






关系型数据库为了规范性,把数据分配成为最小的逻辑表来存储避免重复,获得精简的空间利用。.但是多个表之间的关系限制,多表管理就有点复杂。. 当然精简的存储可以节约宝贵的数据存储,但是现在随着社会的发展,磁盘上付出的代价是微不足知道的。. 非关系型是平面数据集合中,数据经常可以重复,单个数据库很少被分开,而是存储成为一个整体,这种整块读取数据效率更高。----知乎
| 名称 | 关系型数据库 | 非关系型数据库NOSQL |
| 含义 | 关系型数据库指的是使用关系模型(二维表格模型)来组织数据的数据库。 关系模型可以简单理解为二维表格模型,而一个关系型数据库就是由二维表及其之间的关系组成的一个数据组织。 | 非关系型数据库又被称为 NoSQL(Not Only SQL ),意为不仅仅是 SQL。通常指数据以对象的形式存储在数据库中,而对象之间的关系通过每个对象自身的属性来决定,常用于存储非结构化的数据。 |
| 数据结构 | 二维表格模型 | 键值,列族,文档,图形 |
| 例如 |
|
|
| 优势 | 1.二维表结构。和开发逻辑吻合,便于理解 2、支持通用的结构化查询语句(SQL) 3.丰富的完整性减少数据冗余和数据不一致,全部由表结构组成,文件格式一致 4.可以用SQL进行多表连接进行查询 5.提供对事务的支持,能够保证系统中事务的正确执行,同时提供事务的恢复、回滚、并发控制和死锁问题的解决。 6.数据存储在磁盘中,安全可靠 | 1.非关系型数据库存储格式可以是 key-value形式,文档形式,图片形式等,使用灵活,应用场景广泛,而关系型数据库只支持基础类型 2.速度快,效率高,NoSQL可以使用硬盘或随机存储器作为载体,而关系型数据库只能使用硬盘 3.低成本,简易的处理和维护海量数据 4.拓展简单,高并发,高稳定性,成本低廉 5.可以实现数据的分布式处理 |
| 劣势 | 1.不足以应付海量数据 2.高并发读写能力差:网站类用户的并发性访问非常高,而一台数据库的最大连接数有限,且磁盘的I/O有限,不能满足多人同时连接 3.可拓展性不足,不能像web server 和app server那样添加硬件和服务节点来拓展性能和负荷工作能力。 4.数据模式灵活性高:数据模式定义严格,无法快速容纳新的数据类型(需要提前知道需要存储什么样类型的数据) | 1.不提供SQL支持,学习和使用成本高 2.非关系数据库费油事务处理,无法保证数据的完整性和安全性,适合处理海量数据,但不一定安全。 3.功能没有关系型数据库完善 4.复杂表的关联查询不容易实现 |
非关系型数据库分类:


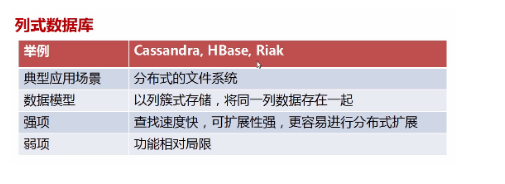
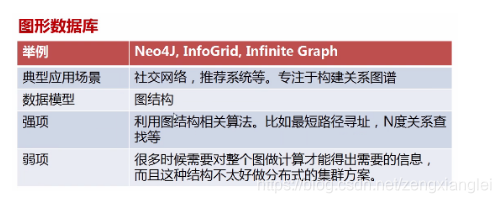
详解Clickhouse:
1.列式数据库存储系统,除数据本身外不存在其他额外的数据。--为了避main在值旁边存储他们的长度,必须支持固定长度数值类型。例如 10亿个UInt8类型的数据在未压缩的情况下大约消耗1GB左右的空间。
Click是一个数据库管理系统,允许在运行时创建表和数据库,加载数据和运行查询,而无需重新配置或重启服务。
2.数据压缩,(1)在磁盘空间和CPU消耗之间进行不同权衡的高效通用压缩编解码器(2)在磁盘空间和CPU消耗之间进行不同权衡的高效通用压缩编解码器
3.数据磁盘存储:ClickHouse被设计用于工作在传统磁盘上的系统,它提供每GB更低的存储成本,但如果可以使用SSD和内存,它也会合理的利用这些资源。
4.多核心并行处理:ClickHouse会使用服务器上一切可用的资源,从而以最自然的方式并行处理大型查询。
5.多服务器分布式处理:数据可以保存在不同的shard上,每一个shard都由一组用于容错的replica组成,查询可以并行地在所有shard上进行处理。这些对用户来说是透明的
6.支持SQL:支持一种基于SQL的声明式查询语言,它在许多情况下与ANSI SQL标准相同。支持的查询GROUP BY, ORDER BY, FROM, JOIN, IN以及非相关子查询。相关(依赖性)子查询和窗口函数暂不受支持,但将来会被实现。
7.向量引擎:为了高效的使用CPU,数据不仅仅按列存储,同时还按向量(列的一部分)进行处理,这样可以更加高效地使用CPU。
8.实时数据跟新:ClickHouse支持在表中定义主键。为了使查询能够快速在主键中进行范围查找,数据总是以增量的方式有序的存储在MergeTree中。因此,数据可以持续不断地高效的写入到表中,并且写入的过程中不会存在任何加锁的行为。
9.索引:按照主键对数据进行排序,这将帮助ClickHouse在几十毫秒以内完成对数据特定值或范围的查找。
10.适合在线查询:在线查询意味着在没有对数据做任何预处理的情况下以极低的延迟处理查询并将结果加载到用户的页面中。
11.支持近似计算:
ClickHouse提供各种各样在允许牺牲数据精度的情况下对查询进行加速的方法:
- 用于近似计算的各类聚合函数,如:distinct values, medians, quantiles
- 基于数据的部分样本进行近似查询。这时,仅会从磁盘检索少部分比例的数据。
- 不使用全部的聚合条件,通过随机选择有限个数据聚合条件进行聚合。这在数据聚合条件满足某些分布条件下,在提供相当准确的聚合结果的同时降低了计算资源的使用。
12.多表连接:ClickHouse支持自定义JOIN多个表,它更倾向于散列连接算法,如果有多个大表,则使用合并-连接算法
13:支持数据复制与数据完整性:ClickHouse使用异步的多主复制技术。当数据被写入任何一个可用副本后,系统会在后台将数据分发给其他副本,以保证系统在不同副本上保持相同的数据。在大多数情况下ClickHouse能在故障后自动恢复,在一些少数的复杂情况下需要手动恢复。
14.角色访问控制:ClickHouse使用SQL查询实现用户帐户管理,并允许角色的访问控制,类似于ANSI SQL标准和流行的关系数据库管理系统。
限制:
- 没有完整的事务支持。
- 缺少高频率,低延迟的修改或删除已存在数据的能力。仅能用于批量删除或修改数据,但这符合 GDPR。
- 稀疏索引使得ClickHouse不适合通过其键检索单行的点查询。
参考文章:
非关系型非关系型数据库(NOSQL)和关系型数据库(SQL)区别详解 - 腾讯云开发者社区-腾讯云 (tencent.com)非关系型(20条消息) 关系型数据库和非关系型数据库的区别_zengxianglei的博客-CSDN博客_关系型数据库和非关系型区别















 784
784











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









