







正则表达式
正则表达式并不是Python的一部分,正则表达式是用于处理字符串的强大工具。
正则表达式的大致-匹配过程是:一次拿出表达式和文本中的字符比较,如果每一个字符都能匹配,则匹配成功;一旦有匹配不成功的字符则匹配失败。
Python支持的正则表达式元字符和语法:
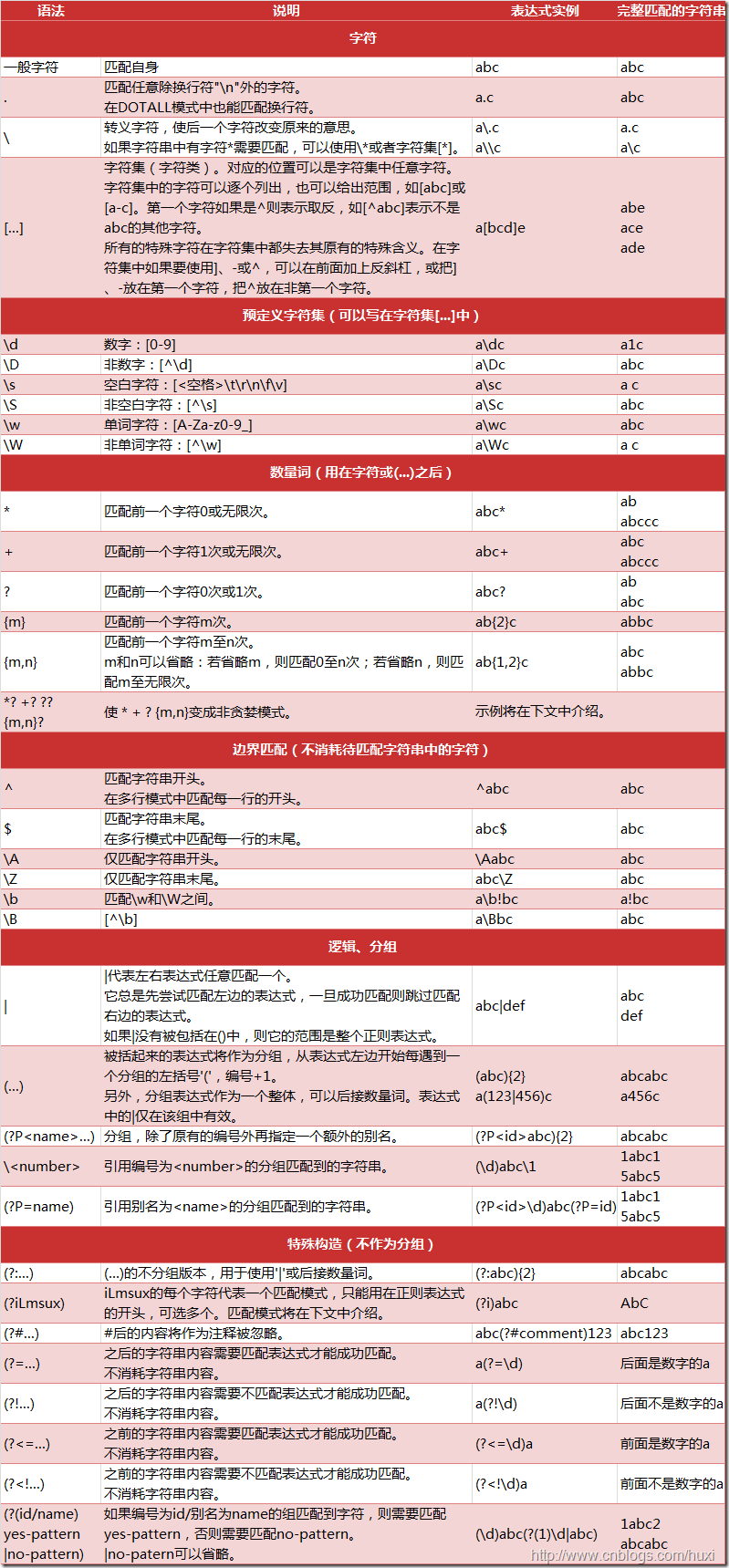
字符匹配:(普通字符,元字符)
格式:
import re
re.findall(正则规则,匹配的字符串)普通字符:数字和字符串本身
import re
print(re.findall('xiao', 'daxiaoming'))
['xiao']元字符及其用法:
. #匹配任意一个字符
>>> re.findall('a.b','a2b')
['a2b']
^ #以什么什么字符开头,写在字符前面
>>> re.findall('^1a', '1a2b')
['1a']
$ #以什么什么字符结尾,写在字符后面
>>> re.findall('f2$', 'adf2')
['f2']
* #匹配最少0次到无数次
>>> re.findall('f*', 'daafsdsafff')
['', '', '', 'f', '', '', '', '', 'fff', '']
+ #匹配最少1此到无数次
>>> re.findall('f+', 'daafsdsafff')
['f', 'fff']
? #匹配最少0次到1次
>>> re.findall('f?', 'daafsdsafff')
['', '', '', 'f', '', '', '', '', 'f', 'f', 'f', '']
{N} #匹配大括号里N次,{0:10}匹配0到10次;{3:}匹配最少3次到无限次
>>> re.findall('f{2}', 'daafsdsafff')
['ff']
[] #用来指定一个字符集,[ab]匹配a或b,其他特殊字符在[]中不起作用,除了"-"和“……”
>>> re.findall('[as]', 'daafsdsafff')
['a', 'a', 's', 's', 'a']
| #或
>>> re.findall('d|s', 'daafsdsafff')
['d', 's', 'd', 's']
() #分组,第一个组号为1
>>> re.findall('(aa)(fs)', 'daafsdsafff')
[('aa', 'fs')]
\ #转义符
>>> re.findall('\*f', 'daa*fsdsafff')
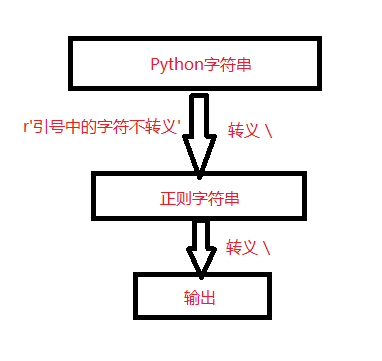
['*f']转义符在Python环境中转入正则的时候,需要经过转义,在正则里面对字符转义的时候也需要用到转义符。为了为了使代码更简洁,Pyhon里通过用r”表示原有字符,r” 引号中的字符在在Python中不被看做成转义。
特殊字符
\d #匹配任何数字;与 [0-9] 相同
\D #匹配任何非数字字符;与 [^0-9] 相同
\s #匹配任何空白字符;与 [\t\n\r\f\v] 相同
\S #匹配任何非空白字符;与 [^\t\n\r\f\v] 相同
\w #匹配任何字符数字和下划线:与 [a-zA-Z0-9_] 相同
\W #匹配任何非字符数字下划线的特殊字符;与 [^a-zA-Z0-9_] 相同
\b #匹配一个单词边界,也就是指单词和空格间的距离
“ .* ” #代表除换行符以外所有的字符
例子1:
匹配电话号:
p = re.compile(r'\d{3}-\d{6}')
print(p.findall('010-847501'))例2:
匹配网址:
www = "www.baidu.com"
print(re.findall(r'\w+\.w+\.com', www))例3:
取浮点数:
>>> print(re.findall(r'\d+\.\d*','100.01'))
['100.01']
只取小数位
>>> print(re.findall(r'\d+(\.\d*)','num 10.01'))
['.01']贪婪匹配:
尽可能多的匹配所有的与自己相关的字符
re内置模块
match()
从头匹配,匹配到第一个符合规则的字符串后停止
按匹配类型来分类把正则匹配分成有分组的情况和无分组的情况。
正则中有三个对象用来接收他的匹配结果
.group() #获取匹配到的所有结果
.groups() #获取模型中匹配到的分组结果
.groupdict() #获取模块中匹配到的分组结果,取名字以后以字典的形式表示
.group():把匹配到的结果赋值给它
- 情况1:无分组情况
origin = "hello world nong sha lei"
r = re.match("(h)(\w+)", origin)
print(r.group()) #获取匹配到的所有结果
print(r.groups()) #获取模型中匹配到的分组结果
print(r.groupdict()) #获取模块中匹配到的分组结果例子
.group()
origin = "hello world nong sha lei"
r = re.match("h\w+", origin)
print(r.group())
匹配项内没有分组,匹配到的结果就会赋值给.group()情况2:有分组
- ?P<> :固定搭配,尖括号里面定义key的名字,只有这种方式才能把内容定义到dict里面
分组的作用
提取匹配成功的制定内容(先匹配成功全部正则,再匹配局部内容并提出),如果有分组的话,会只提取分组中的内容
origin = "hello world nong sha lei"
r = re.match("(?P<n1>h)(?P<n2>\w+)", origin)
print(r.group()) #获取匹配到的所有结果
print(r.groups()) #获取模型中匹配到的分组结果
print(r.groupdict()) #获取模块中匹配到的分组结果例子
.groups()
origin = "hello world nong sha lei"
r = re.match("(h)(\w+)", origin)
print(r.groups())匹配项中有分组,就把结果赋值给 .groups()
origin = "hello world nong sha lei"
r = re.match("(?P<NAME>h)(\w+)", origin)
print(r.groupdict())search()
浏览全部字符串,匹配到第一个符合规则的字符串后停止
a = "a1b2c3d5"
d = re.search("\d\w\d", a)
print(d.group())findall()
将匹配到的所有内容放置到一个列表中
匹配顺序:
- findall() 匹配到一个符合类型以后,再从后面的字符开始匹配
- 正则中分组如果取相邻的重复的值,默认只会取最后一个值。
- 用*号贪婪匹配时,取到最后一位的时候会继续匹配,但这是最后一位已经没有了,所以就会取一个空值。
a = "a1b2c3d5"
d = re.findall("\d\w\d", a)
print(d.group())split()
以指定的字符或字符串来分隔
- 无分组的情况下,分隔的本身不包含
split还可以指定最多分隔几次
origin = "hello alex bcd abcd "
n = re.split("a", origin, 1) #最后的1参数表示分隔一次
print(n)- 有分组的情况下,分隔的本身才被包含
origin = "hello alex bcd abcd "
n = re.split("a(\w+)", origin, 1)
print(n).sub()
查找替换
.subn #默认匹配两项
origin = "hello alex bcd abcd "
n = re.sub("a(\w+)", "XXX", origin, 1)#匹配字符,替换结果,替换内容,替换次数
print(n)














 538
538

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









