







go test工具
Go语言中的测试依赖go test命令
go test命令是一个按照一定约定和组织的测试代码的驱动程序。在包目录内,所有以**_test.go**为后缀名的源代码文件都是go test测试的一部分,不会被go build编译到最终的可执行文件中。
测试函数
测试函数的格式
测试函数的名字必须以Test开头,可选的后缀名必须以大写字母开头
func TestName(t *testing.T){
// ...
}
案例
func Split(s, sep string) (result []string) {
i := strings.Index(s, sep)
for i > -1 {
result = append(result, s[:i])
s = s[i+1:]
i = strings.Index(s, sep)
}
result = append(result, s)
return
}
创建一个split_test.go的测试文件,并定义一个测试函数
import (
"reflect"
"testing"
)
func TestSplit(t *testing.T) { // 测试函数名必须以Test开头,必须接收一个*testing.T类型参数
got := Split("a:b:c", ":") // 程序输出的结果
want := []string{"a", "b", "c"} // 期望的结果
if !reflect.DeepEqual(want, got) { // 因为slice不能比较直接,借助反射包中的方法比较
t.Errorf("expected:%v, got:%v", want, got) // 测试失败输出错误提示
}
}
testify/assert
比如我们之前在TestSplit测试函数中就使用了reflect.DeepEqual来判断期望结果与实际结果是否一致。使用testify/assert之后就能将上述判断过程简化如下:
t.Run(tt.name, func(t *testing.T) { // 使用t.Run()执行子测试
got := Split(tt.input, tt.sep)
assert.Equal(t, got, tt.want) // 使用assert提供的断言函数
})
测试组
每一个测试都要写一个声明很麻烦,可以封装成结构体
func TestSplit(t *testing.T) {
// 定义一个测试用例类型
type test struct {
input string
sep string
want []string
}
// 定义一个存储测试用例的切片
tests := []test{
{input: "a:b:c", sep: ":", want: []string{"a", "b", "c"}},
{input: "a:b:c", sep: ",", want: []string{"a:b:c"}},
{input: "abcd", sep: "bc", want: []string{"a", "d"}},
{input: "沙河有沙又有河", sep: "沙", want: []string{"河有", "又有河"}},
}
// 遍历切片,逐一执行测试用例
for _, tc := range tests {
got := Split(tc.input, tc.sep)
if !reflect.DeepEqual(got, tc.want) {
t.Errorf("expected:%v, got:%v", tc.want, got)
}
}
}
子测试
如果测试用例比较多的时候,我们是没办法一眼看出来具体是哪个测试用例失败了。我们可能会想到下面的解决办法
func TestSplit(t *testing.T) {
type test struct { // 定义test结构体
input string
sep string
want []string
}
tests := map[string]test{ // 测试用例使用map存储
"simple": {input: "a:b:c", sep: ":", want: []string{"a", "b", "c"}},
"wrong sep": {input: "a:b:c", sep: ",", want: []string{"a:b:c"}},
"more sep": {input: "abcd", sep: "bc", want: []string{"a", "d"}},
"leading sep": {input: "沙河有沙又有河", sep: "沙", want: []string{"河有", "又有河"}},
}
for name, tc := range tests {
t.Run(name, func(t *testing.T) { // 使用t.Run()执行子测试
got := Split(tc.input, tc.sep)
if !reflect.DeepEqual(got, tc.want) {
t.Errorf("expected:%#v, got:%#v", tc.want, got)
}
})
}
}
备注:可以通过-run=RegExp来指定运行的测试用例,还可以通过/来指定要运行的子测试用例,例如:go test -v -run=Split/simple只会运行simple对应的子测试用例。
基准测试
格式
基准测试以Benchmark为前缀,需要一个testing.B类型的参数b,基准测试必须要执行b.N*次,这样的测试才有对照性,b.N的值是系统根据实际情况去调整的,从而保证测试的稳定性。
func BenchmarkName(b *testing.B){
// ...
}
测试用例
func BenchmarkSplit(b *testing.B) {
for i := 0; i < b.N; i++ {
Split("asdasdasd", "a")
}
}
基准测试并不会默认执行,需要增加-bench参数,所以我们通过执行go test -bench=Split命令执行基准测试,输出结果如下:
split $ go test -bench=Split
goos: darwin
goarch: amd64
pkg: github.com/Q1mi/studygo
BenchmarkSplit-8 10000000 203 ns/op
PASS
ok github.com/Q1mi/studygo 2.255s
其中BenchmarkSplit-8表示对Split函数进行基准测试,数字8表示GOMAXPROCS的值,这个对于并发基准测试很重要。10000000和203ns/op表示每次调用Split函数耗时203ns,这个结果是10000000次调用的平均值。
我们还可以为基准测试添加-benchmem参数,来获得内存分配的统计数据。
split $ go test -bench=Split -benchmem
goos: darwin
goarch: amd64
pkg: github.com/Q1mi/studygo/code_demo/test_demo/split
BenchmarkSplit-8 10000000 215 ns/op 112 B/op 3 allocs/op
PASS
ok github.com/Q1mi/studygo 2.394s
其中,112 B/op表示每次操作内存分配了112字节,3 allocs/op则表示每次操作进行了3次内存分配。 我们将我们的Split函数优化如下:
func Split(s, sep string) (result []string) {
//count用来计算分割几次,+1
result = make([]string, 0, strings.Count(s, sep)+1)
i := strings.Index(s, sep)
for i > -1 {
result = append(result, s[:i])
s = s[i+len(sep):] // 这里使用len(sep)获取sep的长度
i = strings.Index(s, sep)
}
result = append(result, s)
return
}
这一次我们提前使用make函数将result初始化为一个容量足够大的切片,而不再像之前一样通过调用append函数来追加。我们来看一下这个改进会带来多大的性能提升:
split $ go test -bench=Split -benchmem
goos: darwin
goarch: amd64
pkg: github.com/Q1mi/studygo/code_demo/test_demo/split
BenchmarkSplit-8 10000000 127 ns/op 48 B/op 1 allocs/op
PASS
ok github.com/Q1mi/studygo 1.423s
这个使用make函数提前分配内存的改动,减少了2/3的内存分配次数,并且减少了一半的内存分配。
性能比较函数
上面的基准测试只能得到给定操作的绝对耗时,但是在很多性能问题是发生在两个不同操作之间的相对耗时,比如同一个函数处理1000个元素的耗时与处理1万甚至100万个元素的耗时的差别是多少?再或者对于同一个任务究竟使用哪种算法性能最佳?我们通常需要对两个不同算法的实现使用相同的输入来进行基准比较测试。
性能比较函数通常是一个带有参数的函数,被多个不同的Benchmark函数传入不同的值来调用。举个例子如下:
// fib_test.go
func benchmarkFib(b *testing.B, n int) {
for i := 0; i < b.N; i++ {
Fib(n)
}
}
func BenchmarkFib1(b *testing.B) { benchmarkFib(b, 1) }
func BenchmarkFib2(b *testing.B) { benchmarkFib(b, 2) }
func BenchmarkFib3(b *testing.B) { benchmarkFib(b, 3) }
func BenchmarkFib10(b *testing.B) { benchmarkFib(b, 10) }
func BenchmarkFib20(b *testing.B) { benchmarkFib(b, 20) }
func BenchmarkFib40(b *testing.B) { benchmarkFib(b, 40) }
运行基准测试:
split $ go test -bench=.
goos: darwin
goarch: amd64
pkg: github.com/Q1mi/studygo/code_demo/test_demo/fib
BenchmarkFib1-8 1000000000 2.03 ns/op
BenchmarkFib2-8 300000000 5.39 ns/op
BenchmarkFib3-8 200000000 9.71 ns/op
BenchmarkFib10-8 5000000 325 ns/op
BenchmarkFib20-8 30000 42460 ns/op
BenchmarkFib40-8 2 638524980 ns/op
PASS
ok github.com/Q1mi/studygo 12.944s
pprof调优工具
Go性能优化
Go语言项目中的性能优化主要有以下几个方面:
CPU profile:报告程序的 CPU 使用情况,按照一定频率去采集应用程序在 CPU 和寄存器上面的数据
Memory Profile(Heap Profile):报告程序的内存使用情况
Block Profiling:报告 goroutines 不在运行状态的情况,可以用来分析和查找死锁等性能瓶颈
Goroutine Profiling:报告 goroutines 的使用情况,有哪些 goroutine,它们的调用关系是怎样的
采集性能数据
Go语言内置了获取程序的运行数据的工具,包括以下两个标准库:
runtime/pprof:采集工具型应用运行数据进行分析
net/http/pprof:采集服务型应用运行时数据进行分析
pprof开启后,每隔一段时间(10ms)就会收集下当前的堆栈信息,获取各个函数占用的CPU以及内存资源;最后通过对这些采样数据进行分析,形成一个性能分析报告。
注意,我们只应该在性能测试的时候才在代码中引入pprof。
工具型应用
如果你的应用程序是运行一段时间就结束退出类型。那么最好的办法是在应用退出的时候把 profiling 的报告保存到文件中,进行分析。对于这种情况,可以使用runtime/pprof库。
import "runtime/pprof"
CPU性能分析
//开启CPU性能分析:
pprof.StartCPUProfile(w io.Writer)
//停止CPU性能分析:
pprof.StopCPUProfile()
应用执行结束后,就会生成一个文件,保存了我们的 CPU profiling 数据。得到采样数据之后,使用go tool pprof工具进行CPU性能分析。
内存性能优化
记录程序的堆栈信息
pprof.WriteHeapProfile(w io.Writer)
得到采样数据之后,使用go tool pprof工具进行内存性能分析。
go tool pprof默认是使用-inuse_space进行统计,还可以使用-inuse-objects查看分配对象的数量。
服务型应用
如果你的应用程序是一直运行的,比如 web 应用,那么可以使用net/http/pprof库,它能够在提供 HTTP 服务进行分析。
如果使用了默认的http.DefaultServeMux(通常是代码直接使用 http.ListenAndServe(“0.0.0.0:8000”, nil)),只需要在你的web server端代码中按如下方式导入net/http/pprof
import _ "net/http/pprof"
//如果你使用自定义的 Mux,则需要手动注册一些路由规则:
r.HandleFunc("/debug/pprof/", pprof.Index)
r.HandleFunc("/debug/pprof/cmdline", pprof.Cmdline)
r.HandleFunc("/debug/pprof/profile", pprof.Profile)
r.HandleFunc("/debug/pprof/symbol", pprof.Symbol)
r.HandleFunc("/debug/pprof/trace", pprof.Trace)
如果你使用的是gin框架,那么推荐使用github.com/gin-contrib/pprof,在代码中通过以下命令注册pprof相关路由。
pprof.Register(router)
访问它会得到类似下面的内容:debug/pprof这个路径下还有几个子页面:
/debug/pprof/profile:访问这个链接会自动进行 CPU profiling,持续 30s,并生成一个文件供下载
/debug/pprof/heap: Memory Profiling 的路径,访问这个链接会得到一个内存 Profiling 结果的文件
/debug/pprof/block:block Profiling 的路径
/debug/pprof/goroutines:运行的goroutines 列表,以及调用关系
go tool pprof命令
不管是工具型应用还是服务型应用,我们使用相应的pprof库获取数据之后,下一步的都要对这些数据进行分析,我们可以使用go tool pprof命令行工具。
go tool pprof最简单的使用方式为:
go tool pprof [binary] [source]
其中:
binary 是应用的二进制文件,用来解析各种符号;
source 表示 profile 数据的来源,可以是本地的文件,也可以是 http 地址。
注意事项: 获取的 Profiling 数据是动态的,要想获得有效的数据,请保证应用处于较大的负载(比如正在生成中运行的服务,或者通过其他工具模拟访问压力)。否则如果应用处于空闲状态,得到的结果可能没有任何意义。
具体示例
首先我们来写一段有问题的代码:
// runtime_pprof/main.go
package main
import (
"flag"
"fmt"
"os"
"runtime/pprof"
"time"
)
// 一段有问题的代码
func logicCode() {
var c chan int
for {
select {
case v := <-c:
fmt.Printf("recv from chan, value:%v\n", v)
default:
}
}
}
func main() {
var isCPUPprof bool
var isMemPprof bool
//标志位,用来做启动参数
flag.BoolVar(&isCPUPprof, "cpu", false, "turn cpu pprof on")
flag.BoolVar(&isMemPprof, "mem", false, "turn mem pprof on")
flag.Parse()
if isCPUPprof {
file, err := os.Create("./cpu.pprof")
if err != nil {
fmt.Printf("create cpu pprof failed, err:%v\n", err)
return
}
pprof.StartCPUProfile(file)
defer pprof.StopCPUProfile()
}
for i := 0; i < 8; i++ {
go logicCode()
}
time.Sleep(20 * time.Second)
if isMemPprof {
file, err := os.Create("./mem.pprof")
if err != nil {
fmt.Printf("create mem pprof failed, err:%v\n", err)
return
}
pprof.WriteHeapProfile(file)
file.Close()
}
}
通过flag我们可以在命令行控制是否开启CPU和Mem的性能分析。 将上面的代码保存并编译成runtime_pprof可执行文件,执行时加上-cpu命令行参数如下:
./runtime_pprof -cpu
等待30秒后会在当前目录下生成一个cpu.pprof文件。会进入到命令行交互界面
我们使用go工具链里的pprof来分析一下。
go tool pprof cpu.pprof
执行上面的代码会进入交互界面如下:
runtime_pprof $ go tool pprof cpu.pprof
Type: cpu
Time: Jun 28, 2019 at 11:28am (CST)
Duration: 20.13s, Total samples = 1.91mins (568.60%)
Entering interactive mode (type "help" for commands, "o" for options)
(pprof)
我们可以在交互界面输入top3来查看程序中占用CPU前3位的函数:
(pprof) top3
Showing nodes accounting for 100.37s, 87.68% of 114.47s total
Dropped 17 nodes (cum <= 0.57s)
Showing top 3 nodes out of 4
flat flat% sum% cum cum%
42.52s 37.15% 37.15% 91.73s 80.13% runtime.selectnbrecv
35.21s 30.76% 67.90% 39.49s 34.50% runtime.chanrecv
22.64s 19.78% 87.68% 114.37s 99.91% main.logicCode
其中:
flat:当前函数占用CPU的耗时
flat::当前函数占用CPU的耗时百分比
sun%:函数占用CPU的耗时累计百分比
cum:当前函数加上调用当前函数的函数占用CPU的总耗时
cum%:当前函数加上调用当前函数的函数占用CPU的总耗时百分比
最后一列:函数名称
在大多数的情况下,我们可以通过分析这五列得出一个应用程序的运行情况,并对程序进行优化。
我们还可以使用list 函数名命令查看具体的函数分析,例如执行list logicCode查看我们编写的函数的详细分析。
(pprof) list logicCode
Total: 1.91mins
ROUTINE ================ main.logicCode in .../runtime_pprof/main.go
22.64s 1.91mins (flat, cum) 99.91% of Total
. . 12:func logicCode() {
. . 13: var c chan int
. . 14: for {
. . 15: select {
. . 16: case v := <-c:
22.64s 1.91mins 17: fmt.Printf("recv from chan, value:%v\n", v)
. . 18: default:
. . 19:
. . 20: }
. . 21: }
. . 22:}
通过分析发现大部分CPU资源被17行占用,我们分析出select语句中的default没有内容会导致上面的case v:=<-c:一直执行。我们在default分支添加一行time.Sleep(time.Second)即可。
图形化
或者可以直接输入web,通过svg图的方式查看程序中详细的CPU占用情况。 想要查看图形化的界面首先需要安装graphviz图形化工具。

Mac:
brew install graphviz
Windows: 下载graphviz 将graphviz安装目录下的bin文件夹添加到Path环境变量中。 在终端输入dot -version查看是否安装成功。
CPU占比图关于图形的说明: 每个框代表一个函数,理论上框的越大表示占用的CPU资源越多。 方框之间的线条代表函数之间的调用关系。 线条上的数字表示函数调用的次数。 方框中的第一行数字表示当前函数占用CPU的百分比,第二行数字表示当前函数累计占用CPU的百分比。
除了分析CPU性能数据,pprof也支持分析内存性能数据。比如,使用下面的命令分析http服务的heap性能数据,查看当前程序的内存占用以及热点内存对象使用的情况。
查看内存占用数据
go tool pprof -inuse_space http://127.0.0.1:8080/debug/pprof/heap
go tool pprof -inuse_objects http://127.0.0.1:8080/debug/pprof/heap
查看临时内存分配数据
go tool pprof -alloc_space http://127.0.0.1:8080/debug/pprof/heap
go tool pprof -alloc_objects http://127.0.0.1:8080/debug/pprof/heap
go-torch和火焰图
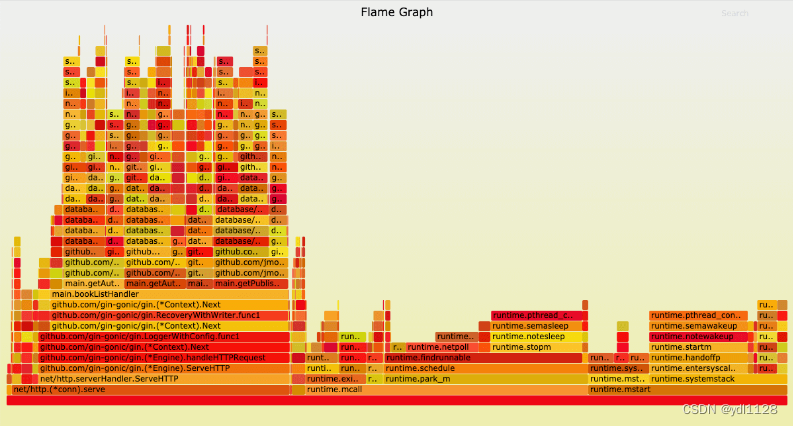
火焰图(Flame Graph)是 Bredan Gregg 创建的一种性能分析图表,因为它的样子近似 🔥而得名。上面的 profiling 结果也转换成火焰图,如果对火焰图比较了解可以手动来操作,不过这里我们要介绍一个工具:go-torch。这是 uber 开源的一个工具,可以直接读取 golang profiling 数据,并生成一个火焰图的 svg 文件。
安装go-torch
go get -v github.com/uber/go-torch
火焰图 svg 文件可以通过浏览器打开,它对于调用图的最优点是它是动态的:可以通过点击每个方块来 zoom in 分析它上面的内容。
火焰图的调用顺序从下到上,每个方块代表一个函数,它上面一层表示这个函数会调用哪些函数,方块的大小代表了占用 CPU 使用的长短。火焰图的配色并没有特殊的意义,默认的红、黄配色是为了更像火焰而已。
go-torch 工具的使用非常简单,没有任何参数的话,它会尝试从http://localhost:8080/debug/pprof/profile获取 profiling 数据。它有三个常用的参数可以调整:
-u –url:要访问的 URL,这里只是主机和端口部分
-s –suffix:pprof profile 的路径,默认为 /debug/pprof/profile
–seconds:要执行 profiling 的时间长度,默认为 30s
安装 FlameGraph
要生成火焰图,需要事先安装 FlameGraph工具,这个工具的安装很简单(需要perl环境支持),只要把对应的可执行文件加入到环境变量中即可。
下载安装perl:https://www.perl.org/get.html
下载FlameGraph:git clone https://github.com/brendangregg/FlameGraph.git
将FlameGraph目录加入到操作系统的环境变量中。
Windows平台的同学,需要把go-torch/render/flamegraph.go文件中的GenerateFlameGraph按如下方式修改,然后在go-torch目录下执行go install即可。
// GenerateFlameGraph runs the flamegraph script to generate a flame graph SVG. func GenerateFlameGraph(graphInput []byte, args ...string) ([]byte, error) {
flameGraph := findInPath(flameGraphScripts)
if flameGraph == "" {
return nil, errNoPerlScript
}
if runtime.GOOS == "windows" {
return runScript("perl", append([]string{flameGraph}, args...), graphInput)
}
return runScript(flameGraph, args, graphInput)
}
压测工具wrk
推荐使用https://github.com/wg/wrk 或 https://github.com/adjust/go-wrk
使用go-torch
使用wrk进行压测:
go-wrk -n 50000 http://127.0.0.1:8080/book/list
在上面压测进行的同时,打开另一个终端执行:
go-torch -u http://127.0.0.1:8080 -t 30
30秒之后终端会初夏如下提示:Writing svg to torch.svg
然后我们使用浏览器打开torch.svg就能看到如下火焰图了。火焰图火焰图的y轴表示cpu调用方法的先后,x轴表示在每个采样调用时间内,方法所占的时间百分比,越宽代表占据cpu时间越多。通过火焰图我们就可以更清楚的找出耗时长的函数调用,然后不断的修正代码,重新采样,不断优化。
此外还可以借助火焰图分析内存性能数据:
go-torch -inuse_space http://127.0.0.1:8080/debug/pprof/heap
go-torch -inuse_objects http://127.0.0.1:8080/debug/pprof/heap
go-torch -alloc_space http://127.0.0.1:8080/debug/pprof/heap
go-torch -alloc_objects http://127.0.0.1:8080/debug/pprof/heap
pprof与性能测试结合
go test命令有两个参数和 pprof 相关,它们分别指定生成的 CPU 和 Memory profiling 保存的文件:
-cpuprofile:cpu profiling 数据要保存的文件地址
-memprofile:memory profiling 数据要报文的文件地址
我们还可以选择将pprof与性能测试相结合,比如:
比如下面执行测试的同时,也会执行 CPU profiling,并把结果保存在 cpu.prof 文件中:
go test -bench . -cpuprofile=cpu.prof
比如下面执行测试的同时,也会执行 Mem profiling,并把结果保存在 cpu.prof 文件中:
go test -bench . -memprofile=./mem.prof
需要注意的是,Profiling 一般和性能测试一起使用,这个原因在前文也提到过,只有应用在负载高的情况下 Profiling 才有意义。














 332
332











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









