










[NOIP2020] 字符串匹配
题目描述
小 C 学习完了字符串匹配的相关内容,现在他正在做一道习题。
对于一个字符串 S S S,题目要求他找到 S S S 的所有具有下列形式的拆分方案数:
S = A B C S = ABC S=ABC, S = A B A B C S = ABABC S=ABABC, S = A B A B … A B C S = ABAB \ldots ABC S=ABAB…ABC,其中 A A A, B B B, C C C 均是非空字符串,且 A A A 中出现奇数次的字符数量不超过 C C C 中出现奇数次的字符数量。
更具体地,我们可以定义 A B AB AB 表示两个字符串 A A A, B B B 相连接,例如 A = aab A = \texttt{aab} A=aab, B = ab B = \texttt{ab} B=ab,则 A B = aabab AB = \texttt{aabab} AB=aabab。
并递归地定义 A 1 = A A^1=A A1=A, A n = A n − 1 A A^n = A^{n - 1} A An=An−1A( n ≥ 2 n \ge 2 n≥2 且为正整数)。例如 A = abb A = \texttt{abb} A=abb,则 A 3 = abbabbabb A^3=\texttt{abbabbabb} A3=abbabbabb。
则小 C 的习题是求 S = ( A B ) i C S = {(AB)}^iC S=(AB)iC 的方案数,其中 F ( A ) ≤ F ( C ) F(A) \le F(C) F(A)≤F(C), F ( S ) F(S) F(S) 表示字符串 S S S 中出现奇数次的字符的数量。两种方案不同当且仅当拆分出的 A A A、 B B B、 C C C 中有至少一个字符串不同。
小 C 并不会做这道题,只好向你求助,请你帮帮他。
输入格式
本题有多组数据,输入文件第一行一个正整数 T T T 表示数据组数。
每组数据仅一行一个字符串 S S S,意义见题目描述。 S S S 仅由英文小写字母构成。
输出格式
对于每组数据输出一行一个整数表示答案。
样例 #1
样例输入 #1
3
nnrnnr
zzzaab
mmlmmlo
样例输出 #1
8
9
16
样例 #2
样例输入 #2
5
kkkkkkkkkkkkkkkkkkkk
lllllllllllllrrlllrr
cccccccccccccxcxxxcc
ccccccccccccccaababa
ggggggggggggggbaabab
样例输出 #2
156
138
138
147
194
样例 #3
样例输入 #3
见附件中的 string/string3.in
样例输出 #3
见附件中的 string/string3.ans
样例 #4
样例输入 #4
见附件中的 string/string4.in
样例输出 #4
见附件中的 string/string4.ans
提示
【样例 #1 解释】
对于第一组数据,所有的方案为
- A = n A=\texttt{n} A=n, B = nr B=\texttt{nr} B=nr, C = nnr C=\texttt{nnr} C=nnr。
- A = n A=\texttt{n} A=n, B = nrn B=\texttt{nrn} B=nrn, C = nr C=\texttt{nr} C=nr。
- A = n A=\texttt{n} A=n, B = nrnn B=\texttt{nrnn} B=nrnn, C = r C=\texttt{r} C=r。
- A = nn A=\texttt{nn} A=nn, B = r B=\texttt{r} B=r, C = nnr C=\texttt{nnr} C=nnr。
- A = nn A=\texttt{nn} A=nn, B = rn B=\texttt{rn} B=rn, C = nr C=\texttt{nr} C=nr。
- A = nn A=\texttt{nn} A=nn, B = rnn B=\texttt{rnn} B=rnn, C = r C=\texttt{r} C=r。
- A = nnr A=\texttt{nnr} A=nnr, B = n B=\texttt{n} B=n, C = nr C=\texttt{nr} C=nr。
- A = nnr A=\texttt{nnr} A=nnr, B = nn B=\texttt{nn} B=nn, C = r C=\texttt{r} C=r。
【数据范围】
| 测试点编号 | ∣ S ∣ ≤ \lvert S \rvert \le ∣S∣≤ | 特殊性质 |
|---|---|---|
| 1 ∼ 4 1 \sim 4 1∼4 | 10 10 10 | 无 |
| 5 ∼ 8 5 \sim 8 5∼8 | 100 100 100 | 无 |
| 9 ∼ 12 9 \sim 12 9∼12 | 1000 1000 1000 | 无 |
| 13 ∼ 14 13 \sim 14 13∼14 | 2 15 2^{15} 215 | S S S 中只包含一种字符 |
| 15 ∼ 17 15 \sim 17 15∼17 | 2 16 2^{16} 216 | S S S 中只包含两种字符 |
| 18 ∼ 21 18 \sim 21 18∼21 | 2 17 2^{17} 217 | 无 |
| 22 ∼ 25 22 \sim 25 22∼25 | 2 20 2^{20} 220 | 无 |
对于所有测试点,保证 1 ≤ T ≤ 5 1 \le T \le 5 1≤T≤5, 1 ≤ ∣ S ∣ ≤ 2 20 1 \le |S| \le 2^{20} 1≤∣S∣≤220。
我有个梦想,我想写一篇多图的,讲解细的,注释多的,O(nlog26)O(nlog26)O(nlog26)复杂度的题解。
前置知识
- 树状数组 这个相信能参加NOIP的同学都会。
- 扩展KMP算法 模板题:P5410 【模板】扩展 KMP(Z 函数) 这道题我也写了题解,欢迎评论点赞围观。这道模板题是紫色的,其实一点也不难,我觉得难度有点虚标了,相信你看了我的题解很快就可以学会的。
如果你不会扩展KMP算法,其实也不影响你阅读本文,只需知道这个算法提供了一个z函数的计算方式。
不妨设输入的字符串是sss,下标从000开始,长度是nnn。用s[i,j]s[i,j]s[i,j]表示sss中从下标iii位置到下标jjj位置的子串,包括iii和jjj。那么z[i]z[i]z[i]表示s[i,n−1]s[i,n-1]s[i,n−1]与sss本身的最长公共前缀的长度。
比如z[0]z[0]z[0]表示sss与sss的公共子串的长度,那么z[0]=nz[0]=nz[0]=n
z[1]z[1]z[1]表示sss去掉开头第一个字符以后,和自己的最长公共前缀的长度,依次类推。扩展KMP算法可以在O(n)O(n)O(n)时间内求出zzz数组的所有位置。
枚举循环节长度
先不考虑题中的出现奇数次这个条件。先考虑把sss拆成(AB)kC(AB)^kC(AB)kC的方案数,其中ABABAB合起来是一个循环节,我们先考虑一个循环节有多长。
不妨设循环节长度为iii,第一个发现是,只要满足2≤i≤n−12 \leq i \leq n-12≤i≤n−1都可以。因为AAA和BBB都不能为空,所以循环节长度至少是222。循环节长度最多是n−1n-1n−1,因为CCC也不能为空。
当循环节长度是iii的时候,至少kkk可以取到111,就是只循环一次,后面剩下的都给CCC。除此之外,k还可以取多少呢?不妨以i=3i=3i=3为例,画一个图看看

假设z[3]=7z[3]=7z[3]=7,也就是说,字符串从333位置开始,连续777个长度的子串,和字符串刚开头的777个字符相等。那么我们把sss再画一遍,去掉前333个位置,抄在下面,如图所示,那么画蓝线的部分是相等的。
现在考虑长度为333的循环节,首先红色的333个位置,和下面橙色的三个位置肯定是相等的,因为它们都是蓝线部分开头的333个。而橙色的部分上下是对应相等的,于是红色和橙色相等。
同理,由于橙色和绿色相等,那么红,橙,绿都相等,也就是说长度为3的循环节,至少可以循环3次。这里可以看出,蓝线的长度,除以循环节的长度再加1,就可以算出来最多可以循环几次,如果不能整除,向下取整。这个例子里面就是⌊7/3⌋+1\lfloor 7/3 \rfloor +1⌊7/3⌋+1,那么kkk可以取333种。
那么第一个结论就出来了,枚举一下循环节的长度i,总的方案数就是
⌊z[i]i⌋+1\lfloor \frac{z[i]}{i} \rfloor +1 ⌊iz[i]⌋+1
之和。
考虑字符出现的次数
题目中还有一个条件我们没有考虑,为了说话方便,我们定义f(i,j)f(i,j)f(i,j)表示s[i,j]s[i,j]s[i,j]中出现奇数次的字符的个数。
假设现在枚举到循环节长度为iii,此时根据前面的结论,我们算出来kkk的方案数有ttt种。其中一半kkk是奇数,一半kkk是偶数。当然奇数可能比偶数多一个。不妨设kkk是奇数的取值方案数是tjtjtj,那么有tj=t−t/2tj = t-t/2tj=t−t/2,同理设偶数的kkk的个数是tototo,有to=t/2to = t/2to=t/2
考虑kkk的取值。如果kkk的值是奇数:
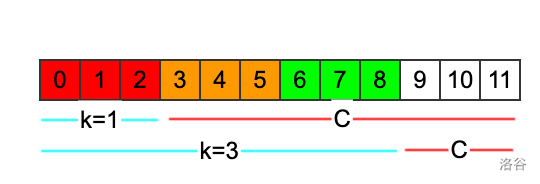
如图所示,k=1k=1k=1时候,CCC的长度是从iii开头的后缀的长度。k=3k=3k=3的时候,CCC是更短的红线表示的范围。这两种情况下,CCC当中出现次数为奇数的字符的个数是一样多的,因为如果循环节多出现了两次,相当于循环节里面的每个字符都出现了偶数次,不影响CCC当中出现次数为奇数次的字符的个数。
所以,当kkk是奇数的时候,我们只需计算出来,以iii为开头的后缀当中出现奇数次的字符的个数就行了。然后在长度为i的子串的前缀s[0,j]s[0,j]s[0,j]当中,找出来满足:
f(0,j)≤f(i,n−1)f(0,j) \leq f(i,n-1) f(0,j)≤f(i,n−1)
的jjj的个数,记为t1t1t1。而对于每个合法的jjj,我们发现,只要是奇数的kkk,都可以是一种合法方案,所以这里要乘法原理一下,把t1t1t1和tjtjtj的个数相乘。
再来考虑k是偶数的情况。
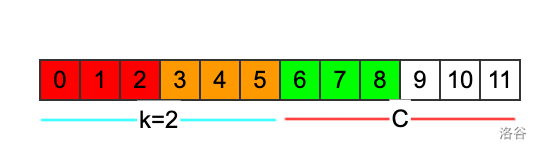
跟前面情况类似,当k是偶数的时候,后缀C里面的只出现奇数次的字符的个数,和整个串里面只出现奇数次的字符个数是相等的。在长度为i的子串的前缀s[0,j]s[0,j]s[0,j]当中,找出来满足:
f(0,j)≤f(0,n−1)f(0,j) \leq f(0,n-1) f(0,j)≤f(0,n−1)
的jjj的个数,记为t2t2t2。那么这种情况下的方案数,就是t2t2t2和tototo相乘。
具体实现
首先前面的算法中用到了f(0,n−1)f(0,n-1)f(0,n−1),这个好办,直接预处理算出来就行了。
在从左往右扫字符串sss的过程中,假设我们目前枚举到位置iii,此时我们计算循环节长度为i+1i+1i+1的情况,此时AAA最远可以取到i−1i-1i−1位置,把iii位置留着给BBB,保证BBB不为空。我们可以用一个桶,维护i+1i+1i+1开头的后缀里面每个字母出现的次数,当iii向右循环的时候,每次只改一个字符,所以在桶的对应位置减111,然后看看出现奇数次的字符数量如何变化就行了。
不妨设这个桶叫afterafterafter,一共有262626个格,分别表示每个字符出现的次数。起始的时候,先扫一遍s,把整个字符串都统计一遍,这时候可以顺手求出整个串里面只出现奇数次的字符的个数,记到allallall变量里面。然后当后面循环的时候,循环到iii位置,就把after[s[i]−′a′]after[s[i]-'a']after[s[i]−′a′]位置减111。设变量sufsufsuf表示f[i+1,n−1]f[i+1,n-1]f[i+1,n−1],如果在after[s[i]−′a′]after[s[i]-'a']after[s[i]−′a′]减1之前,sufsufsuf是奇数,那么减完以后,后缀里面的奇数就会少一个,那么sufsufsuf减111,否则sufsufsuf加一。这样每次iii移动,sufsufsuf都可以O(1)O(1)O(1)维护。
那么循环节里面的每个前缀中出现奇数次的字符个数,可以放到一个树状数组里面,这样这个树状数组一共有262626个位置,每个位置ppp保存出现奇数次的字符有ppp个的前缀有多少个。iii每向右循环111位,就在计算完结果以后,把当前前缀扔到树状数组里面。
其他细节可以参考代码
代码时间
#include <iostream>
#include <cstdio>
#include <cstring>
using namespace std;
const int MAXN = (1 << 20) + 5;
char s[MAXN];//输入的字符串
int n, z[MAXN];//字符串长度,以及z函数的值
int before[30], after[30];//两个桶,分别统计当前枚举到的位置左侧和右侧每个字符出现的频次
int pre, suf, all;//当前枚举到的位置的前缀、后缀、整个串里面出现奇数次的字符的个数
//树状数组,对于s的某个前缀si,如果它里面出现奇数次的字符有m个,则在树状数组m+1位置+1
int c[30];
inline int lbt(int x) {
return x & -x;
}
void update(int x) {
while (x <= 27) {
c[x]++;
x += lbt(x);
}
}
int sum(int x) {
int r = 0;
while (x > 0) {
r += c[x];
x -= lbt(x);
}
return r;
}
//扩展KMP算法,计算z函数的值
//可以参考良心博客 https://www.luogu.com.cn/blog/nitubenben/solution-p5410
void Z() {
z[0] = n;
int now = 0;
while (now + 1 < n && s[now] == s[now + 1]) {
now++;
}
z[1] = now;
int p0 = 1;
for (int i = 2; i < n; ++i) {
if (i + z[i - p0] < p0 + z[p0]) {
z[i] = z[i - p0];
} else {
now = p0 + z[p0] - i;
now = max(now, 0);
while (now + i < n && s[now] == s[now + i]) {
now++;
}
z[i] = now;
p0 = i;
}
}
}
int main() {
int T;
cin >> T;
while (T--) {
cin >> s;
n = strlen(s);
memset(before, 0, sizeof(before));
memset(after, 0, sizeof(after));
memset(c, 0, sizeof(c));
all = pre = suf = 0;
Z();
//如果发现循环节可以到结尾,减1,空至少一个位置给C
for (int i = 0; i < n; ++i) {
if (i + z[i] == n) z[i]--;
}
//先把字符串过一遍,频次统计到after数组里面
for (int i = 0; i < n; ++i) {
after[s[i] - 'a']++;
}
//扫一下每个字母,计算整个串中出现奇数次的字符的个数
for (int i = 0; i < 26; ++i) {
if (after[i] & 1) {
all++;
}
}
suf = all;//后缀中的值暂时和整个串一致
long long ans = 0;
for (int i = 0; i < n; ++i) {
//再扫一次字符串,当循环到i位置的时候,循环节长度是i+1
//s[i]要从右边去掉,维护after数组和suf变量
if (after[s[i] - 'a'] & 1) {
//之前是奇数,现在变成偶数了
suf--;
} else {
suf++;
}
after[s[i] - 'a']--;
//s[i]加到左边,维护before和pre变量
if (before[s[i] - 'a'] & 1) {
pre--;
} else {
pre++;
}
before[s[i] - 'a']++;
if (i != 0 && i != n - 1) {
//循环节大于1,才能对答案有贡献,因为题中说ABC都不为空
int t = z[i + 1] / (i + 1) + 1;
ans += 1LL * (t / 2) * sum(all + 1) + 1LL * (t - t / 2) * sum(suf + 1);
}
update(pre + 1);
}
cout << ans << endl;
}
return 0;
}
















 493
493











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











