







Rust基础拾遗
前言
通过Rust程序设计-第二版笔记的形式对Rust相关重点知识进行汇总,读者通读此系列文章就可以轻松的把该语言基础捡起来。
1.基本数据类型
1.1 简介
Rust 的内存和线程安全保障也依赖于其类型系统的健全性,而 Rust 的灵活性则源于其泛型类型和特型。
Rust 需要你提前做出更多规划。你必须明确写出各个函数参数和返回值的类型、结构体字段以及一些其他结构体。
基于已明确写出的类型,Rust 的类型推断会帮你推断出剩下的大部分类型。
fn build_vector() -> Vec<i16> {
let mut v = Vec::new();
v.push(10);
v.push(20);
v
}
类型推断让 Rust 具备了与动态类型语言相近的易读性,并且仍然能在编译期捕获类型错误。
函数可以是泛型的:单个函数就可以处理许多不同类型的值。
Rust 的泛型函数为该语言提供了一定程度的灵活性,而且仍然能在编译期捕获所有的类型错误。
1.2 整数类型
Rust 中数值类型的名称都遵循着一种统一的模式,也就是以“位”数表明它们的宽度,以前缀表明它们的用法
Rust 会使用 u8 类型作为字节值。
Rust 会把字符视为与数值截然不同的类型:char 既不是 u8,也不是 u32。
Rust 要求数组索引是 usize 值。用来表示数组或向量大小或某些数据结构中元素数量的值通常也是 usize 类型。
Rust 中的整型字面量可以带上一个后缀来指示它们的类型:42u8 是 u8 类型
为了让长数值更易读,可以在数字之间任意插入下划线。例如,可以将 u32 的最大值写为 4_294_967_295或分隔开数字的类型后缀(如 127_u8)
可以使用 as 运算符将一种整型转换为另一种整型。
1.3 浮点类型
Rust 的 f32 和 f64 分别对应于 C 和 C++(在支持 IEEE 浮点的实现中)以及 Java(始终使用 IEEE 浮点)中的 float 类型和 double 类型。
浮点数中整数部分之后的每个部分都是可选的,但必须至少存在小数部分、指数或类型后缀这三者中的一个,以将其与整型字面量区分开来。
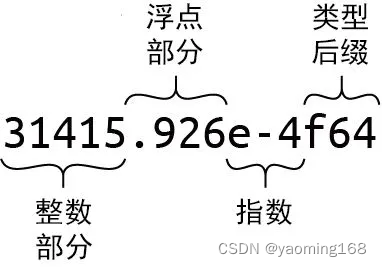
1.4 布尔
- C 和 C++ 会把字符、整数、浮点数和指针隐式转换成布尔值,因此它们可以直接用作 if 语句或 while 语句中的条件。
- Python 允许在布尔上下文中使用字符串、列表、字典甚至 Set,如果这些值是非空的,则将它们视为 true。
- Rust 非常严格:像 if 和 while 这样的控制结构要求它们的条件必须是 bool 表达式,短路逻辑运算符 && 和 || 也是如此。你必须写成 if x != 0 { … },而不能只写成 if x { … }。
尽管 bool 只需要用一个位来表示,但 Rust 在内存中会使用整字节来表示 bool 值,因此可以创建指向它的指针。
1.5 字符
Rust 的字符类型 char 会以 32 位值表示单个 Unicode 字符。Rust 会对单独的字符使用 char 类型,但对字符串和文本流使用 UTF-8 编码。因此,String 会将其文本表示为 UTF-8 字节序列,而不是字符数组。字符字面量是用单引号括起来的字符,比如 ‘8’ 或 ‘!’。还可以使用全角 Unicode 字符:’ 錆 ’ 是一个 char 字面量,表示日文汉字中的 sabi(rust)。与字节字面量一样,有些字符需要用反斜杠转义,如表所示。
| 字符 | Rust字符字面量 |
|---|---|
| 单引号(') | ‘’’ |
| 反斜杠() | ‘\’ |
| 换行(lf) | ‘\n’ |
| 回车(cr) | ‘\r’ |
| 制表(tab) | ‘\t’ |
1.6 元组
元组是各种类型值的值对或三元组、四元组、五元组等(因此称为 n- 元组或元组)。可以将元组编写为一个元素序列,用逗号隔开并包裹在一对圆括号中。例如,("Brazil", 1985) 是一个元组,其第一个元素是一个静态分配的字符串,第二个元素是一个整数,它的类型是 (&str, i32)。给定一个元组值 t,可以通过 t.0、t.1 等访问其元素。
元组有点儿类似于数组。一方面,元组的每个元素可以有不同的类型,而数组的元素必须都是相同的类型。另一方面,元组只允许用常量作为索引,比如 t.4。不能通过写成 t.i 或 t[i] 的形式来获取第 i 个元素。
Rust 代码通常会用元组类型从一个函数返回多个值。例如,字符串切片上的 split_at 方法会将字符串分成两半并返回它们,其声明如下所示:
fn split_at(&self, mid: usize) -> (&str, &str);
返回类型 (&str, &str) 是两个字符串切片构成的元组。可以用模式匹配语法将返回值的每个元素赋值给不同的变量:
let text = "I see the eigenvalue in thine eye";
let (head, tail) = text.split_at(21);
assert_eq!(head, "I see the eigenvalue ");
assert_eq!(tail, "in thine eye");
你还会看到元组被用作一种超级小巧的结构体类型。例如,在曼德博程序中,我们要将图像的宽度和高度传给绘制它的函数并将其写入磁盘。为此可以声明一个具有 width 成员和 height 成员的结构体,但对如此显而易见的事情来说,这种写法相当烦琐,所以我们只用了一个元组:
/// 把`pixels`缓冲区(其尺寸由`bounds`给出)写入名为`filename`的文件中
fn write_image(filename: &str, pixels: &[u8], bounds: (usize, usize))
-> Result<(), std::io::Error>
{ ... }
bounds 参数的类型是 (usize, usize),这是一个包含两个 usize 值的元组。当然也可以写成单独的 width 参数和 height 参数,并且最终的机器码也基本一样。但重点在于思路的清晰度。应该把大小看作一个值,而不是两个,使用元组能更准确地记述这种意图。
另一种常用的元组类型是零元组 ()。传统上,这叫作单元类型,因为此类型只有一个值,写作 ()。当无法携带任何有意义的值但其上下文仍然要求传入某种类型时,Rust 就会使用单元类型。
例如,不返回值的函数的返回类型为 ()。标准库的 std::mem::swap 函数就没有任何有意义的返回值,它只会交换两个参数的值。std::mem::swap 的声明如下所示:
fn swap<T>(x: &mut T, y: &mut T);
这个 意味着 swap 是泛型的:可以将对任意类型 T 的值的引用传给它。但此签名完全省略了 swap 的返回类型,它是以下完整写法的简写形式:
fn swap<T>(x: &mut T, y: &mut T) -> ();
类似地,前面提到过的 write_image 示例的返回类型是 Result<(), std::io::Error>,这意味着该函数在出错时会返回一个 std::io::Error 值,但成功时不会返回任何值。
如果你愿意,可以在元组的最后一个元素之后跟上一个逗号:类型 (&str, i32,) 和 (&str, i32) 是等效的,表达式 (“Brazil”, 1985,) 和 (“Brazil”, 1985) 是等效的。Rust 始终允许在所有能用逗号的地方(函数参数、数组、结构体和枚举定义,等等)添加额外的尾随逗号。这对人类读者来说可能很奇怪,不过一旦在多行列表末尾添加或移除了条目(entry),在显示差异时就会更容易阅读。
为了保持一致性,甚至有包含单个值的元组。字面量 (“lonely hearts”,) 就是一个包含单个字符串的元组,它的类型是 (&str,)。在这里,值后面的逗号是必需的,以用于区分单值元组和简单的括号表达式。
1.7 指针类型
Rust 有多种表示内存地址的类型,这是 Rust 和大多数具有垃圾回收功能的语言之间一个重大的差异。
但 Rust 不一样。该语言旨在帮你将内存分配保持在最低限度。默认情况下值会嵌套。值 ((0, 0), (1440, 900)) 会存储为 4 个相邻的整数。如果将它存储在一个局部变量中,则会得到 4 倍于整数宽度的局部变量。堆中没有分配任何内容。
这可以帮我们高效利用内存,但代价是,当 Rust 程序需要让一些值指向其他值时,必须显式使用指针类型。好消息是,当使用这些指针类型时,安全的 Rust 会对其进行约束,以消除未定义的行为。
1.7.1 引用
&String 类型的值是对 String 值的引用。
最简单的方式是将引用视为 Rust 中的基本指针类型。在运行期间,对 i32 的引用是一个保存着 i32 地址的机器字,这个地址可能位于栈或堆中。表达式 &x 会生成一个对 x 的引用,在 Rust 术语中,我们会说它借用了对 x 的引用。给定一个引用 r,表达式 *r 会引用 r 指向的值。它们非常像 C 和 C++ 中的 & 运算符和 * 运算符,并且和 C 中的指针一样,当超出作用域时引用不会自动释放任何资源。
然而,与 C 指针不同,Rust 的引用永远不会为空:在安全的 Rust 中根本没有办法生成空引用。与 C 不同,Rust 会跟踪值的所有权和生命周期,因此早在编译期间就排除了悬空指针、双重释放和指针失效等错误。
Rust 引用有两种形式。
&T
一个不可变的共享引用。你可以同时拥有多个对给定值的共享引用,但它们是只读的:禁止修改它们所指向的值,就像 C 中的 const T* 一样。
&mut T
一个可变的、独占的引用。你可以读取和修改它指向的值,就像 C 中的 T* 一样。但是只要该引用还存在,就不能对该值有任何类型的其他引用。事实上,访问该值的唯一途径就是使用这个可变引用。
Rust 利用共享引用和可变引用之间的“二选一”机制来强制执行“单个写入者或多个读取者”规则:你或者独占读写一个值,或者让任意数量的读取者共享,但二者只能选择其一。这种由编译期检查强制执行的“二选一”规则是 Rust 安全保障的核心。
1.7.2 Box
在堆中分配值的最简单方式是使用 Box::new:
let t = (12, “eggs”);
let b = Box::new(t); // 在堆中分配一个元组
t 的类型是 (i32, &str),所以 b 的类型是 Box<(i32, &str)>。对 Box::new 的调用会分配足够的内存以在堆上容纳此元组。当 b 超出作用域时,内存会立即被释放,除非 b 已被移动(move),比如返回它。移动对于 Rust 处理在堆上分配的值的方式至关重要。
1.7.3 裸指针
Rust 也有裸指针类型 *mut T 和 *const T。裸指针实际上和 C++ 中的指针很像。使用裸指针是不安全的,因为 Rust 不会跟踪它指向的内容。例如,裸指针可能为空,或者它们可能指向已释放的内存或现在包含不同类型的值。C++ 的所有经典指针错误都可能“借尸还魂”。
但是,你只能在 unsafe 块中对裸指针解引用(dereference)。unsafe 块是 Rust 高级语言特性中的可选机制,其安全性取决于你自己。如果代码中没有 unsafe 块(或者虽然有但编写正确),那么本书中强调的安全保证就仍然有效。
1.8 数组、向量和切片
Rust 用 3 种类型来表示内存中的值序列。
类型 [T; N] 表示 N 个值的数组,每个值的类型为 T。数组的大小是在编译期就已确定的常量,并且是类型的一部分,不能追加新元素或缩小数组。
类型 Vec 可称为 T 的向量,它是一个动态分配且可增长的 T 类型的值序列。向量的元素存在于堆中,因此可以随意调整向量的大小:压入新元素、追加其他向量、删除元素等。
类型 &[T] 和 &mut [T] 可称为 T 的共享切片和 T 的可变切片,它们是对一系列元素的引用,这些元素是某个其他值(比如数组或向量)的一部分。可以将切片视为指向其第一个元素的指针,以及从该点开始允许访问的元素数量的计数。可变切片 &mut [T] 允许读取元素和修改元素,但不能共享;共享切片 &[T] 允许在多个读取者之间共享访问权限,但不允许修改元素。
给定这 3 种类型中任意一种类型的值 v,表达式 v.len() 都会给出 v 中的元素数,而 v[i] 引用的是 v 的第 i 个元素。v 的第一个元素是 v[0],最后一个元素是 v[v.len() - 1]。Rust 总是会检查 i 是否在这个范围内,如果没在,则此表达式会出现 panic。v 的长度可能为 0,在这种情况下,任何对其进行索引的尝试都会出现 panic。i 的类型必须是 usize,不能使用任何其他整型作为索引。
1.8.1 数组
编写数组值的方法有好几种,其中最简单的方法是在方括号内写入一系列值:
let lazy_caterer: [u32; 6] = [1, 2, 4, 7, 11, 16];
let taxonomy = ["Animalia", "Arthropoda", "Insecta"];
assert_eq!(lazy_caterer[3], 7);
assert_eq!(taxonomy.len(), 3);
对于要填充一些值的长数组的常见情况,可以写成 [V; N],其中 V 是每个元素的值,N 是长度。例如,[true; 10000] 是一个包含 10 000 个 bool 元素的数组,其内容全为 true:
let mut sieve = [true; 10000];
for i in 2..100 {
if sieve[i] {
let mut j = i * i;
while j < 10000 {
sieve[j] = false;
j += i;
}
}
}
assert!(sieve[211]);
assert!(!sieve[9876]);
你会看到用来声明固定大小缓冲区的语法:[0u8; 1024],它是一个 1 KB 的缓冲区,用 0 填充。Rust 没有任何能定义未初始化数组的写法。(一般来说,Rust 会确保代码永远无法访问任何种类的未初始化值。)
数组的长度是其类型的一部分,并会在编译期固定下来。如果 n 是变量,则不能写成 [true; n] 以期得到一个包含 n 个元素的数组。当你需要一个长度在运行期可变的数组时(通常都是这样),请改用向量。
你在数组上看到的那些实用方法(遍历元素、搜索、排序、填充、过滤等)都是作为切片而非数组的方法提供的。但是 Rust 在搜索各种方法时会隐式地将对数组的引用转换为切片,因此可以直接在数组上调用任何切片方法:
let mut chaos = [3, 5, 4, 1, 2];
chaos.sort();
assert_eq!(chaos, [1, 2, 3, 4, 5]);
在这里,sort 方法实际上是在切片上定义的,但由于它是通过引用获取的操作目标,因此 Rust 会隐式地生成一个引用整个数组的 &mut [i32] 切片,并将其传给 sort 来进行操作。其实前面提到过的 len 方法也是切片的方法之一。
1.8.2 向量
向量 Vec< T> 是一个可调整大小的 T 类型元素的数组,它是在堆上分配的。
创建向量的方法有好几种,其中最简单的方法是使用 vec! 宏,它为我们提供了一个看起来非常像数组字面量的向量语法:
let mut primes = vec![2, 3, 5, 7];
assert_eq!(primes.iter().product::< i32 >(), 210);
当然,这仍然是一个向量,而不是数组,所以可以动态地向它添加元素:
primes.push(11);
primes.push(13);
assert_eq!(primes.iter().product::<i32>(), 30030);
还可以通过将给定值重复一定次数来构建向量,可以再次使用模仿数组字面量的语法:
fn new_pixel_buffer(rows: usize, cols: usize) -> Vec<u8> {
vec![0; rows * cols]
}
vec! 宏相当于调用 Vec::new 来创建一个新的空向量,然后将元素压入其中,这是另一种惯用法:
let mut pal = Vec::new();
pal.push("step");
pal.push("on");
pal.push("no");
pal.push("pets");
assert_eq!(pal, vec!["step", "on", "no", "pets"]);
还有一种可能性是从迭代器生成的值构建一个向量:
let v: Vec<i32> = (0..5).collect();
assert_eq!(v, [0, 1, 2, 3, 4]);
使用 collect 时,通常要指定类型(正如此处给 v 声明了类型),因为它可以构建出不同种类的集合,而不仅仅是向量。通过指定 v 的类型,我们明确表达了自己想要哪种集合。与数组一样,可以对向量使用切片的方法:
// 回文!
let mut palindrome = vec!["a man", "a plan", "a canal", "panama"];
palindrome.reverse();
// 固然合理,但不符合预期:
assert_eq!(palindrome, vec!["panama", "a canal", "a plan", "a man"]);
在这里,reverse 方法实际上是在切片上定义的,但是此调用会隐式地从此向量中借用一个 &mut [&str] 切片并在其上调用 reverse。
Vec 是 Rust 的基本数据类型,它几乎可以用在任何需要动态大小的列表的地方,所以还有许多其他方法可以构建新向量或扩展现有向量。
Vec 由 3 个值组成:指向元素在堆中分配的缓冲区(该缓冲区由 Vec 创建并拥有)的指针、缓冲区能够存储的元素数量,以及它现在实际包含的数量(也就是它的长度)。当缓冲区达到其最大容量时,往向量中添加另一个元素需要分配一个更大的缓冲区,将当前内容复制到其中,更新向量的指针和容量以指向新缓冲区,最后释放旧缓冲区。
如果事先知道向量所需的元素数量,就可以调用 Vec::with_capacity 而不是 Vec::new 来创建一个向量,它的缓冲区足够大,可以从一开始就容纳所有元素。然后,可以逐个将元素添加到此向量中,而不会导致任何重新分配。vec! 宏就使用了这样的技巧,因为它知道最终向量将包含多少个元素。请注意,这只会确定向量的初始大小,如果大小超出了你的预估,则向量仍然会正常扩大其存储空间。
许多库函数会寻求使用 Vec::with_capacity 而非 Vec::new 的机会。例如,在 collect 示例中,迭代器 0…5 预先知道它将产生 5 个值,并且 collect 函数会利用这一点以正确的容量来预分配它返回的向量。
向量的 len 方法会返回它现在包含的元素数,而 capacity 方法则会返回在不重新分配的情况下可以容纳的元素数:
let mut v = Vec::with_capacity(2);
assert_eq!(v.len(), 0);
assert_eq!(v.capacity(), 2);
v.push(1);
v.push(2);
assert_eq!(v.len(), 2);
assert_eq!(v.capacity(), 2);
v.push(3);
assert_eq!(v.len(), 3);
// 通常会打印出"capacity is now 4":
println!("capacity is now {}", v.capacity());
最后打印出的容量不能保证恰好是 4,但至少大于等于 3,因为此向量包含 3 个值。可以在向量中任意位置插入元素和移除元素,不过这些操作会将受影响位置之后的所有元素向前或向后移动,因此如果向量很长就可能很慢:
let mut v = vec![10, 20, 30, 40, 50];
// 在索引为3的元素处插入35
v.insert(3, 35);
assert_eq!(v, [10, 20, 30, 35, 40, 50]);
// 移除索引为1的元素
v.remove(1);
assert_eq!(v, [10, 30, 35, 40, 50]);
可以使用 pop 方法移除最后一个元素并将其返回。更准确地说,从 Vec 中弹出一个值会返回 Option:如果向量已经为空则为 None,如果其最后一个元素为 v 则为 Some(v)。
let mut v = vec!["Snow Puff", "Glass Gem"];
assert_eq!(v.pop(), Some("Glass Gem"));
assert_eq!(v.pop(), Some("Snow Puff"));
assert_eq!(v.pop(), None);
可以使用 for 循环遍历向量:
// 将命令行参数作为字符串的向量
let languages: Vec<String> = std::env::args().skip(1).collect();
for l in languages {
println!("{}: {}", l,
if l.len() % 2 == 0 {
"functional"
} else {
"imperative"
});
}
以编程语言列表为参数运行本程序就可以说明这个问题:
$ cargo run Lisp Scheme C C++ Fortran
1.8.3 切片
切片(写作不指定长度的 [T])是数组或向量中的一个区域。由于切片可以是任意长度,因此它不能直接存储在变量中或作为函数参数进行传递。切片总是通过引用传递。对切片的引用是一个胖指针:一个双字值,包括指向切片第一个元素的指针和切片中元素的数量。假设你运行以下代码:
let v: Vec<f64> = vec![0.0, 0.707, 1.0, 0.707];
let a: [f64; 4] = [0.0, -0.707, -1.0, -0.707];
let sv: &[f64] = &v;
let sa: &[f64] = &a;
在最后两行中,Rust 自动把 &Vec 的引用和 &[f64; 4] 的引用转换成了直接指向数据的切片引用。
最后,内存布局如图所示是内存中的向量v和数组a分别被切片sa和sv引用。
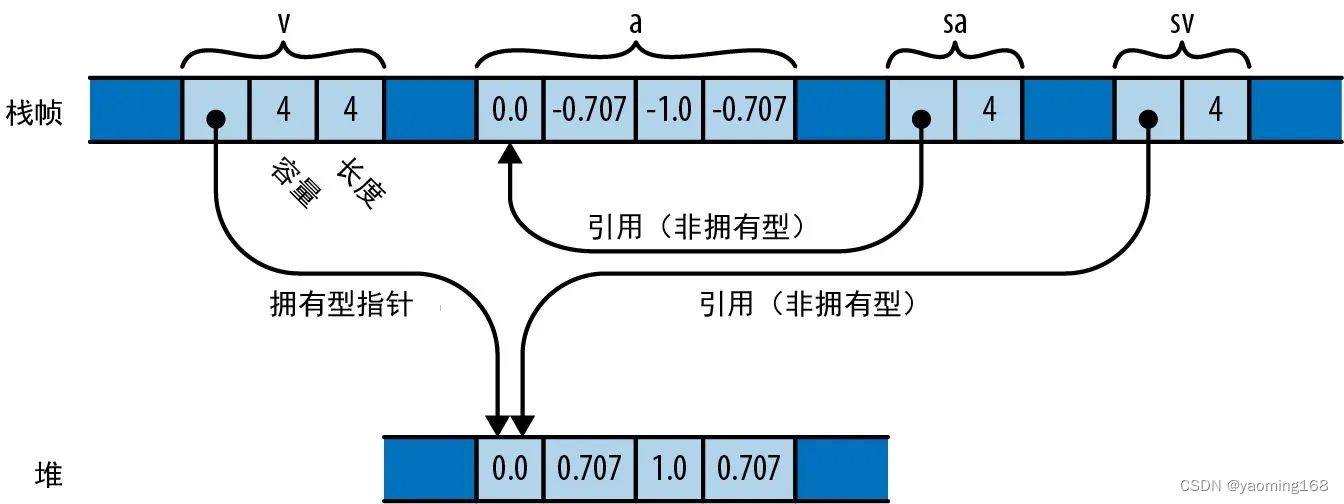
普通引用是指向单个值的非拥有型指针,而对切片的引用是指向内存中一系列连续值的非拥有型指针。如果要写一个对数组或向量进行操作的函数,那么切片引用就是不错的选择。例如,下面是打印一段数值的函数,每行一个:
fn print(n: &[f64]) {
for elt in n {
println!("{}", elt);
}
}
print(&a); // 打印数组
print(&v); // 打印向量
因为此函数以切片引用为参数,所以也可以给它传入向量或数组。事实上,你以为属于向量或数组的许多方法其实是在切片上定义的,比如会对元素序列进行排序或反转的 sort 方法和 reverse 方法实际上是切片类型 [T] 上的方法。你可以使用范围值对数组或向量进行索引,以获取一个切片的引用,该引用既可以指向数组或向量,也可以指向一个既有切片:
print(&v[0..2]); // 打印v的前两个元素
print(&a[2..]); // 打印从a[2]开始的元素
print(&sv[1..3]); // 打印v[1]和v[2]
与普通数组访问一样,Rust 会检查索引是否有效。尝试借用超出数据末尾的切片会导致 panic。
由于切片几乎总是出现在引用符号之后,因此通常只将 &[T] 或 &str 之类的类型称为“切片”,使用较短的名称来表示更常见的概念。
1.9 字符串类型
C++ 中有两种字符串类型,字符串字面量的指针类型为 const char *。标准库还提供了一个 std::string 类,用于在运行期动态创建字符串。
Rust 中也有类似的设计。
1.9.1 字符串字面量
字符串字面量要用双引号括起来,它们使用与 char 字面量相同的反斜杠转义序列:
let speech = "\"Ouch!\" said the well.\n";
但与 char 字面量不同,在字符串字面量中单引号不需要用反斜杠转义,而双引号需要。
1.9.2 字节串
带有 b 前缀的字符串字面量都是字节串。这样的字节串是 u8 值(字节)的切片而不是 Unicode 文本:
let method = b"GET";
assert_eq!(method, &[b'G', b'E', b'T']);
method 的类型是 &[u8; 3]:它是对 3 字节数组的引用,没有刚刚讨论过的任何字符串方法,最像字符串的地方就是其书写语法。
字节串可以使用前面展示过的所有其他的字符串语法:可以跨越多行、可以使用转义序列、可以使用反斜杠来连接行等。不过原始字节串要以 br" 开头。
字节串不能包含任意 Unicode 字符,它们只能使用 ASCII 和 \xHH 转义序列。
1.9.3 内存中的字符串
Rust 字符串是 Unicode 字符序列,但它们并没有以 char 数组的形式存储在内存中,而是使用了 UTF-8(一种可变宽度编码)的形式。字符串中的每个 ASCII 字符都会存储在单字节中,而其他字符会占用多字节。
下图展示了由以下代码创建的 String 值和 &str 值。
let noodles = "noodles".to_string();
let oodles = &noodles[1..];
let poodles = "ಠ_ಠ";
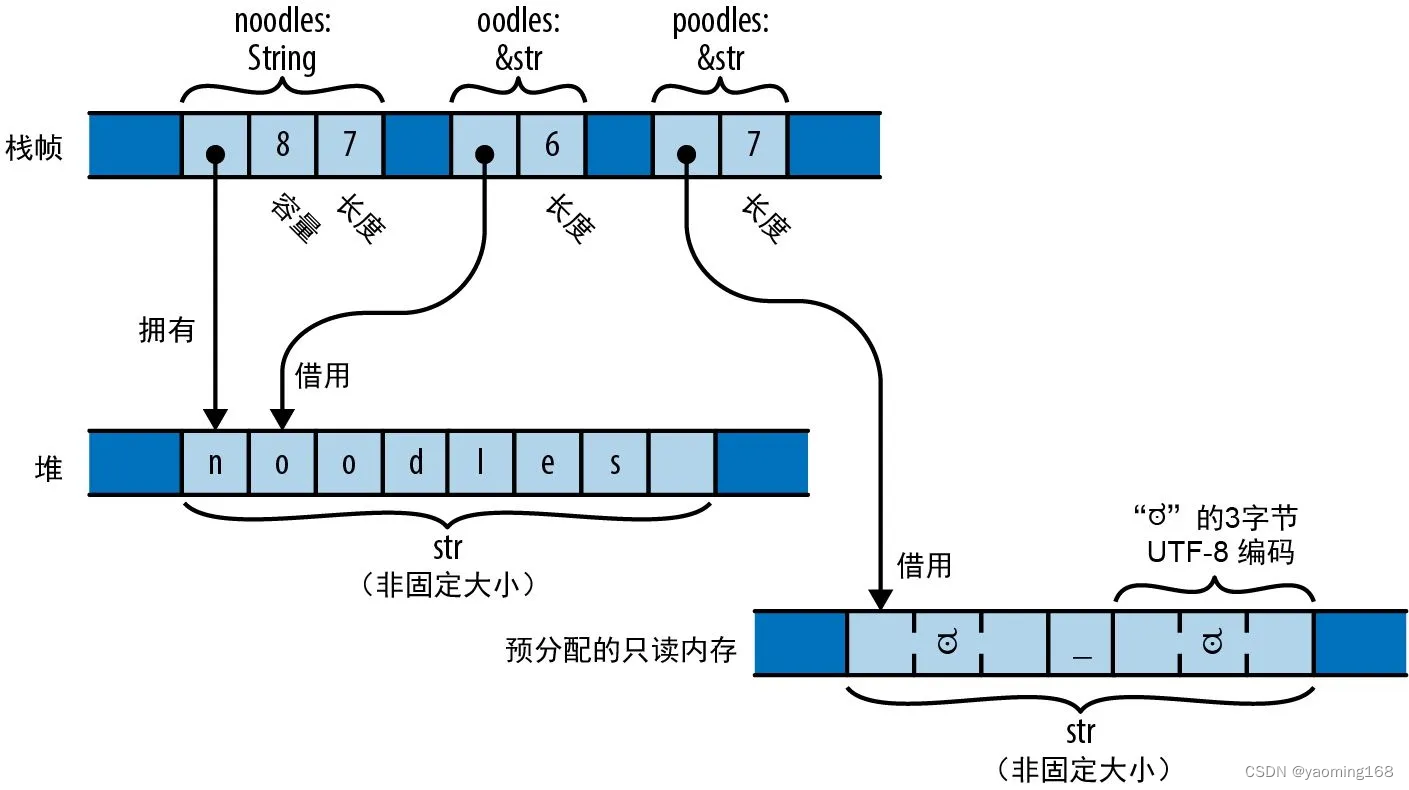
String 有一个可以调整大小的缓冲区,其中包含 UTF-8 文本。缓冲区是在堆上分配的,因此它可以根据需要或请求来调整大小。在示例中,noodles 是一个 String,它拥有一个 8 字节的缓冲区,其中 7 字节正在使用中。可以将 String 视为 Vec,它可以保证包含格式良好的 UTF-8,实际上,String 就是这样实现的。
&str(发音为 /stɜːr/ 或 string slice)是对别人拥有的一系列 UTF-8 文本的引用,即它“借用”了这个文本。在示例中,oodles 是对 noodles 拥有的文本的最后 6 字节的一个 &str 引用,因此它表示文本“oodles”。与其他切片引用一样,&str 也是一个胖指针,包含实际数据的地址及其长度。可以认为 &str 就是 &[u8],但它能保证包含的是格式良好的 UTF-8。
字符串字面量是指预分配文本的 &str,它通常与程序的机器码一起存储在只读内存区。在前面的示例中,poodles 是一个字符串字面量,指向一块 7 字节的内存,它在程序开始执行时就已创建并一直存续到程序退出。
String 或 &str 的 .len() 方法会返回其长度。这个长度以字节而不是字符为单位:
assert_eq!("ಠ_ಠ".len(), 7);
assert_eq!("ಠ_ಠ".chars().count(), 3);
不能修改 &str:
let mut s = "hello";
s[0] = 'c'; // 错误:无法修改`&str`,并给出错误原因
s.push('\n'); // 错误:`&str`引用上没有找到名为`push`的方法
要在运行期创建新字符串,可以使用 String。&mut str 类型确实存在,但它没什么用,因为对 UTF-8 的几乎所有操作都会更改其字节总长度,但切片不能重新分配其引用目标的缓冲区。事实上,&mut str 上唯一可用的操作是 make_ascii_uppercase 和 make_ascii_lowercase,根据定义,它们会就地修改文本并且只影响单字节字符。
1.9.4 String
&str 非常像 &[T],是一个指向某些数据的胖指针。而 String 则类似于 Vec, 与 Vec 一样,每个 String 都在堆上分配了自己的缓冲区,不会与任何其他 String 共享。当 String 变量超出作用域时,缓冲区将自动释放,除非这个 String 已经被移动。
以下是创建 String 的几种方法。
to_string() 方法会将 &str 转换为 String。这会复制此字符串。
let error_message = "too many pets".to_string();
to_owned() 方法会做同样的事,也会以同样的方式使用。这种命名风格也适用于另一些类型
format!() 宏的工作方式与 println!() 类似,但它会返回一个新的 String,而不是将文本写入标准输出,并且不会在末尾自动添加换行符。
assert_eq!(format!("{}°{:02}′{:02}″N", 24, 5, 23),
"24°05′23″N".to_string());
字符串的数组、切片和向量都有两个方法(.concat() 和 .join(sep)),它们会从许多字符串中形成一个新的 String。
let bits = vec!["veni", "vidi", "vici"];
assert_eq!(bits.concat(), "venividivici");
assert_eq!(bits.join(", "), "veni, vidi, vici");
有时要选择是使用 &str 类型还是使用 String 类型。这里仅指出一点:&str 可以引用任意字符串的任意切片,无论它是字符串字面量(存储在可执行文件中)还是 String(在运行期分配和释放)。这意味着如果希望允许调用者传递任何一种字符串,那么 &str 更适合作为函数参数。
2.表达式
2.1 表达式语言
在 Rust 中,if 和 match 可以生成值(类比C++语言的if和switch)。之前介绍过一个生成数值的 match 表达式:
pixels[r * bounds.0 + c] =
match escapes(Complex { re: point.0, im: point.1 }, 255) {
None => 0,
Some(count) => 255 - count as u8
};
if 表达式可用于初始化变量:
let status =
if cpu.temperature <= MAX_TEMP {
HttpStatus::Ok
} else {
HttpStatus::ServerError // 服务程序出错了
};
match 表达式可以作为参数传给函数或宏:
println!("Inside the vat, you see {}.",
match vat.contents {
Some(brain) => brain.desc(),
None => "nothing of interest"
});
为什么 Rust 没有 C 那样的三元运算符?
在 C 语言中,三元运算符是一个表达式级别的类似 if 语句的东西。这在 Rust 中是多余的:if 表达式足以处理这两种情况。C 中的大多数控制流工具是语句。而在 Rust 中,它们都是表达式。
2.2 声明
最常见的是 let 声明,它会声明局部变量:
let name: type = expr;
let 声明可以在不初始化变量的情况下声明变量,然后再用赋值语句来初始化变量。
let name;
if user.has_nickname() {
name = user.nickname();
} else {
name = generate_unique_name();
user.register(&name);
}
2.3 循环、循环中的控制流和return表达式
有 4 种循环表达式:
// 表达式1
while condition {
block
}
// 表达式2
while let pattern = expr {
block
}
// 表达式3
loop {
block
}
// 表达式4
for pattern in iterable {
block
}
各种循环都是 Rust 中的表达式,但 while 循环或 for 循环的值总是 (),因此它们的值通常没什么用。如果指定了一个值,那么 loop 表达式就能生成一个值。
while 循环的行为与 C 中的等效循环完全一样,只不过其 condition 必须是 bool 类型。
while let 循环类似于 if let。在每次循环迭代开始时,expr 的值要么匹配给定的 pattern,这时会运行循环体(block);要么不匹配,这时会退出循环。
可以用 loop 来编写无限循环。它会永远重复执行循环体(直到遇上 break 或 return,或者直到线程崩溃)。
for 循环会对可迭代(iterable)表达式求值,然后为结果迭代器中的每个值运行一次循环体。许多类型可以迭代,包括所有标准库集合,比如 Vec 和 HashMap。标准的 Rust 语言的 for 循环如下所示:
for i in 0..20 {
println!("{}", i);
}
… 运算符会生成一个范围(range),即具有两个字段(start 和 end)的简单结构体。0…20 与 std::ops::Range { start: 0, end: 20 } 相同。各种范围都可以与 for 循环一起使用,因为 Range 是一种可迭代类型,它实现了 std::iter::IntoIterator 特型。标准集合都是可迭代的,数组和切片也是如此。
为了与 Rust 的移动语义保持一致,把值用于 for 循环会消耗该值:
let strings: Vec<String> = error_messages();
for s in strings { // 在这里,每个String都会转移给s……
println!("{}", s);
} // ……并在此丢弃
println!("{} error(s)", strings.len()); // 错误:使用了已移动出去的值
2.4 为什么Rust中会有loop?
Rust 编译器中有几个部分会分析程序中的控制流。
- Rust 会检查通过函数的每条路径是否返回了预期返回类型的值。为了正确地做到这一点,它需要知道是否有可能抵达函数的末尾。
- Rust 会检查局部变量有没有在未初始化的情况下使用过。这就要检查通过函数的每一条路径,以确保只要不经过初始化此变量的代码,就无法抵达使用它的地方。
- Rust 会对不可达代码发出警告。如果无法通过函数抵达某段代码,则这段代码不可达。
要执行这种规则,语言就必须在简单性和智能性之间取得平衡。简单性使得程序员更容易弄清楚编译器到底在说什么,而智能性有助于消除假警报和编译器拒绝一份完美而安全的程序的情况。Rust 更倾向于简单性,它的流敏感分析根本不会检查循环条件,而会简单地假设程序中的任何条件都可以为真或为假。
这会导致 Rust 可能拒绝某些安全程序:
fn wait_for_process(process: &mut Process) -> i32 {
while true {
if process.wait() {
return process.exit_code();
}
}
} // 错误:类型不匹配:期待i32,实际找到了()
这里的错误是假警报。此函数只会通过 return 语句退出,因此 while 循环无法生成 i32 这个事实无关紧要。
loop 表达式就是这个问题的“有话直说”式解决方案。
Rust 的类型系统也会受到控制流的影响。前面说过,if 表达式的所有分支都必须具有相同的类型。但是,在可能以 break 或 return 表达式、无限 loop,或者调用 panic!() 或 std::process::exit() 等多种方式结束的块上强制执行此规则是不现实的。这些表达式的共同点是它们永远都不会以通常的方式结束并生成一个值。break 或 return 会突然退出当前块、无限 loop 则根本不会结束,等等。
所以,在 Rust 中,这些表达式没有正常类型。不能正常结束的表达式属于一个特殊类型 !,并且它们不受“类型必须匹配”这条规则的约束。可以在 std::process::exit() 的函数签名中看到 !:
fn exit(code: i32) -> !
此处的 ! 表示 exit() 永远不会返回,它是一个发散函数(divergent function)。
你可以用相同的语法编写自己的发散函数,这在某些情况下是很自然的:
fn serve_forever(socket: ServerSocket, handler: ServerHandler) -> ! {
socket.listen();
loop {
let s = socket.accept();
handler.handle(s);
}
}
当然,如果此函数正常返回了,那么 Rust 就会认为它能正常返回反而是一个错误。
有了这些大规模控制流的构建块,就可以继续处理该流中常用的、更细粒度的表达式(比如函数调用和算术运算符)了。
2.5 函数与方法调用
Rust 中的调用函数和方法的语法:
let x = gcd(1302, 462); // 函数调用
let room = player.location(); // 方法调用
在此处的第二个示例中,player 是虚构类型 Player 的变量,它具有虚构的 .location() 方法。
Rust 通常会在引用和它们所引用的值之间做出明确的区分。如果将 &i32 传给需要 i32 的函数,则会出现类型错误。你会注意到 . 运算符稍微放宽了这些规则。在调用 player. location() 的方法中,player 可能是一个 Player、一个 &Player 类型的引用,也可能是一个 Box 或 Rc 类型的智能指针。.location() 方法可以通过值或引用获取 player。同一个 .location() 语法适用于所有情况,因为 Rust 的 . 运算符会根据需要自动对 player 解引用或借入一个对它的引用。
第三种语法用于调用类型关联函数,比如 Vec::new():
let mut numbers = Vec::new(); // 类型关联函数调用
这些语法类似于面向对象语言中的静态方法:普通方法会在值上调用(如 my_vec.len()),类型关联函数会在类型上调用(如 Vec::new())。
Rust 语法的怪癖之一就是,在函数调用或方法调用中,泛型类型的常用语法 Vec 是不起作用的:
return Vec<i32>::with_capacity(1000); // 错误:是某种关于“链式比较”的错误消息
let ramp = (0 .. n).collect<Vec<i32>>(); // 同样的错误
这里的问题在于,在表达式中 < 是小于运算符。Rust 编译器建议用 :: 代替 。这样就解决了问题:
return Vec::<i32>::with_capacity(1000); // 正确,改用::<
let ramp = (0 .. n).collect::<Vec<i32>>(); // 正确,改用::<
符号 ::<…> 在 Rust 社区中被亲切地称为比目鱼(turbofish)。或者,通常可以删掉类型参数,让 Rust 来推断它们:
return Vec::with_capacity(10); // 正确,只要fn的返回类型是Vec<i32>
let ramp: Vec<i32> = (0 .. n).collect(); // 正确,前面已给定变量的类型
只要类型可以被推断,就省略类型,这是一种很好的代码风格。
2.6 字段与元素
你可以使用早已熟悉的语法访问结构体的字段。元组也一样,不过它们的字段是数值而不是名称:
game.black_pawns // 结构体字段
coords.1 // 元组元素
如果 . 左边的值是引用或智能指针类型,那么它就会像方法调用一样自动解引用。
方括号会访问数组、切片或向量的元素:
pieces[i] // 数组元素
方括号左侧的值也会自动解引用。
像下面这样的 3 个表达式叫作左值,因为赋值时它们可以出现在左侧:
game.black_pawns = 0x00ff0000_00000000_u64;
coords.1 = 0;
pieces[2] = Some(Piece::new(Black, Knight, coords));
当然,只有当 game、coords 和 pieces 声明为 mut 变量时才允许这样做。
从数组或向量中提取切片的写法很直观:
let second_half = &game_moves[midpoint .. end];
这里的 game_moves 可以是数组、切片或向量,无论哪种方式,结果都是已被借出的长度为 end - midpoint 的切片。在 second_half 的生命周期内,game_moves 要被视为已借出的引用。
.. 运算符允许省略任何一个操作数,它会根据存在的操作数最多生成 4 种类型的对象:
.. // RangeFull
a .. // RangeFrom { start: a }
.. b // RangeTo { end: b }
a .. b // Range { start: a, end: b }
后两种形式是排除结束值(或半开放)的:结束值不包含在所表示的范围内。例如,范围 0 … 3 包括数值 0、1 和 2,但不包括 3。
..= 运算符会生成包含结束值(或封闭)的范围,其中包括结束值:
..= b // RangeToInclusive { end: b }
a ..= b // RangeInclusive::new(a, b)
例如,范围 0 …= 3 包括数值 0、1、2 和 3。
只有包含起始值的范围才是可迭代的,因为循环必须从某处开始。但是在数组切片中,这 6 种形式都可以使用。如果省略了范围的起点或末尾,则默认为被切片数据的起点或末尾。
因此,经典的分治算法快速排序 quicksort 的实现部分看起来可能像下面这样。
fn quicksort<T: Ord>(slice: &mut [T]) {
if slice.len() <= 1 {
return; // 无可排序
}
// 把slice分成两部分:前半片和后半片
let pivot_index = partition(slice);
// 对slice的前半片递归排序
quicksort(&mut slice[.. pivot_index]);
// 对slice的后半片递归排序
quicksort(&mut slice[pivot_index + 1 ..]);
}
2.7 运算符
引用运算符
比如:地址运算符 & 和 &mut
一元 * 运算符用于访问引用所指向的值。如你所见,当使用 . 运算符访问字段或方法时,Rust 会自动追踪引用,因此只有想要读取或写入引用所指的整个值时才需要用 * 运算符。
算术运算符、按位运算符、比较运算符和逻辑运算符
Rust 有一些常用的算术运算符:+、-、*、/ 和 %。在调试构建中会检测到整数溢出并引发 panic。标准库为此提供了一些非检查(unchecked)的算术方法,比如 a.wrapping_add(b)。
整数除法会向 0 取整,而整数除以 0 会触发 panic,即使在发布构建中也是如此。标准库为整数提供了一个 a.checked_div(b) 方法,它将返回一个 Option(如果 b 为 0 则返回 None),并且不会引发 panic。
println!("{}", -100); // -100
println!("{}", -100u32); // 错误:不能在类型`u32`上使用一元`-`运算符
println!("{}", +100); // 错误:期待表达式,但发现了`+`
与在 C 中一样,a % b 会计算向 0 四舍五入的有符号余数或模数。其结果与左操作数的符号相同。注意,% 既能用于整数,也能用于浮点数:
let x = 1234.567 % 10.0; // 约等于4.567
Rust 还继承了 C 的按位整数运算符 &、|、^、<< 和 >>。但是,Rust 会使用 ! 而不是 ~ 表示按位非:
let hi: u8 = 0xe0;
let lo = !hi; // 0x1f
这意味着对于整数 n,不能用 !n 来表示“n 为 0”,而是应该写成 n == 0。
移位总是对有符号整数类型进行符号扩展,对无符号整数类型进行零扩展。由于 Rust 具有无符号整数,因此它不需要诸如 Java 的 >>> 运算符之类的无符号移位运算符。
与 C 不同,Rust 中按位运算的优先级高于比较运算,因此如果编写 x & BIT != 0,那么就意味着 (x & BIT) != 0,正如预期的那样。这比在 C 中解释成的 x & (BIT != 0) 有用得多,后者会测试错误的位。
Rust 的比较运算符是 ==、!=、<、<=、> 和 >=,参与比较的两个值必须具有相同的类型。
Rust 还有两个短路逻辑运算符 && 和 ||,它们的操作数都必须具有确切的 bool 类型。
赋值
= 运算符用于给 mut 变量及其字段或元素赋值。但是赋值在 Rust 中不像在其他语言中那么常见,因为默认情况下变量是不可变的。
Rust 支持复合赋值:
total += item.price;
Rust 也支持其他运算符:-=、*= 等。
与 C 不同,Rust 不支持链式赋值:不能编写 a = b = 3 来将值 3 同时赋给 a 和 b。赋值在 Rust 中非常罕见,
Rust 没有 C 的自增运算符 ++ 和自减运算符 --。
2.8 类型转换
在 Rust 中,将值从一种类型转换为另一种类型通常需要进行显式转换。这种转换要使用 as 关键字:
let x = 17; // x是i32类型的
let index = x as usize; // 转换成usize
Rust 允许进行好几种类型的转换。
- 数值可以从任意内置数值类型转换为其他内置数值类型。
- bool 类型或 char 类型的值或者类似 C 的 enum 类型的值可以转换为任何整数类型。
我们说过通常需要进行强制转换。但一些涉及引用类型的转换非常直观,Rust 甚至无须强制转换就能执行它们。一个简单的例子是将可变引用转换为不可变引用。
不过,还可能会发生几个更重要的自动转换。
- &String 类型的值会自动转换为 &str 类型,无须强制转换。
- &Vec 类型的值会自动转换为 &[i32]。
- &Box 类型的值会自动转换为 &Chessboard。
这些称为隐式解引用,因为它们适用于所有实现了内置特型 Deref 的类型。Deref 隐式转换的目的是使智能指针类型(如 Box)的行为尽可能像其底层值。多亏了 Deref,Box 的用法基本上和普通 Chessboard 的用法一样。
用户定义类型也可以实现 Deref 特型,当你需要编写自己的智能指针类型时.
2.9 闭包
Rust 也有闭包(轻量级的类似函数的值)。闭包通常由一个参数列表组成,在两条竖线之间列出,后跟一个表达式:
let is_even = |x| x % 2 == 0;
Rust 会推断其参数类型和返回类型。你也可以像写函数一样显式地写出它们。如果确实指定了返回类型,那么为了语法的完整性,闭包的主体必须是一个块:
let is_even = |x: u64| -> bool { x % 2 == 0 };
调用闭包和调用函数的语法是一样的:
assert_eq!(is_even(14), true);















 5924
5924











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









