







1 问题描述
- 请将数据导入pandas中,加上列名
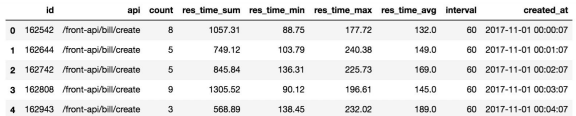

- 检测重复值
- 检测异常值
- 分析api和interval这两列的数据是否对分析有用,如果无用,说明为什么后将这两列丢弃
- 使用created_at这一列的数据作为时间索引
- 分析api调用次数情况,例如,在一天中,哪些时间是访问高峰,哪些时间段访问比较,如图所示,从凌晨2点到11点访问少,业务高峰出在现下午两三点,晚上八九点
- 分析一天中api响应时间,如下图所示,可以看到在业务高峰时间段,最大响应时间和平均响应时间都有所上升
- 分析连续的几天数据,可以发现,每天的业务高峰时段都比较相似
- 分析周末访问量是否有增加。
2 解题提示
跟着录播课,完成作业三
3 评分标准
作业三共计 50分,任务五 10分,其余要求各 5分。
4 要点解析
直方图:数据的分布情况,横轴是数据范围,纵轴是落在范围内的频数,适用于大数据
柱状图:统计类别数据的数量,横轴是数据的类别,纵轴是类别的频数,适用于少量数据,而且类别不宜过多
散点图:通常用于比较跨类别的数据
折线图:最适合用于显示随时间(根据常用比例设置)而变化的连续数据。同时还可以看出数量的差异,增长趋势的变化。
饼图:显示每组数据相对于总数的大小,而且显现方式直观
箱线图:它也可以粗略地看出数据是否具有对称性、分布的分散程度等信息,特别可以用于对几个样本的比较。
numpy 提供了一个在Python中做科学计算的基础库,重在数值计算,主要用于多维数组(矩阵)处理的库。
Pandas 是一个强大的分析结构化数据的工具集,基于NumPy构建,提供了高级数据结构和数据操作工具,它是使Python成为强大而高效的数据分析环境的重要因素之一。
Pandas来简化许多繁琐的数据科学任务。但是如果预计的处理时间超过多个小时,建议使用Numpy来替代Pandas。
5 代码实现
#%%
# 导入模块
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
#%%
# 读取数据,header列名
df = pd.read_csv('./log.txt', header = None)
# 默认读取前5条
df.head()
#%%
# 在每一列数据中加上制表符
df = pd.read_csv('./log.txt', header = None, sep = '\t')
df.head()
#%%
# 加上列名
df.columns = ['id', 'api', 'count', 'res_time_sum', 'res_time_min', 'res_time_max', 'res_time_avg', 'interval', 'created_at']
#%%
df.head(2)
#%%
# 随机采样,多次执行,数据不一样,看大概
df.sample(5)
#%%
# 查看数据格式
df.shape
#%%
# 查看数据类型
df.dtypes
#%%
# 查看内存占用空间
df.info()
#%%
# 查看api的详细信息
df['api'].describe()
#%%
# 优化内存, 指定axis,指定删除一列
df = df.drop('api', axis = 1)
#%%
df.head(2)
#%%
# 查看内存占用空间
df.info()
#%%
# 查看 created_at这一列的信息
df['created_at'].describe()
#%%
# 取某一天的数据,时间是字符串不可以使用模糊查询
df[df.created_at == '2019-05-01']
#%%
# 选择区间,查看数据
df[(df.created_at >= '2019-05-01') & (df.created_at < '2019-05-02')]
#%%
# 当前索引
df.index
#%%
# 将时间改为索引
df.index = df['created_at']
#%%
# 还是字符串,需要转化为时间序列
df['2019-05-01']
#%%
# 查看内存,及其信息
df.info()
#%%
# 查看索引
df.index
#%%
# 将时间的字符串类型转化为时间序列
df.index = pd.to_datetime(df.created_at)
#%%
# 查看索引
df.index
#%%
# 查找某一天的数据
df['2019-5-1']
#%%
# 查看interval这一列的数据信息
df.interval.describe()
#%%
# 查看这一列的数据种类
df.interval.unique()
#%%
# 删除无用数据列
df = df.drop(['id', 'interval'], axis = 1)
df.head()
#%%
# 查看内存
df.info()
#%%
# 查看数据统计
df.describe()
#%%
# 初步分析count,直方图,每分钟调用次数
df['count'].hist()
plt.show()
#%%
# 表示接口调用分布情况,大部分都在10次以内 ,反映出每分钟调用的次数分布情况
# 增加柱子数目
df['count'].hist(bins = 30)
plt.show()
#%%
# 切出一天的数据,绘制一天时段的接口调用情况
df['2019-5-1']['count'].plot()
plt.show()
#%%
# 凌晨时间无人访问, 下午2,3点第一个访问高峰,晚上,8,9点,第二个访问高峰
#%%
# 用count重采样,用一个小时进行采样,没那么多数据点了,图像比较平滑
df2 = df['2019-5-1']
#%%
df2 = df2[['count']].resample('1H').mean()
df2
#%%
# 绘制1个小时的图像
df2['count'].plot()
plt.show()
#%%
## 折线图和直方图, 可以看到业务的高峰时段在什么地方, 分不清具体时间,绘制柱状图
plt.figure(figsize = (10, 3)) # 单位是英寸
df2['count'].plot(kind = 'bar')
plt.xticks(rotation = 60) # 文字旋转角度
plt.show()
#%%
# 分析有没有异常时段,访问接口过于频繁,可能就是黑客潮水攻击
df['2019-5-1'][['count']].boxplot(showmeans = True, meanline = True)
plt.show()
#%%
# 分析次数大于20的数据
df[df['count'] > 20]
#%%
# 某一天的响应时间,平均响应时间
df['2019-5-1']['res_time_avg'].plot()
#%%
# 查看平均时间有没有异常值
df['2019-5-1'][['res_time_avg']].boxplot()
#%%
# 查看平均时间大于 1000的,分析问题
df2 = df['2019-5-1']
df2[df['res_time_avg'] > 1000]
#%%
# 2019-05-01 00:34:48 1 1694.47 1694.47 1694.47 1694.0 2019-05-01 00:34:48 定义为异常值
# 查看访问时间,每分钟采样
df['2019-5-1'][['res_time_sum', 'res_time_min', 'res_time_max', 'res_time_avg']].plot()
plt.show()
#%%
# 20分钟采样
data = df['2019-5-1'].resample('20T').mean()
data[['res_time_sum', 'res_time_min', 'res_time_max', 'res_time_avg']].plot()
plt.show()
#%%
# 业务高峰时段 下午2-3点,晚上7-8点,响应时间都是上升的
#%%
# 查看访问次数
df['2019-5-1' : '2019-5-10']['count'].plot()
plt.show()
#%%
# 每天的情况都差不多,下面看看周末和平常是不是一样的
df['2019-5-2'].index.weekday # 0 代表星期一, 1 代表星期二 , 5,6分别代表周六和周日
#%%
# 建一列数据,代表是周几
df['weekday'] = df.index.weekday
#%%
df.head(2)
#%%
# 判断是否是周末 ,是不是5,6
df['weekend'] = df['weekday'].isin({5, 6})
df.head(5)
#%%
# 对weekend 进行分组, 对count列 求平均值
df.groupby('weekend')['count'].mean()
#%%
# 周末调用平均次数多,7.57,
# 周末哪个时段调用次数比较高
df.groupby(['weekend', df.index.hour])['count'].mean()
#%%
# 周末和非周末,具体时间对比, 绘制成图形,否则不直观
df.groupby(['weekend', df.index.hour])['count'].mean().plot()
plt.show()
#%%
# 周末和非周末数据叠加
df.groupby(['weekend', df.index.hour])['count'].mean().unstack(level = 0)
#%%
# 展示周末与非周末,时间段时间对比
df.groupby(['weekend', df.index.hour])['count'].mean().unstack(level = 0).plot()
plt.show()
#%%
















 219
219











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









