







一、Hadoop环境
1.1模板虚拟机环境准备
1)准备一台模板虚拟机hadoop100,虚拟机配置要求如下:
注:本文Linux系统环境全部以CentOS-7.5-x86-1804为例说明
模板虚拟机:内存4G,硬盘50G,安装必要环境,为安装hadoop做准备
[root@hadoop100 ~]# yum install -y epel-release
[root@hadoop100 ~]# yum install -y psmisc nc net-tools rsync vim lrzsz ntp libzstd openssl-static tree iotop git
使用yum安装需要虚拟机可以正常上网,yum安装前可以先测试下虚拟机联网情况
[root@hadoop100 ~]# ping www.baidu.com
PING www.baidu.com (14.215.177.39) 56(84) bytes of data.
64 bytes from 14.215.177.39 (14.215.177.39): icmp_seq=1 ttl=128 time=8.60 ms
64 bytes from 14.215.177.39 (14.215.177.39): icmp_seq=2 ttl=128 time=7.72 ms
2)关闭防火墙,关闭防火墙开机自启
[root@hadoop100 ~]# systemctl stop firewalld
[root@hadoop100 ~]# systemctl disable firewalld
3)创建自己的用户,并修改用户的密码
[root@hadoop100 ~]# useradd yourusername
[root@hadoop100 ~]# passwd yourpassword
4)配置你的用户具有root权限,方便后期加sudo执行root权限的命令
[root@hadoop100 ~]# vim /etc/sudoers修改/etc/sudoers文件,找到下面一行(91行),在root下面添加一行,如下所示:
## Allow root to run any commands anywhere
root ALL=(ALL) ALL
yourusername ALL=(ALL) NOPASSWD:ALL
5)在/opt目录下创建文件夹,并修改所属主和所属组
(1)在/opt目录下创建module、software文件夹
[root@hadoop100 ~]# mkdir /opt/module
[root@hadoop100 ~]# mkdir /opt/software
(2)修改module、software文件夹的所有者和所属组均为你的用户
[root@hadoop100 ~]# chown yourname:yourname/opt/module
[root@hadoop100 ~]# chown yourname:yourname/opt/software
(3)查看module、software文件夹的所有者和所属组
[root@hadoop100 ~]# cd /opt/
[root@hadoop100 opt]# ll
6)卸载虚拟机自带的open JDK
[root@hadoop100 ~]# rpm -qa | grep -i java | xargs -n1 rpm -e --nodeps7)重启虚拟机
[root@hadoop100 ~]# reboot1.2克隆虚拟机
1)利用模板机hadoop100,克隆三台虚拟机:hadoop102 hadoop103 hadoop104
2)修改克隆机IP,以下以hadoop102举例说明
(1)修改克隆虚拟机的静态IP
[root@hadoop100 ~]# vim /etc/sysconfig/network-scripts/ifcfg-ens33改成
DEVICE=ens33
TYPE=Ethernet
ONBOOT=yes
BOOTPROTO=static
NAME="ens33"
IPADDR=192.168.1.102
PREFIX=24
GATEWAY=192.168.1.2
DNS1=192.168.1.2
(2)查看Linux虚拟机的虚拟网络编辑器,编辑->虚拟网络编辑器->VMnet8
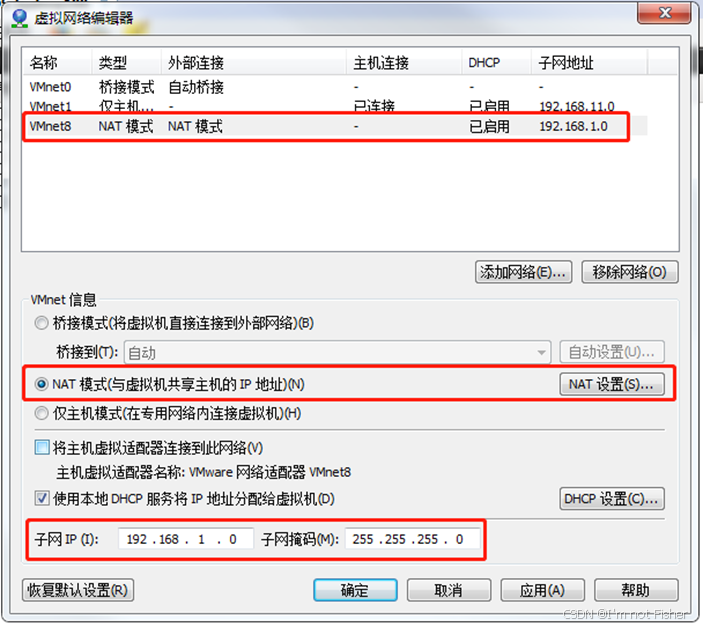
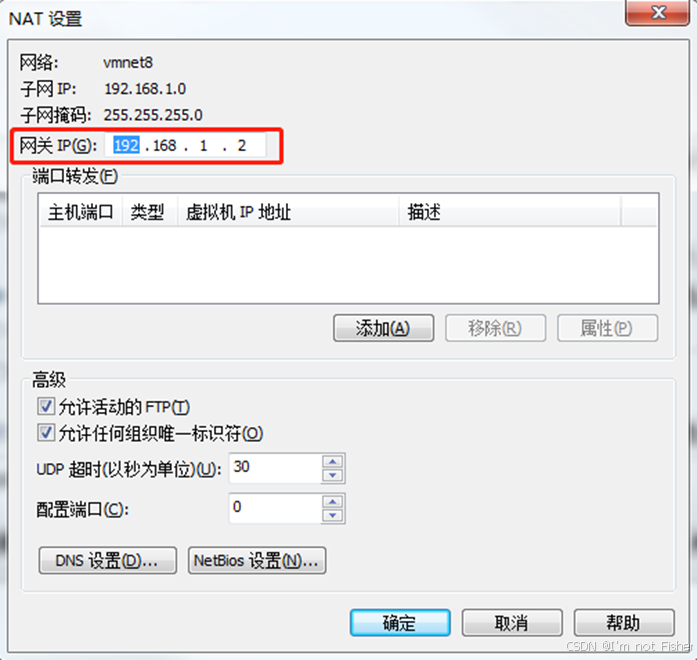 (3)查看Windows系统适配器VMware Network Adapter VMnet8的IP地址
(3)查看Windows系统适配器VMware Network Adapter VMnet8的IP地址
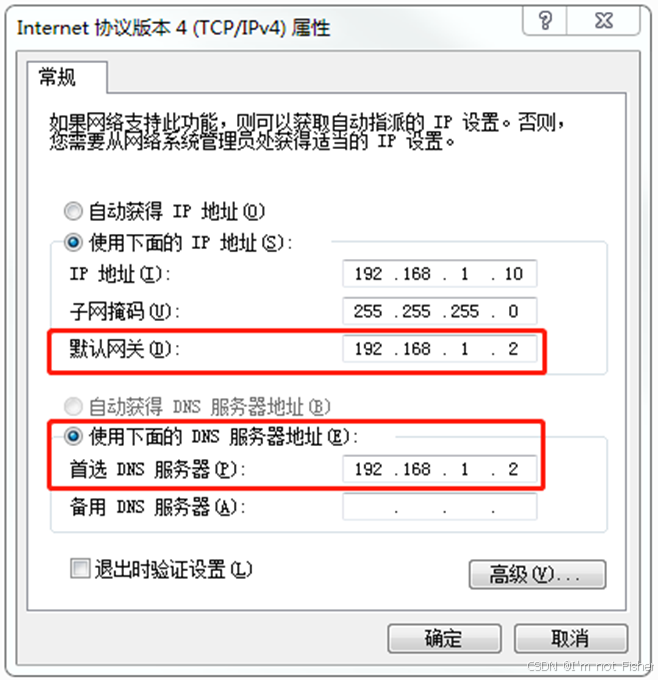
(4)保证Linux系统ifcfg-ens33文件中IP地址、虚拟网络编辑器地址和Windows系统VM8网络IP地址相同。
3)修改克隆机主机名,以下以hadoop102举例说明
(1)修改主机名称,两种方法二选一
[root@hadoop100 ~]# hostnamectl --static set-hostname hadoop102或者修改/etc/hostname文件
[root@hadoop100 ~]# vim /etc/hostname
hadoop102
(2)配置linux克隆机主机名称映射hosts文件,打开/etc/hosts
[root@hadoop100 ~]# vim /etc/hosts添加如下内容
192.168.1.100 hadoop100
192.168.1.101 hadoop101
192.168.1.102 hadoop102
192.168.1.103 hadoop103
192.168.1.104 hadoop104
192.168.1.105 hadoop105
192.168.1.106 hadoop106
192.168.1.107 hadoop107
192.168.1.108 hadoop108
4)重启克隆机hadoop102
[root@hadoop100 ~]# reboot5)修改windows的主机映射文件(hosts文件)
(1)如果操作系统是window7,可以直接修改
(a)进入C:\Windows\System32\drivers\etc路径
(b)打开hosts文件并添加如下内容,然后保存
192.168.1.100 hadoop100
192.168.1.101 hadoop101
192.168.1.102 hadoop102
192.168.1.103 hadoop103
192.168.1.104 hadoop104
192.168.1.105 hadoop105
192.168.1.106 hadoop106
192.168.1.107 hadoop107
192.168.1.108 hadoop108
2)如果操作系统是window10,先拷贝出来,修改保存以后,再覆盖即可
(a)进入C:\Windows\System32\drivers\etc路径
(b)拷贝hosts文件到桌面
(c)打开桌面hosts文件并添加如下内容
192.168.1.100 hadoop100
192.168.1.101 hadoop101
192.168.1.102 hadoop102
192.168.1.103 hadoop103
192.168.1.104 hadoop104
192.168.1.105 hadoop105
192.168.1.106 hadoop106
192.168.1.107 hadoop107
192.168.1.108 hadoop108
(d)将桌面hosts文件覆盖C:\Windows\System32\drivers\etc路径hosts文件
1.3在hadoop102安装JDK
1)卸载现有JDK
$ rpm -qa | grep -i java | xargs -n1 sudo rpm -e --nodeps2)用FTP工具将JDK导入到opt目录下面的software文件夹下面
3) “alt+p”进入sftp模式
4)选择jdk1.8拖入工具
5)在Linux系统下的opt目录中查看软件包是否导入成功
$ ls /opt/software/看到如下结果:
hadoop-3.1.3.tar.gz jdk-8u212-linux-x64.tar.gz6)解压JDK到/opt/module目录下
$ tar -zxvf jdk-8u212-linux-x64.tar.gz -C /opt/module/7)配置JDK环境变量
(1)新建/etc/profile.d/my_env.sh文件
$ sudo vim /etc/profile.d/my_env.sh添加如下内容
#JAVA_HOME
export JAVA_HOME=/opt/module/jdk1.8.0_212
export PATH=$PATH:$JAVA_HOME/bin
(2)保存后退出
(3)source一下/etc/profile文件,让新的环境变量PATH生效
$ source /etc/profile8)测试JDK是否安装成功
$ java -version如果能看到以下结果,则代表Java安装成功
java version "1.8.0_212"1.4Hadoop目录结构
1)查看Hadoop目录结构
$ ll
drwxrwxrwx. 2 xxx xxx 183 9月 12 2019 bin
drwxrwxrwx. 4 xxx xxx 37 4月 20 2024 data
drwxrwxrwx. 3 xxx xxx 20 9月 12 2019 etc
drwxrwxrwx. 2 xxx xxx 106 9月 12 2019 include
drwxrwxrwx. 3 xxx xxx 20 9月 12 2019 lib
drwxrwxrwx. 4 xxx xxx 288 9月 12 2019 libexec
-rw-rw-rw-. 1 xxx xxx 147145 9月 4 2019 LICENSE.txt
drwxrwxrwx. 3 xxx xxx 4096 1月 5 21:13 logs
-rw-rw-rw-. 1 xxx xxx 21867 9月 4 2019 NOTICE.txt
-rw-rw-rw-. 1 xxx xxx 1366 9月 4 2019 README.txt
drwxrwxrwx. 3 xxx xxx 4096 9月 12 2019 sbin
drwxrwxrwx. 4 xxx xxx 31 9月 12 2019 share
-rw-rw-rw-. 1 xxx xxx 40 4月 20 2024 test.txt
drwxrwxrwx. 2 xxx xxx 22 9月 16 22:46 wcinput
drwxrwxrwx. 2 xxx xxx 88 4月 20 2024 wcoutput42)重要目录
(1)bin目录:存放对Hadoop相关服务(HDFS,YARN)进行操作的脚本
(2)etc目录:Hadoop的配置文件目录,存放Hadoop的配置文件
(3)lib目录:存放Hadoop的本地库(对数据进行压缩解压缩功能)
(4)sbin目录:存放启动或停止Hadoop相关服务的脚本
(5)share目录:存放Hadoop的依赖jar包、文档、和官方案例
1.5在hadoop102安装Hadoop
Hadoop下载地址:https://archive.apache.org/dist/hadoop/common/hadoop-3.1.3/
1)用SFTP工具将hadoop-3.1.3.tar.gz导入到opt目录下面的software文件夹下面
切换到sftp连接页面,选择Linux下编译的hadoop jar包拖入
2)进入到Hadoop安装包路径下
$ cd /opt/software/3)解压安装文件到/opt/module下面
$ tar -zxvf hadoop-3.1.3.tar.gz -C /opt/module/4)查看是否解压成功
$ ls /opt/module/
hadoop-3.1.3
5)将Hadoop添加到环境变量
(1)获取Hadoop安装路径
$ pwd
/opt/module/hadoop-3.1.3
(2)打开/etc/profile.d/my_env.sh文件
sudo vim /etc/profile.d/my_env.sh在my_env.sh文件末尾添加如下内容:(shift+g)
#HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-3.1.3
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
(3)保存后退出
(4)让修改后的文件生效
$ source /etc/profile6)测试是否安装成功
$ hadoop version
Hadoop 3.1.3
7)重启(如果Hadoop命令不能用再重启)
$ sync
$ sudo reboot
1.6本地运行模式(官方wordcount)
1)创建在hadoop-3.1.3文件下面创建一个wcinput文件夹
$ mkdir wcinput2)在wcinput文件下创建一个word.txt文件
$ cd wcinput3)编辑word.txt文件
$ vim word.txt保存退出::wq
4)回到Hadoop目录/opt/module/hadoop-3.1.3
5)执行程序
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar wordcount wcinput wcoutput6)查看结果
$ cat wcoutput/part-r-00000看到如下结果:
python 2
java 2
scala 1
r 1



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









