






第一,首先我们可以新建一个XLSX文件。鼠标放在第一行第一列的位置
第二,我们打开WPS或者word里面的数据选项
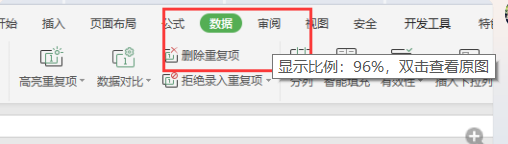
我们接着点击导入数据

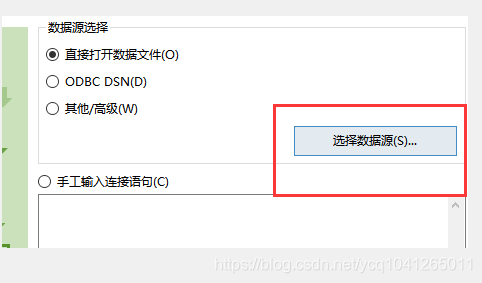
第三:如下图所示:我们可以选择数据源
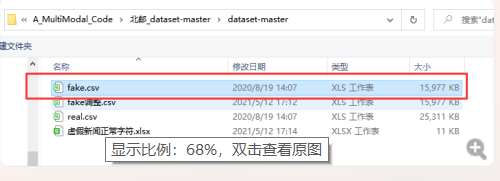
第四:选择你打开乱码的那个csv文件
接下来就会看到如下界面:
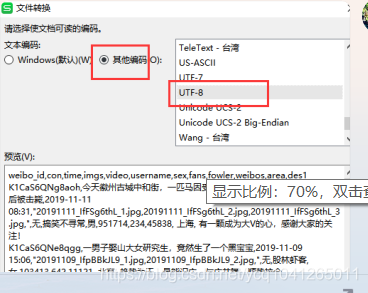
因为csv是逗号分隔符文件 所以我们选择逗号,然后就可以完成转换,正常看到原始csv文件。

第一,首先我们可以新建一个XLSX文件。鼠标放在第一行第一列的位置
第二,我们打开WPS或者word里面的数据选项
我们接着点击导入数据
第三:如下图所示:我们可以选择数据源
第四:选择你打开乱码的那个csv文件
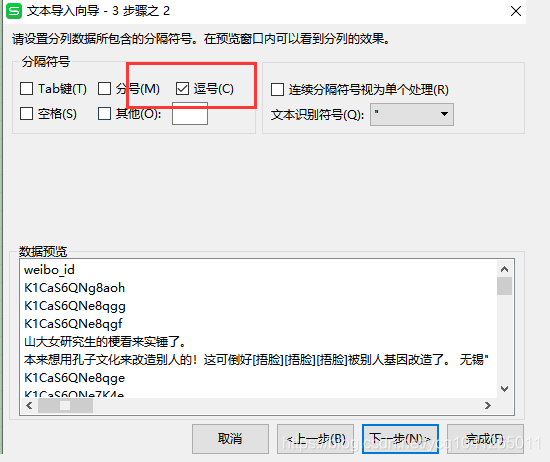
接下来就会看到如下界面:
因为csv是逗号分隔符文件 所以我们选择逗号,然后就可以完成转换,正常看到原始csv文件。
 1545
1545

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


























