







1-redis发展历程
redis2.6-支持lua脚本;
redis3.0-支持集群方案;
redis4.0-混合持久化,多线程异步删除
Redis 5.0 (GA October 2018) introduced the new stream data type, sorted set blocking pop operations, LFU/LRU info in RDB, a cluster manager in redis-cli, active defragmentation V2, better HyperLogLogs, and many other improvements.
Redis 6.0 (GA October, 2021) introduced SSL, the new RESP3 protocol, ACLs, client side caching, diskless replicas, I/O threads, faster RDB loading, new modules APIs, and many more improvements.
2-redis4.0版本之前单线程相关
2.1-采用单线程的原因
使用单线程模型是 Redis 的开发和维护更简单,因为单线程模型方便开发和调试;
即使使用单线程模型也并发的处理多客户端的请求,主要使用的是IO多路复用和非阻塞IO:
对于Redis系统来说,主要的性能瓶颈是内存或者网络带宽而并非 CPU。
https://redis.io/docs/getting-started/faq/

2.2-redis单线程理解
主要是指Redis的网络IO和键值对读写是由一个线程来完成的,Redis在处理客户端的请求时包括获取(socket 读)、解析、执行、内容返回(socket 写)等都由一个顺序行的主线程处理,这就是所谓的"单线程"。这也是Redis对外提供键值存储服务的主要流程。
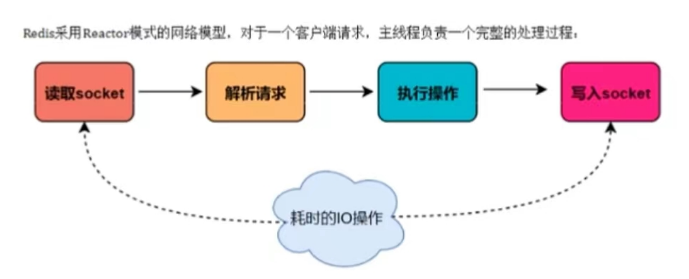
但Redis的其他功能,比如持久化RDB、AOF、异步删除、集群数据同步等等,其实是由额外的线程执行的。Redis命令工作线程是单线程的,但是,整个Redis来说,是多线程的;
2.3-redis为何这么快
基于内存操作:Redis 的所有数据都存在内存中,因此所有的运算都是内存级别的,所以他的性能比较高;
数据结构简单:Redis 的数据结构是专门设计的,而这些简单的数据结构的查找和操作的时间大部分复杂度都是 0(1),因此性能比较高;
多路复用和非阻塞IO:Redis使用 IO多路复用功能来监听多个 socket连接客户端,这样就可以使用一个线程连接来处理多个请求,减少线程切换带来的开销,同时也避免了 I/O 阻塞操作
避免上下文切换:因为是单线程模型,因此就避免了不必要的上下文切换和多线程竞争,这就省去了多线程切换带来的时间和性能上的消耗,而且单线程不会导致死锁问题的发生。
3-redis6之后的版本多线程
在Redis6/7中,非常受关注的第一个新特性就是多线程。
这是因为,Redis一直被大家熟知的就是它的单线程架构,虽然有些命令操作可以用后台线程或子进程执行(比如数据制除、快照生成、AOF重写)但是,从网络IO处理到实际的读写命令处理,都是由单个线程完成的。
随着网络硬件的性能提升,Redis的性能瓶颈有时会出现在网络IO的处理上,也就是说,单个主线程处理网络请求的速度跟不上底层网络硬件的速度。
为了应对这个问题:
采用多个IO线程来处理网络请求,提高网络请求处理的并行度,Redis6/7就是采用的这种方法。
但是,Redis的多IO线程只是用来处理网络请求的,对于读写操作命令Redis仍然使用单线程来处理。这是因为,Redis处理请求时,网络处理经常是瓶颈,通过多个IO线程并行处理网络操作,可以提升实例的整体处理性能。而继续使用单线程执行命令操作,就不用为了保证Lua脚本、事务的原子性,额外开发多线程互斥加锁机制了(不管加锁操作处理),这样一来,Redis线程模型实现就简单了。
Redis6开始,就新增了多线程的功能来提高 I/O 的读写性能,他的主要实现思路是将主线程的 IO 读写任务拆分给一组独立的线程去执行,这样就可以使多个 socket的读写可以并行化了,采用IO多路复用技术可以让单个线程高效的处理多个连接请求(尽量减少网络IO的时间消耗),将最耗时的Soket的读取、请求解析、写入单独外包出去,剩下的命令执行仍然由主线程串行执行并和内存的数据交互。

4-IO多路复用
4.1-文件描述符fd
unix系统中,一切皆文件
文件描述符(File descriptor)是计算机科学中的一个术语,是一个用于表述指向文件的引用的抽象化概念。文件描述符在形式上是一个非负整数。实际上,它是一个索引值,指向内核为每一个进程所维护的该进程打开文件的记录表。当程序打开一个现有文件或者创建一个新文件时,内核向进程返回一个文件描述符。在程序设计中,文件描述符这一概念往往只适用于UNIX、Linux这样的操作系统。
4.2-IO多路复用
一种同步的IO模型,实现一个线程监视多个文件句柄,一旦某个文件句柄就绪就能够通知到对应应用程序进行相应的读写操作,没有文件句柄就绪时就会阻塞应用程序从而释放CPU资源。

将用户socket对应的文件描述符(FileDescriptor)注册进epoll,然后epoll帮你监听哪些socket上有消息到达,这样就避免了大量的无用操作。此时的socket应该采用非阻寒模式。这样,整个过程只在调用select、poll、epoll这些调用的时候才会阻塞,收发客户消息是不会阳塞的,整个进程或者线程就被充分利用起来,这就是事件驱动,所谓的reactor反应模式。

在单个线程通过记录跟踪每一个Sockek(IO流)的状态来同时管理多个IO流,一个服务端进程可以同时处理多个套接字描述符。
目的是尽量多的提高服务器的吞吐能力。
大家都用过nginx,nginx使用epoll接收请求,ngnix会有很多链接进来,epoll会把他们都监视起来,然后像拨开关一样,谁有数据就拨向谁。
然后调用相应的代码处理。redis类似同理,这就是IO多路复用原理,有请求就响应,没请求不打扰。
5-多线程默认情况
默认情况下,多线程数是关闭的(因为大多数情况下,IO线程不配置性能也很高),只有你的机器至少有4核以上才建议打开,而且配置的IO现场数,给出了建议。如果是四核机器,配置为2-3;如果是八核,配置6。
















 635
635











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









