






1默认你已经安装好Python环境
2安装scrapy
pip install Scrapy3进入工作空间目录,在地址栏敲cmd,执行命令,创建项目
scrapy startproject Baijiaxing4使用PyCharm打开项目,你也可以使用其他编码工具
目录结构如下

6 进入项目目录
cd Baijiaxing5在spider下创建我们自己的爬虫程序 baijiaxing
scrapy genspider baijiaxing baijiaxing.51240.com后面就是我们要爬的网址
6目录如下,新增一个baijiaxing.py文件

8新建目录data,用于存储爬取数据的文件

7编写items.py
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class BaijiaxingItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
baijiaxing = scrapy.Field()
pass
8编写settings.py
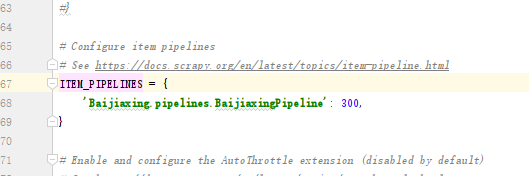
9编写pipelines.py
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
import codecs
import json
class BaijiaxingPipeline(object):
def __init__(self):
self.file = codecs.open('data/baijiaxing.json', 'w', encoding='utf-8')
def process_item(self, item, spider):
line = json.dumps(dict(item))
self.file.write(line.decode("unicode_escape"))
return item
10编写baijiaxing.py
# -*- coding: utf-8 -*-
from scrapy.spiders import Spider
from scrapy.selector import Selector
from scrapy.http import HtmlResponse
from Baijiaxing.items import BaijiaxingItem
import requests
import re
import json
class BaijiaxingSpider(Spider):
name = 'baijiaxing'
allowed_domains = ['baijiaxing.51240.com']
start_urls = ['http://baijiaxing.51240.com']
def __init__(self):
self.site_domain = 'https://baijiaxing.51240.com/'
self.items = []
self.item = BaijiaxingItem()
self.numb = 0
def parse(self, response):
print(type(response))
sel = Selector(response)
sites1 = sel.xpath('//body//div[@class="kuang"]//span[@class="asdasd1"]/a')
print(len(sites1))
for site in sites1:
topic = site.xpath('text()').extract()
print(len(topic))
print("topic end")
for top in topic:
print("top start")
print(top)
itemi = {}
itemi['name'] = top
url = site.xpath('@href').extract()[0]
itemi['url'] = self.site_domain + url.encode('utf-8')
self.handle_detail(itemi['url'], itemi)
self.items.append(itemi)
self.item['baijiaxing'] = self.items
return self.items
def handle_detail(self, response, itemi):
print(response)
response = response.strip()
html_requests_item = requests.get(response)
html_requests = html_requests_item.text.encode('utf-8')
html_response = HtmlResponse(url=response, body=html_requests, headers={'Connection': 'close'})
html_all = Selector(html_response)
print(json.dumps(itemi, encoding="UTF-8", ensure_ascii=False))
itemi['from'] = html_all.xpath('//body//div[@class="kuang"]//div[@class="neirong"]/text()').extract()
item_list_temp = []
for item_list in itemi['from']:
temp = item_list.encode('utf-8')
temp = re.sub(r'\"', "“", temp)
temp = re.sub(r'\n', "", temp)
temp = re.sub(r'\r', "", temp)
temp = re.sub(r'\t', "", temp)
item_list_temp.append(temp)
itemi['from'] = item_list_temp10运行执行命令
scrapy crawl baijiaxing11输入结果如下
![]()
源码已上传github















 1191
1191











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









