归一化的优势
-
消除长度偏差:长度归一化确保模型不会倾向于生成过长或过短的响应,从而提升生成质量。
-
与生成过程对齐:在生成过程中,模型通常使用平均对数概率来评估候选序列的质量(如beam search中的排序)。SimPO的奖励设计与生成过程一致,避免了训练和推理之间的不一致性。
2. 目标奖励边际(Target Reward Margin)
2.1 背景与问题
在偏好优化中,模型需要区分“获胜响应”和“失败响应”。传统的Bradley-Terry模型通过最大化获胜响应和失败响应之间的奖励差异来实现这一点。然而,这种方法可能会导致模型在优化过程中过于关注微小的奖励差异,从而影响泛化能力。
2.2 SimPO的解决方案
SimPO引入了目标奖励边际(target reward margin),确保获胜响应和失败响应之间的奖励差异至少超过一个预设的边际值 γ。具体来说,SimPO的Bradley-Terry目标被修改为:
![]()
其中:
-
yw 是获胜响应,yl 是失败响应。
-
σ是sigmoid函数。
-
γ是目标奖励边际,通常设置为一个正数。
2.3 目标奖励边际的优势
-
提升泛化能力:通过引入目标奖励边际,SimPO鼓励模型在获胜响应和失败响应之间保持更大的奖励差异,从而提升模型的泛化能力。
-
防止过拟合:目标奖励边际可以防止模型过度拟合训练数据中的微小奖励差异,从而提升在未见数据上的表现。
3. SimPO的最终目标函数
结合长度归一化的奖励和目标奖励边际,SimPO的最终目标函数如下:

其中:
-
DD 是偏好数据集,包含输入 x、获胜响应 yw 和失败响应 yl。
-
β 是奖励的缩放因子。
-
γ 是目标奖励边际。
4. SimPO的设计优势
4.1 无需参考模型
SimPO的一个显著优势是它不需要参考模型。传统的DPO方法依赖于一个参考模型来计算奖励,而SimPO直接使用当前策略模型的对数概率作为奖励。这不仅简化了训练过程,还减少了内存和计算开销。
4.2 与生成过程对齐
SimPO的奖励设计与生成过程中的平均对数概率度量一致,避免了训练和推理之间的不一致性。这使得SimPO在生成任务中表现更好。
4.3 防止长度偏差
通过长度归一化,SimPO避免了模型倾向于生成长度较长或较短的响应,从而提升了生成质量。
4.4 提升泛化能力
目标奖励边际的引入使得SimPO在优化过程中更加稳健,能够更好地泛化到未见数据。
5. SimPO与DPO的对比
5.1 奖励设计的差异
-
DPO:DPO的奖励基于当前策略模型和参考模型的对数概率比值:

这种设计依赖于参考模型,并且可能导致奖励与生成过程中的对数概率度量不一致。
-
SimPO:SimPO的奖励基于当前策略模型的平均对数概率:

这种设计直接与生成过程对齐,且不需要参考模型。
5.2 性能差异
实验结果表明,SimPO在多个基准测试上显著优于DPO,尤其是在AlpacaEval 2和Arena-Hard上。SimPO的生成质量更高,且没有显著增加响应长度。
6. 总结
SimPO通过长度归一化的奖励和目标奖励边际两个关键设计,简化了偏好优化过程,并显著提升了模型的表现。其优势在于:
-
无需参考模型,降低了计算和内存开销。
-
奖励设计与生成过程一致,避免了训练和推理之间的不一致性。
-
通过长度归一化和目标奖励边际,提升了生成质量和泛化能力。
SimPO的设计为偏好优化提供了一种简单而有效的方法,展示了其在模型对齐任务中的巨大潜力。
附录1:较长的序列往往具有较低的对数概率
这句话可以从概率模型和对数概率的性质来理解。为了更清楚地解释这一点,我们需要从以下几个方面展开:
1. 概率模型的链式法则
在语言模型中,生成一个序列的概率是通过链式法则计算的。假设我们有一个序列 y=(y1,y2,…,yn),其中 yiyi 是第 ii 个token,那么生成这个序列的概率可以表示为:
![]()
每个 P(yi∣x,y<i)是模型在给定上下文 x 和前面的token y<i下生成第 i 个token的概率。由于每个概率值都在 [0,1] 之间,多个概率值相乘会导致整体概率 P(y∣x)随着序列长度的增加而指数级下降。
2. 对数概率的性质
为了简化计算,语言模型通常使用对数概率(log probability)而不是原始概率。对数概率的性质如下:
-
原始概率 P(y∣x)P(y∣x) 是一个很小的值(因为多个小于1的数相乘)。
-
取对数后,乘积变为求和:
l
这样,对数概率的计算更加稳定,且避免了数值下溢问题。
然而,即使使用对数概率,随着序列长度的增加,对数概率的总和 logP(y∣x)也会逐渐减小。这是因为每个token的对数概率 logP(yi∣x,y<i)通常是一个负数(因为 P(yi∣x,y<i)<1),随着序列长度的增加,这些负数会累加,导致总对数概率变得更小(即更负)。
3. 长度偏差(Length Bias)
由于较长的序列具有更低的对数概率,如果直接使用总对数概率作为奖励(如DPO中的奖励设计),模型可能会倾向于生成较短的序列,因为较短序列的总对数概率通常较高(负得较少)。这种现象被称为长度偏差(length bias)。
例子:
假设有两个序列:
-
序列A:长度为5,每个token的对数概率为 -0.5,总对数概率为 −2.5−2.5。
-
序列B:长度为10,每个token的对数概率为 -0.4,总对数概率为 −4.0−4.0。
尽管序列B的每个token的对数概率更高(-0.4 > -0.5),但由于序列B更长,其总对数概率更低(-4.0 < -2.5)。如果直接使用总对数概率作为奖励,模型可能会倾向于选择序列A,尽管序列B的每个token生成质量更高。
4. SimPO的解决方案:长度归一化
为了消除长度偏差,SimPO引入了长度归一化,即使用平均对数概率作为奖励,而不是总对数概率。具体公式为:

通过将总对数概率除以序列长度 ∣y∣,SimPO消除了长度对奖励的影响,使得模型不会因为生成长度较长的序列而受到惩罚。
例子(续):
-
序列A的平均对数概率:−2.5/5=−0.5。
-
序列B的平均对数概率:−4.0/10=−0.4。
在这种情况下,序列B的平均对数概率更高(-0.4 > -0.5),因此模型会更倾向于选择序列B,而不是序列A。
5. 总结
-
较长的序列具有较低的对数概率:这是因为多个小于1的概率值相乘会导致整体概率指数级下降,而对数概率是这些概率的对数和,随着序列长度的增加,对数概率的总和会变得更小(更负)。
-
长度偏差:如果直接使用总对数概率作为奖励,模型可能会倾向于生成较短的序列,因为较短序列的总对数概率通常较高。
-
SimPO的解决方案:通过长度归一化(使用平均对数概率),SimPO消除了长度偏差,使得模型能够公平地评估不同长度的序列,从而提升生成质量。
这种设计使得SimPO在偏好优化任务中表现更加稳健,尤其是在生成长度较长的响应时,能够避免模型过度倾向于生成短响应。
附录2:Bradley-Terry模型
Bradley-Terry模型是一种经典的统计模型,用于处理成对比较(pairwise comparison)数据。它的核心思想是通过比较两个实体的相对强度或偏好,来估计它们的潜在能力或偏好得分。在偏好优化(Preference Optimization)任务中,Bradley-Terry模型被广泛用于建模人类对模型生成响应的偏好。
1. Bradley-Terry模型的基本形式
假设我们有两个实体 A 和 B,它们的潜在能力或偏好得分分别为 sA 和 sB。Bradley-Terry模型定义 A 比 B 更受偏好的概率为:

其中:
-
σ 是sigmoid函数,定义为
 。
。 -
sA和 sB 分别是实体 A 和 B 的得分。
这个公式表示,实体 A 比 B 更受偏好的概率取决于它们的得分差异 sA−sB。如果 sA>sB,则 A 更受偏好的概率大于0.5;反之则小于0.5。
2. Bradley-Terry模型在偏好优化中的应用
在偏好优化任务中,Bradley-Terry模型被用于建模人类对模型生成响应的偏好。假设我们有一个输入 x,模型生成了两个响应 yw(获胜响应)和 yl(失败响应)。我们可以将 yw 和 yl 的得分分别表示为 s(x,yw)和 s(x,yl),然后使用Bradley-Terry模型来计算 yw 比 yl 更受偏好的概率:
![]()
其中:
-
s(x,yw) 和 s(x,yl)分别是响应 yw 和 yl 的得分。
-
σ是sigmoid函数。
3. Bradley-Terry目标函数
在偏好优化任务中,我们的目标是最大化人类偏好的对数似然。假设我们有一个偏好数据集 D={(x,yw,yl)},其中每个样本包含一个输入 x、一个获胜响应 yw 和一个失败响应 yl。我们可以使用Bradley-Terry模型来定义目标函数:
![]()
这个目标函数的意义是:
-
对于每个样本 (x,yw,yl),我们希望 s(x,yw)比 s(x,yl)大,即 yw 的得分高于 yl。
-
通过最小化这个目标函数,我们可以训练模型使得 yw 的得分尽可能高于 yl。
4. Bradley-Terry目标与SimPO的结合
在SimPO中,Bradley-Terry目标被进一步扩展,引入了目标奖励边际(target reward margin)。具体来说,SimPO的目标函数为:
![]()
其中:
-
γ 是目标奖励边际,确保 yw 的得分比 yl的得分至少高出 γ。
-
s(x,yw) 和 s(x,yl) 分别是响应 yw 和 yl 的得分,定义为:
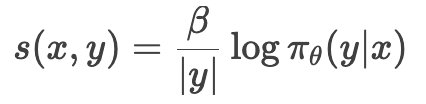
其中 πθ(y∣x)是模型在给定输入 x 下生成响应 y 的概率,∣y∣是响应 y 的长度,β 是缩放因子。
5. Bradley-Terry目标的优势
-
简单且有效:Bradley-Terry模型通过简单的sigmoid函数建模偏好,计算高效且易于优化。
-
可解释性:通过得分差异
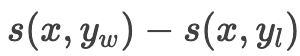 ,可以直观地理解模型对两个响应的偏好程度。
,可以直观地理解模型对两个响应的偏好程度。 -
灵活性:Bradley-Terry模型可以与其他技术(如SimPO中的目标奖励边际)结合,进一步提升模型的表现。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









