






在编写 Python 项目的时候,我们经常会遇到导入模块失败的错误:
ImportError: No module named 'xxx'或者ModuleNotFoundError: No module named 'xxx'
导入失败,通常分为两种:一种是导入自己写的模块(即以 .py 为后缀的文件),另一种是导入三方库。本文主要讨论第二种情况。
解决导入 Python 库失败的问题,其实关键是在运行环境中装上缺失的库(注意是否是虚拟环境),或者使用恰当的替代方案。这个问题又分为三种情况:
一、单个模块中缺失的库
在编写代码的时候,如果我们需要使用某个三方库(如 requests),但不确定实际运行的环境是否装了它,那么可以这样:
try:
import requests
except ImportError:
import os
os.system('pip install requests')
import requests这样写的效果是,如果找不到 requests 库,就先安装,再导入。
在某些开源项目中,我们可能还会看到如下的写法(以 json 为例):
try:
import simplejson as json
except ImportError:
import json这样写的效果是,优先导入三方库 simplejson,如果找不到,那就使用内置的标准库 json。
这种写法的好处是不需要导入额外的库,但它有个缺点,即需要保证那两个库在使用上是兼容的,如果在标准库中找不到替代的库,那就不可行了。
如果真找不到兼容的标准库,也可以自己写一个模块(如 my_json.py),实现想要的东西,然后在 except 语句中导入它。
try:
import simplejson as json
except ImportError:
import my_json as json
二、整个项目中缺失的库
以上的思路是针对开发中的项目,但是它有几个不足:
- 在代码中对每个可能缺失的三方库都 pip install,并不可取;
- 某个三方库无法被标准库或自己手写的库替代,该怎么办?
- 已成型的项目,不允许做这些修改怎么办?
所以这里的问题是:有一个项目,想要部署到新的机器上,它涉及很多三方库,但是机器上都没有预装,该怎么办?
对于一个合规的项目,按照约定,通常它会包含一个“requirements.txt ”文件,记录了该项目的所有依赖库及其所需的版本号。这是在项目发布前,使用命令pip freeze > requirements.txt 生成的。
使用命令 pip install -r requirements.txt (在该文件所在目录执行,或在命令中写全文件的路径),就能自动把所有的依赖库给装上。
但是,如果项目不合规,或者由于其它倒霉的原因,我们没有这样的文件,又该如何是好?
一个笨方法就是,把项目跑起来,等它出错,遇到一个导库失败,就手动装一个,然后再跑一遍项目,遇到导库失败就装一下,如此循环……
三、自动导入任意缺失的库
有没有一种更好的可以自动导入缺失的库的方法呢?
在不修改原有的代码的情况下,在不需要“requirements.txt”文件的情况下,有没有办法自动导入所需要的库呢?
当然有!先看看效果:
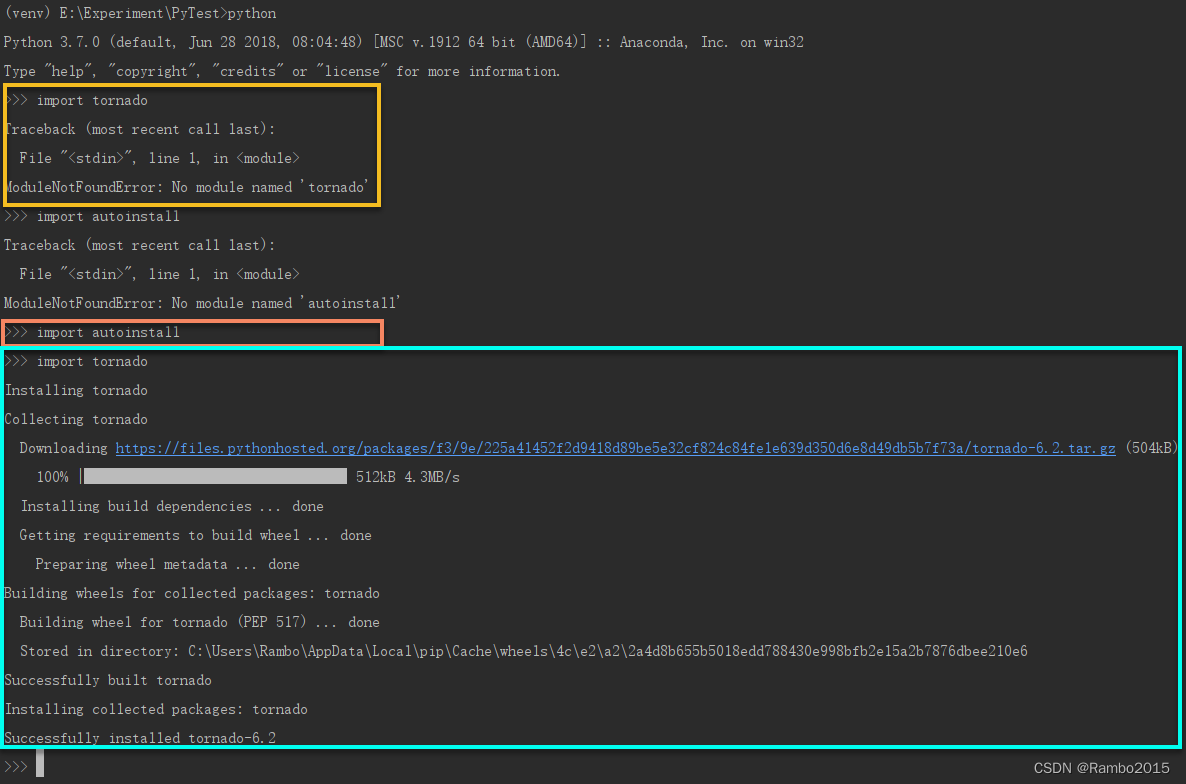
我们以 tornado 为例,第一步操作可看出,我们没有装过 tornado,经过第二步操作后,再次导入 tornado 时,程序会帮我们自动下载并安装好 tornado,所以不再报错。
autoinstall 是我们手写的模块,代码如下:
# 以下代码在 python 3.7.0 版本验证通过
import sys
import os
from importlib import import_module
class AutoInstall():
_loaded = set()
@classmethod
def find_spec(cls, name, path, target=None):
if path is None and name not in cls._loaded:
cls._loaded.add(name)
print("Installing", name)
try:
result = os.system('pip install {}'.format(name))
if result == 0:
return import_module(name)
except Exception as e:
print("Failed", e)
return None
sys.meta_path.append(AutoInstall)
这段代码中使用了sys.meta_path ,我们先打印一下,看看它是个什么东西?

Python 3 的 import 机制在查找过程中,大致顺序如下:
-
在 sys.modules 中查找,它缓存了所有已导入的模块
-
在 sys.meta_path 中查找,它支持自定义的加载器
-
在 sys.path 中查找,它记录了一些库所在的目录名
-
若未找到,抛出
ImportError异常
其中要注意,sys.meta_path 在不同的 Python 版本中有所差异,比如它在 Python 2 与 Python 3 中差异很大;在较新的 Python 3 版本(3.4+)中,自定义的加载器需要实现find_spec方法,而早期的版本用的则是find_module。
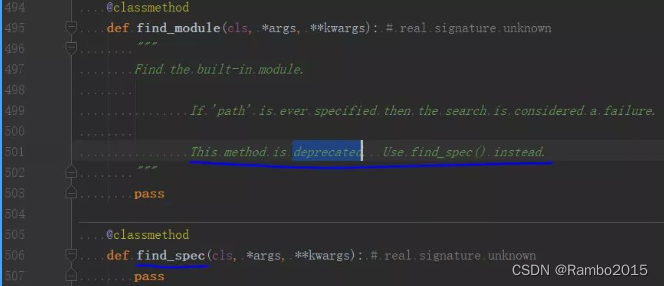
以上代码是一个自定义的类库加载器 AutoInstall,可以实现自动导入三方库的目的。需要说明一下,这种方法会“劫持”所有新导入的库,破坏原有的导入方式,因此也可能出现一些奇奇怪怪的问题,敬请留意。
sys.meta_path 属于 Python 探针的一种运用。探针,即import hook,是 Python 几乎不受人关注的机制,但它可以做很多事,例如加载网络上的库、在导入模块时对模块进行修改、自动安装缺失库、上传审计信息、延迟加载等等。
限于篇幅,我们不再详细展开了。最后小结一下:
-
可以用 try…except 方式,实现简单的三方库导入或者替换
-
已知全部缺失的依赖库时(如 requirements.txt),可以手动安装
-
利用 sys.meta_path,可以自动导入任意的缺失库















 345
345











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









