







实践感受写在前面
- RAG是重要的LLM应用方向
- RAG的原理简单,Demo也不难,但做到成熟可用的RAG有很多问题要解决,并不简单:
- 需要优化向量生成(向量模型)
- 需要保证大数据量下的向量存储(向量数据库、分布式)
- 需要保证大数据量下的向量检索性能和关联准确性(Rerank,Graph等)
- 需要LLM的配合,提高输入上下文token的数量(LLM能力)
- 需要提供优秀的提示模板(提示工程)
- 需要解决安全性(无关问题拒答、多渠道应答)
- 基于以上,,茴香豆提供了成熟的应用框架,茴香豆有几个特点很有价值:
- 三阶段 Pipeline (前处理、拒答、响应),提高相应准确率和安全性
- 配性强,兼容多个 LLM 和 API
- 打通微信和飞书群聊天,适合国内知识问答场景
- 配置正反例调优知识助手效果
- 目前RAG产品非常多,试用过感觉不错的有
- 茴香豆
- QueryAnything(有道)
- GraphRAG(微软,但是生成向量实在是太慢了)
- MaxKB(这个是应用包裹)
- 正反例的测试结果
- 正例:非常好,提示了信息出处(md文件),详细说明内容
- 反例:可能是调整还不到位,反例没有拒绝回答,似乎作为不知道的知识传给LLM回答了。还要再测试。
- 结果见:2.4.2 Gradio UI 界面测试
- 注意:
- 文章中的茴香豆启动,standalone和gradio模式下,LLM都会自动被启动。不需我们用lmdeploy另外部署LLM
0 茴香豆介绍
[ ]
]
(https://raw.githubusercontent.com/fzd9752/pic_img/main/imgs/image-1.png)茴香豆 是由书生·浦语团队开发的一款开源、专门针对国内企业级使用场景设计并优化的知识问答工具。在基础 RAG 课程中我们了解到,RAG 可以有效的帮助提高 LLM 知识检索的相关性、实时性,同时避免 LLM 训练带来的巨大成本。在实际的生产和生活环境需求,对 RAG 系统的开发、部署和调优的挑战更大,如需要解决群应答、能够无关问题拒答、多渠道应答、更高的安全性挑战。因此,根据大量国内用户的实际需求,总结出了三阶段Pipeline的茴香豆知识问答助手架构,帮助企业级用户可以快速上手安装部署。
茴香豆特点:
- 三阶段 Pipeline (前处理、拒答、响应),提高相应准确率和安全性
- 打通微信和飞书群聊天,适合国内知识问答场景
- 支持各种硬件配置安装,安装部署限制条件少
- 适配性强,兼容多个 LLM 和 API
- 傻瓜操作,安装和配置方便
1 Web 版茴香豆
Web 版茴香豆部署在浦源平台,可以让大家零编程体验茴香豆的各种功能。
可以登录 https://openxlab.org.cn/apps/detail/tpoisonooo/huixiangdou-web使用,这里着重测试本地部署,所以略过。
2 茴香豆本地标准版搭建
作为企业应用,非常重要的一点是本地部署。后面尝试将茴香豆从源码部署到本地服务器(以 InternlmStudio 为例),
并开发一款简单的知识助手 Demo。
2.1 环境搭建
2.1.1 配置服务器
登录 InternStudio ,后创建开发机。过程略。
2.1.2 搭建茴香豆虚拟环境
命令行中输入以下命令,创建茴香豆专用 conda 环境:
studio-conda -o internlm-base -t huixiangdou
#创建成功,用下面的命令激活环境:
conda activate huixiangdou
环境激活成功后,命令行前的括号内会显示正在使用的环境,请确保所有茴香豆操作指令在 huixiangdou 环境下运行。
2.2 安装茴香豆
下面开始茴香豆本地标准版的安装。
2.2.1 下载茴香豆
先从茴香豆仓库拉取代码到服务器:
cd /root
# 克隆代码仓库
git clone https://github.com/internlm/huixiangdou && cd huixiangdou
git checkout 79fa810
拉取完成后进入茴香豆文件夹,开始安装。
首先安装茴香豆所需依赖:
conda activate huixiangdou
# parsing `word` format requirements
apt update
apt install python-dev libxml2-dev libxslt1-dev antiword unrtf poppler-utils pstotext tesseract-ocr flac ffmpeg lame libmad0 libsox-fmt-mp3 sox libjpeg-dev swig libpulse-dev
# python requirements
pip install BCEmbedding==0.15 cmake==3.30.2 lit==18.1.8 sentencepiece==0.2.0 protobuf==5.27.3 accelerate==0.33.0
pip install -r requirements.txt
# python3.8 安装 faiss-gpu 而不是 faiss
2.2.3 下载模型文件
茴香豆默认会根据配置文件自动下载对应的模型文件,为了节省时间,本次教程所需的模型已经提前下载到服务器中,我们只需要为本次教程所需的模型建立软连接,然后在配置文件中设置相应路径就可以:
# 创建模型文件夹
cd /root && mkdir models
# 复制BCE模型
ln -s /root/share/new_models/maidalun1020/bce-embedding-base_v1 /root/models/bce-embedding-base_v1
ln -s /root/share/new_models/maidalun1020/bce-reranker-base_v1 /root/models/bce-reranker-base_v1
# 复制大模型参数(下面的模型,根据作业进度和任务进行**选择一个**就行)
ln -s /root/share/new_models/Shanghai_AI_Laboratory/internlm2-chat-7b /root/models/internlm2-chat-7b
2.2.4 更改配置文件
茴香豆的所有功能开启和模型切换都可以通过 config.ini 文件进行修改。
也可以用编辑器手动修改,文件位置为 /root/huixiangdou/config.ini。
执行下面的命令更改配置文件,让茴香豆使用本地模型,包括向量模型,再排序模型和LLM模型。
sed -i '9s#.*#embedding_model_path = "/root/models/bce-embedding-base_v1"#' /root/huixiangdou/config.ini
sed -i '15s#.*#reranker_model_path = "/root/models/bce-reranker-base_v1"#' /root/huixiangdou/config.ini
sed -i '43s#.*#local_llm_path = "/root/models/internlm2-chat-7b"#' /root/huixiangdou/config.ini
修改后的配置文件如下:
1 [feature_store]
2 # `feature_store.py` use this throttle to distinct `good_questions` and `bad_questions`
3 reject_throttle = -1.0
4 # text2vec model, support local relative path, huggingface repo and URL.
5 # for example:
6 # "maidalun1020/bce-embedding-base_v1"
7 # "BAAI/bge-m3"
8 # "https://api.siliconflow.cn/v1/embeddings"
9 embedding_model_path = "/root/models/bce-embedding-base_v1"
10
11 # reranker model, support list:
12 # "maidalun1020/bce-reranker-base_v1"
13 # "BAAI/bge-reranker-v2-minicpm-layerwise"
14 # "https://api.siliconflow.cn/v1/rerank"
15 reranker_model_path = "/root/models/bce-reranker-base_v1"
16
17 # if using `siliconcloud` API as `embedding_model_path` or `reranker_model_path`, give the token
18 api_token = ""
19 api_rpm = 1000
20 work_dir = "workdir"
21
22 [web_search]
23 engine = "serper"
24 # web search engine support ddgs and serper
25 # For ddgs, see https://pypi.org/project/duckduckgo-search
26 # For serper, check https://serper.dev/api-key to get a free API key
27 serper_x_api_key = "YOUR-API-KEY-HERE"
28 domain_partial_order = ["arxiv.org", "openai.com", "pytorch.org", "readthedocs.io", "nvidia.com", "stackoverflow.com", "juejin.cn", "zhuanlan.zhihu.com", "www.cnblogs.com"]
29 save_dir = "logs/web_search_result"
30
31 [llm]
32 enable_local = 1
33 enable_remote = 0
34 # hybrid llm service address
35 client_url = "http://127.0.0.1:8888/inference"
36
37 [llm.server]
38 # local LLM configuration
39 # support "internlm/internlm2-chat-7b", "internlm2_5-7b-chat" and "qwen/qwen-7b-chat-int8"
40 # support local path, for example
41 # local_llm_path = "/path/to/your/internlm2_5"
42
43 local_llm_path = "/root/models/internlm2-chat-7b"
44 local_llm_max_text_length = 3000
45 # llm server listen port
46 local_llm_bind_port = 8888
注意!配置文件默认的模型和下载好的模型相同。如果不修改地址为本地模型地址,茴香豆将自动从 huggingface hub 拉取模型。如果选择拉取模型的方式,需要提前在命令行中运行 huggingface-cli login 命令,验证 huggingface 权限。
2.3 知识库创建
修改完配置文件后,就可以进行知识库的搭建,本次教程选用的是茴香豆和 MMPose 的文档,利用茴香豆搭建一个茴香豆和 MMPose 的知识问答助手。
conda activate huixiangdou
cd /root/huixiangdou && mkdir repodir
git clone https://github.com/internlm/huixiangdou --depth=1 repodir/huixiangdou
git clone https://github.com/open-mmlab/mmpose --depth=1 repodir/mmpose
# Save the features of repodir to workdir, and update the positive and negative example thresholds into `config.ini`
mkdir workdir
python3 -m huixiangdou.service.feature_store
在 huixiangdou 文件加下创建 repodir 文件夹,用来储存知识库原始文档。再创建一个文件夹 workdir 用来存放原始文档特征提取到的向量知识库。
[ root@intern-studio-50211982:~/huixiangdou# python3 -m huixiangdou.service.feature_store
/root/.conda/envs/huixiangdou/lib/python3.10/runpy.py:126: RuntimeWarning: 'huixiangdou.service.feature_store' found in sys.modules after import of package 'huixiangdou.service', but prior to execution of 'huixiangdou.service.feature_store'; this may result in unpredictable behaviour
warn(RuntimeWarning(msg))
2024-08-25 23:20:40.071 | INFO | huixiangdou.service.retriever:__init__:262 - loading test2vec and rerank models
08/25/2024 23:21:07 - [INFO] -BCEmbedding.models.RerankerModel->>> Loading from `/root/models/bce-reranker-base_v1`.
08/25/2024 23:21:08 - [INFO] -BCEmbedding.models.RerankerModel->>> Execute device: cuda; gpu num: 1; use fp16: True
...
2024-08-25 23:21:36.112 | INFO | __main__:analyze:170 - text histogram, length count 3611, avg 600.83, median 668
0-104 8.00%
104-208 5.70%
208-312 6.51%
312-416 6.20%
416-520 10.25%
520-624 9.39%
624-728 9.08%
728-832 14.04%
832-936 25.56%
936-1040 5.23%
1040-1144 0.03%
2024-08-25 23:21:36.114 | INFO | __main__:analyze:171 - token histogram, length count 3611, avg 223.44, median 234
0-56 10.77%
56-112 9.66%
112-168 9.86%
168-224 15.87%
224-280 18.94%
280-336 17.92%
336-392 11.27%
392-448 4.54%
448-504 1.08%
504-560 0.06%
560-616 0.03%
08/25/2024 23:21:36 - [INFO] -faiss.loader->>> Loading faiss with AVX2 support.
08/25/2024 23:21:36 - [INFO] -faiss.loader->>> Could not load library with AVX2 support due to:
ModuleNotFoundError("No module named 'faiss.swigfaiss_avx2'")
08/25/2024 23:21:36 - [INFO] -faiss.loader->>> Loading faiss.
08/25/2024 23:21:37 - [INFO] -faiss.loader->>> Successfully loaded faiss.
100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 3611/3611 [00:50<00:00, 71.71it/s]2024-08-25 23:22:28.027 | INFO | huixiangdou.primitive.file_operation:summarize:143 - 累计622文件,成功477个,跳过0个,异常145个
2024-08-25 23:22:29.220 | INFO | huixiangdou.service.retriever:update_throttle:82 - The optimal threshold is: 0.3315506875892811, saved it to config.ini
2024-08-25 23:22:29.446 | WARNING | __main__:test_reject:320 - process query: SAM 10个T 的训练集,怎么比比较公平呢~?速度上还有缺陷吧?
2024-08-25 23:22:29.458 | WARNING | __main__:test_reject:320 - process query: 想问下,如果只是推理的话,amp的fp16是不会省显存么,我看parameter仍然是float32,开和不开推理的显存占用都是一样的。能不能直接用把数据和model都 .half() 代替呢,相比之下amp好在哪里
2024-08-25 23:22:29.471 | WARNING | __main__:test_reject:320 - process query: mmdeploy支持ncnn vulkan部署么,我只找到了ncnn cpu 版本
2024-08-25 23:22:29.483 | WARNING | __main__:test_reject:320 - process query: 大佬们,如果我想在高空检测安全帽,我应该用 mmdetection 还是 mmrotate
2024-08-25 23:22:29.495 | INFO | huixiangdou.primitive.faiss:similarity_search_with_query:118 - highest score 0.295423251982713, threshold 0.3315506875892811
2024-08-25 23:22:29.495 | ERROR | __main__:test_reject:322 - reject query: 请问 ncnn 全称是什么
2024-08-25 23:22:29.507 | WARNING | __main__:test_reject:320 - process query: 有啥中文的 text to speech 模型吗?
2024-08-25 23:22:29.520 | INFO | huixiangdou.primitive.faiss:similarity_search_with_query:118 - highest score 0.056754373263161906, threshold 0.3315506875892811
2024-08-25 23:22:29.520 | ERROR | __main__:test_reject:322 - reject query: 今天中午吃什么?
2024-08-25 23:22:29.532 | WARNING | __main__:test_reject:320 - process query: huixiangdou 是什么?
2024-08-25 23:22:29.544 | WARNING | __main__:test_reject:320 - process query: mmpose 如何安装?
2024-08-25 23:22:29.555 | INFO | huixiangdou.primitive.faiss:similarity_search_with_query:118 - highest score 0.1645183858152115, threshold 0.3315506875892811
2024-08-25 23:22:29.556 | ERROR | __main__:test_reject:322 - reject query: 使用科研仪器需要注意什么?
Calculate scores: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 1/1 [00:00<00:00, 1.45it/s]2024-08-25 23:22:30.266 | INFO | huixiangdou.service.retriever:rerank_fuse:152 - target repodir/mmpose/docs/zh_cn/installation.md content length 6988
2024-08-25 23:22:30.268 | INFO | huixiangdou.service.retriever:rerank_fuse:152 - target repodir/mmpose/docs/zh_cn/installation.md content length 6988
2024-08-25 23:22:30.270 | INFO | huixiangdou.service.retriever:rerank_fuse:152 - target repodir/mmpose/docs/zh_cn/installation.md content length 6988
2024-08-25 23:22:30.273 | INFO | huixiangdou.service.retriever:rerank_fuse:152 - target repodir/mmpose/docs/en/installation.md content length 10677
2024-08-25 23:22:30.274 | DEBUG | huixiangdou.service.retriever:rerank_fuse:181 - query:text='mmpose installation' files:['repodir/mmpose/docs/zh_cn/installation.md', 'repodir/mmpose/docs/en/installation.md']
2024-08-25 23:22:30.292 | INFO | huixiangdou.primitive.faiss:similarity_search_with_query:118 - highest score 0.26077276838851204, threshold 0.3315506875892811
2024-08-25 23:22:30.292 | DEBUG | huixiangdou.service.retriever:rerank_fuse:181 - query:text='how to use std::vector ?' files:[]
2024-08-25 23:22:30.295 | INFO | __main__:test_query:360 -
+----------------------+----------+----------------------+---------------------+
| Query | State | Part of Chunks | References |
+======================+==========+======================+=====================+
| mmpose installation | Accepted | 安装 自定义安装 在 CPU 环境中安装 | installation.md,ins |
| | | mmpose 可以仅在 cpu | tallation.md |
| | | 环境中安装,在 cpu 模式下,您可以完 | |
| | | 成训练、测试和模型推理等所有操作。 | |
| | | 在 cpu 模式下,mmcv | |
| | | 的部分功能将不可.. | |
+----------------------+----------+----------------------+---------------------+
| how to use | Rejected | None | None |
| std::vector ? | | | |
+----------------------+----------+----------------------+---------------------+
配置中可见,在运行过一次特征提取后,茴香豆的阈值从 -1.0 更新到了 0.33。 配置文件中的 work_dir 参数指定了特征提取后向量知识库存放的位置。如果有多个知识库快速切换的需求,可以通过更改该参数实现。
2.4 测试知识助手
2.4.1 命令行运行
运行下面的命令,可以用命令行对现有知识库问答助手进行测试:
conda activate huixiangdou
cd /root/huixiangdou
python3 -m huixiangdou.main --standalone
通过命令行的方式可以看到对话的结果以及中间的过程,便于我们确认知识库是否覆盖需求,正反例是否合理。
这里启动不成功,又安装了lmdeploy后才成功。不知道原因。
注意,其实在standalone模式下,LLM也是被茴香豆的main来启动的,并不需要使用lmdeploy另外去部署LLM。
2.4.2 Gradio UI 界面测试
茴香豆也用 gradio 搭建了一个 Web UI 的测试界面,用来测试本地茴香豆助手的效果。
在运行茴香豆助手的服务器端,输入下面的命令,启动茴香豆 Web UI:
conda activate huixiangdou
cd /root/huixiangdou
python3 -m huixiangdou.gradio
在本地机器命令行中运行如下命令在本地建立端口转发隧道:
ssh -CNg -L 7860:127.0.0.1:7860 root@ssh.intern-ai.org.cn -p <你的ssh端口号>
看到上图相同的结果,说明 Gradio 服务启动成功,在本地浏览器中输入 127.0.0.1:7860 打开茴香豆助手测试页面:[
现在就可以用页面测试一下茴香豆的交互效果了。
正例的效果很好(从good-question中找的正例):
找到了对应信息所在的md文件,并做了提示。
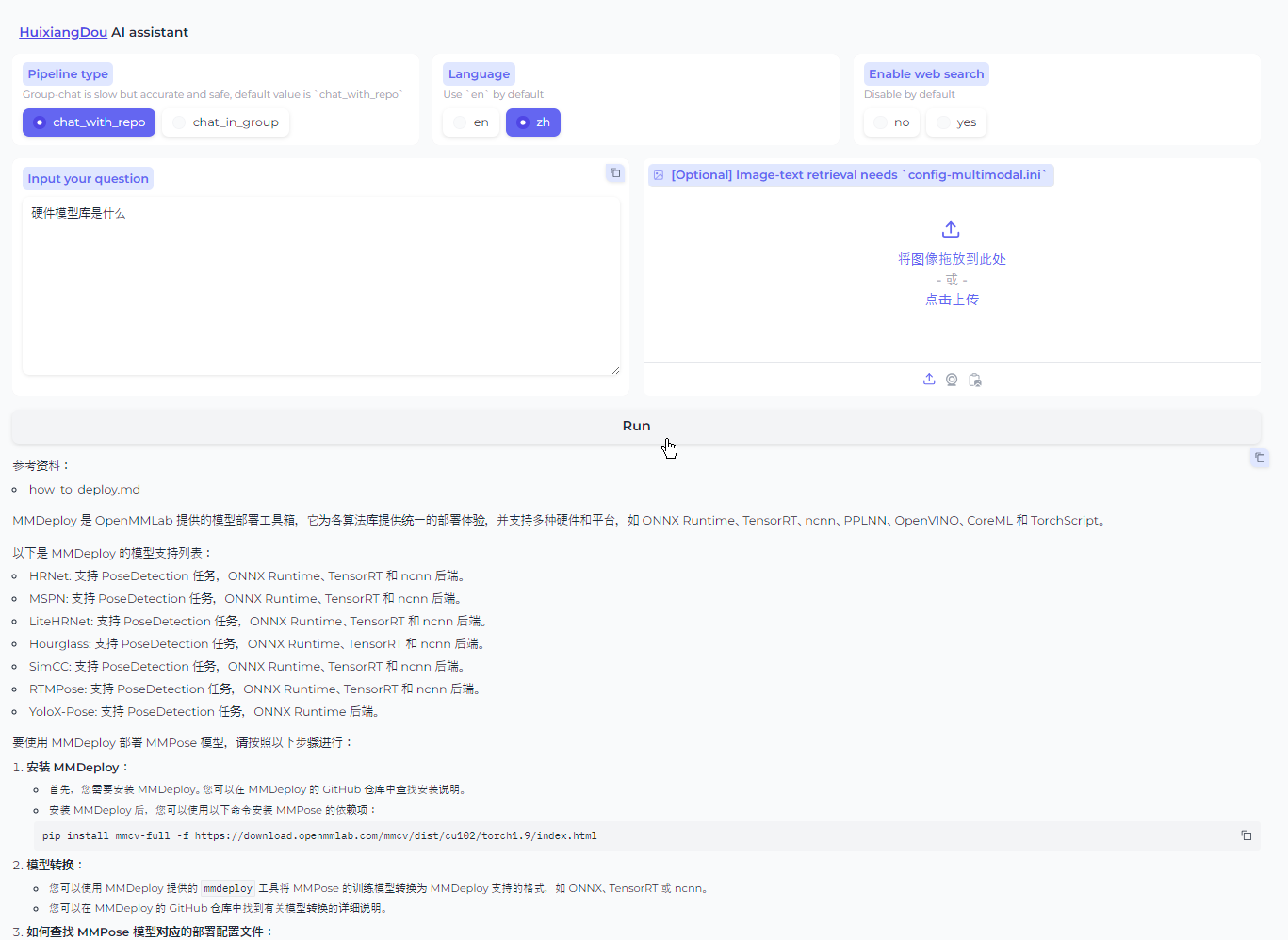
反例的效果却感觉一般
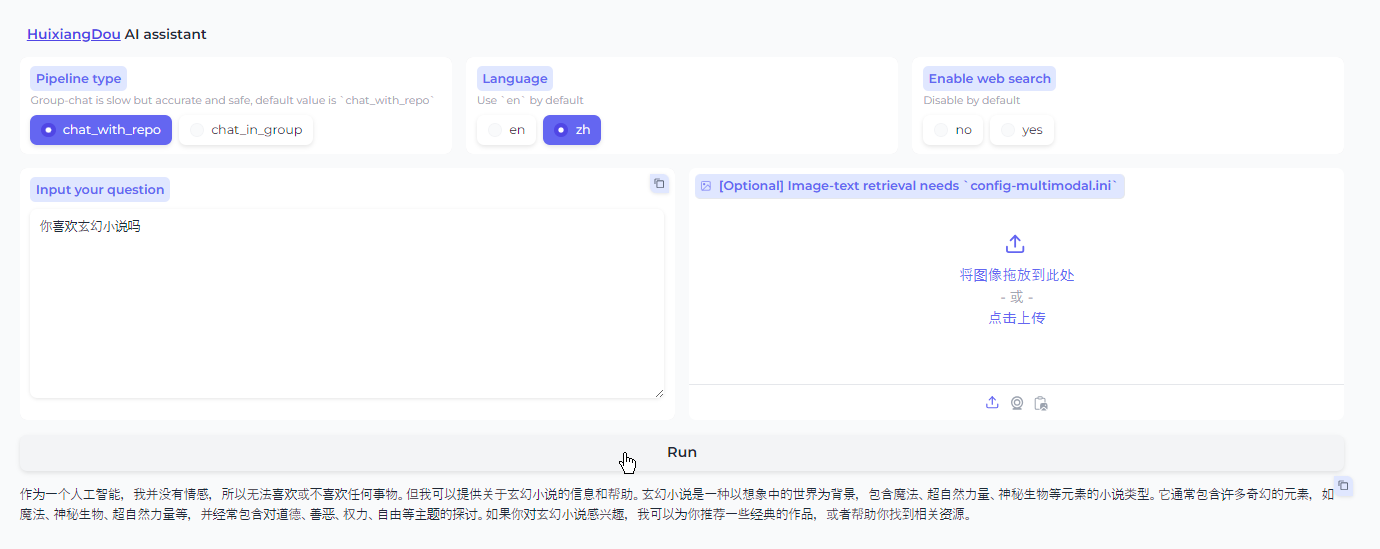
测试了以下反例(新增和既有反例),没有拒绝回答,看起来直接通过LLM自然回答了。需要进一步的调整反例再试试。
你喜欢玄幻小说吗(为测试追加的问题)
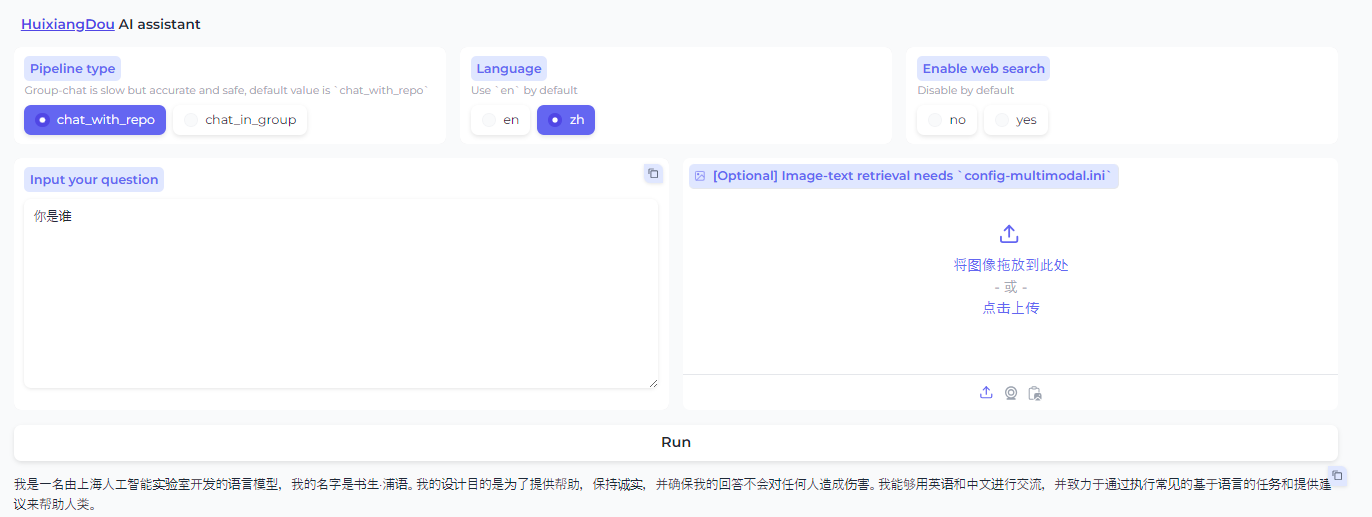
你是谁
2.5 集成飞书&微信群聊
本地版茴香豆的群集成和 Web 版一样,需要有公网 IP 的服务器,微信仅支持特定 Android 版本。
飞书集成:
pip install -r requirements-lark-group.txt- 教程 https://github.com/InternLM/HuixiangDou/blob/main/docs/add_lark_group_zh.md
3 茴香豆高阶应用
茴香豆拥有者丰富的功能,可以应对不同企业的需求,下面介绍几个真实场景中常用的高阶功能。
3.1 开启网络搜索
对于本地知识库没有提到的问题或是实时性强的问题,可以开启茴香豆的网络搜索功能,结合网络的搜索结果,生成更可靠的回答。
开启网络搜索功能需要用到 Serper 提供的 API:
- 登录 Serper ,注册:
- 进入 Serper API 界面,复制自己的 API-key:
 替换
替换 /huixiangdou/config.ini 中的 ${YOUR-API-KEY} 为自己的API-key:
[web_search]
check https://serper.dev/api-key to get a free API key
x_api_key = "${YOUR-API-KEY}"
domain_partial_order = ["openai.com", "pytorch.org", "readthedocs.io", "nvidia.com", "stackoverflow.com", "juejin.cn", "zhuanlan.zhihu.com", "www.cnblogs.com"]
save_dir = "logs/web_search_result"
其中 domain_partial_order 可以设置网络搜索的范围。
3.2 远程模型
除了将 LLM 模型下载到本地,茴香豆还可以通过调用远程模型 API 的方式实现知识问答助手。支持从 CPU-only、2G、10G、20G、到 80G 不同的硬件配置,满足不同规模的企业需求。
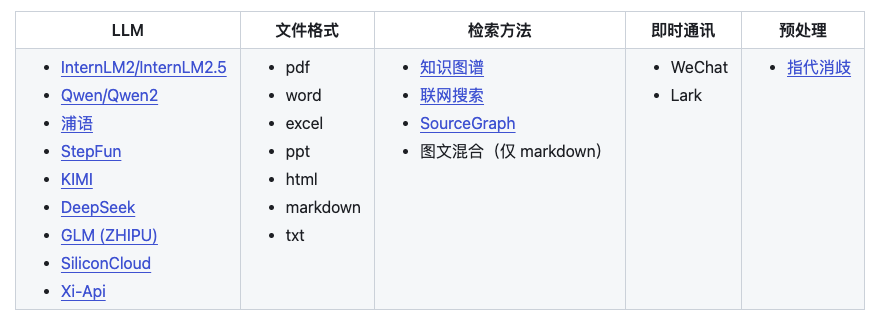
茴香豆中有 3 处调用了模型,分别是 嵌入模型(Embedding)、重排模型(Rerank)和 大语音模型(LLM)。
3.2.1 远程向量&重排序模型
其中特征提取部分(嵌入、重排)本地运行需要 2G 显存。如果运行的服务器没有显卡,也可以选择调用硅基流动 的 API。
- 登录 SiliconFlow 官网注册账号。
- 登录后,进入体验中心 ,复制个人 API 密匙:
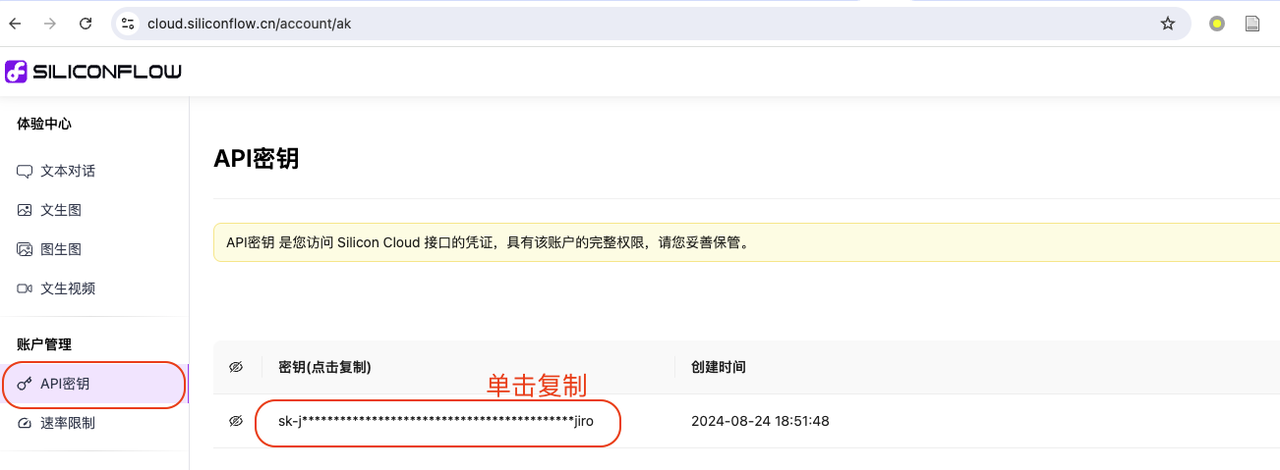
- 将 API,填入到
/huixiangdou/config.ini文件中api_token处,同时注意如图所示修改嵌入和重排模型地址(embedding_model_path,reranker_model_path):

目前茴香豆只支持 siliconflow 中向量&重排 bce 模型的调用,后续会增加其他向量&重排模型的支持。
3.2.2 远程大模型
想要启用远端大语言模型,首先修改 /huixiangdou/config.ini 本地和远程LLM 开关:
enable_local = 0 # 关闭本地模型
enable_remote = 1 # 启用云端模型
接着,如下图所示,修改 remote_ 相关配置,填写 API key、模型类型等参数,茴香豆支持 OpenAI 的 API格式调用。
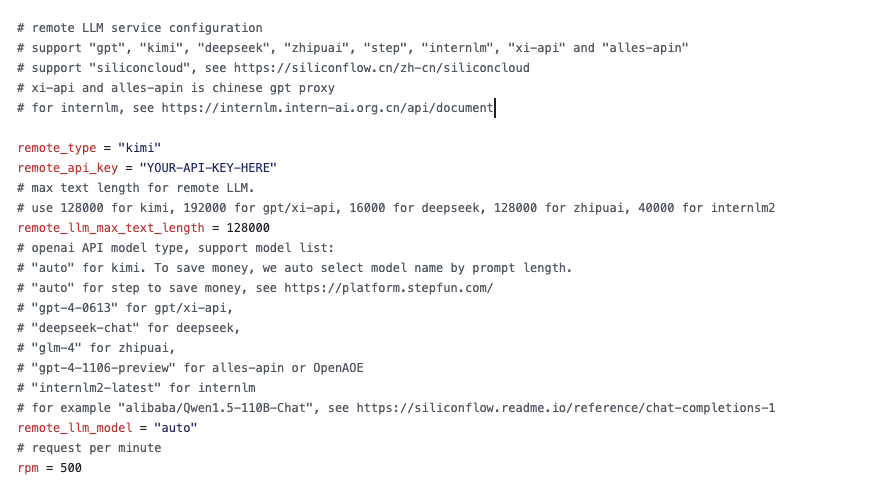
| 远程大模型配置选项 | GPT | Kimi | Deepseek | ChatGLM | Stepfun | InternLM | Siliconcloud | xi-api | alles-apin |
|---|---|---|---|---|---|---|---|---|---|
remote_type | gpt | kimi | deepseek | zhipuai | step | internlm | - | xi-api | alles-apin |
remote_llm_max_text_length | |||||||||
| 最大值 | 192000 | 128000 | 16000 | 128000 | - | 40000 | - | 192000 | - |
remote_llm_model | “gpt-4-0613” | “auto” | “deepseek-chat” | “glm-4” | “auto” | “internlm2-latest” | - | “gpt-4-0613” | “gpt-4-1106-preview” |
remote_llm_model为 “auto” 时,会根据提示词长短选择模型大小,以节省开支- Siliconcloud 支持的模型请查看 https://siliconflow.cn/zh-cn/models
如果同时开启 local 和 remote 模型,茴香豆将采用混合模型的方案,详见 技术报告,效果更好。















 334
334

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









