







多核多线程 自旋锁(spinlock )与 互斥量(mutex)
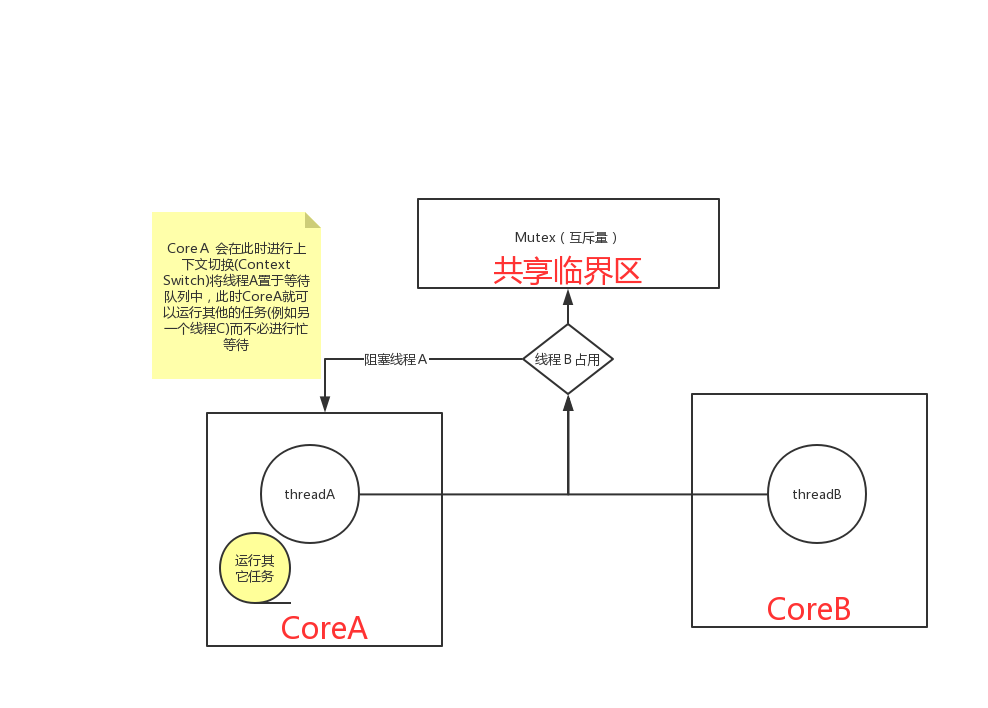
mutex方式:(sleep-wait)
从实现原理上来讲,Mutex属于sleep-waiting类型的锁。例如在一个双核的机器上有两个线程(线程A和线程B),它们分别运行在Core0和Core1上。假设线程A想要通过pthread_mutex_lock操作去得到一个临界区的锁,而此时这个锁正被线版程B所持有,那么线程A就会被阻塞(blocking),Core0 会在此时进行上下文切换(Context Switch)将线程A置于等待队列中,权此时Core0就可以运行其他的任务(例如另一个线程C)而不必进行忙等待。
Mutex适合对锁操作非常频繁,临界区较大的场景,并且具有更好的适应性。
对锁操作非常频繁:
例如测试程序关键代码,每获取一次锁,执行 100000次 累加 操作(临界区较大),耗时比较长
//--每获取一次锁,执行 100000次 累加 操作
//--耗时比较长
for (j = 0; j < 100000; j++) {
//--打印优先完成的线程ID
if (g_count++ == 123456789){
printf("Thread %lu wins!\n", (unsigned long)gettid());
}
}
尽管相比spin lock它会花费更多的开销(主要是上下文切换),但是它能适合实际开发中复杂的应用场景,在保证一定性能的前提下提供更大的灵活度。
消耗时间的地方:(系统调用,mutex会在锁冲突时调用system wait)
上下文切换对已经拿着锁的那个线程性能也是有影响的,因为当该线程释放该锁时它需要通知操作系统去唤醒那些被阻塞的线程
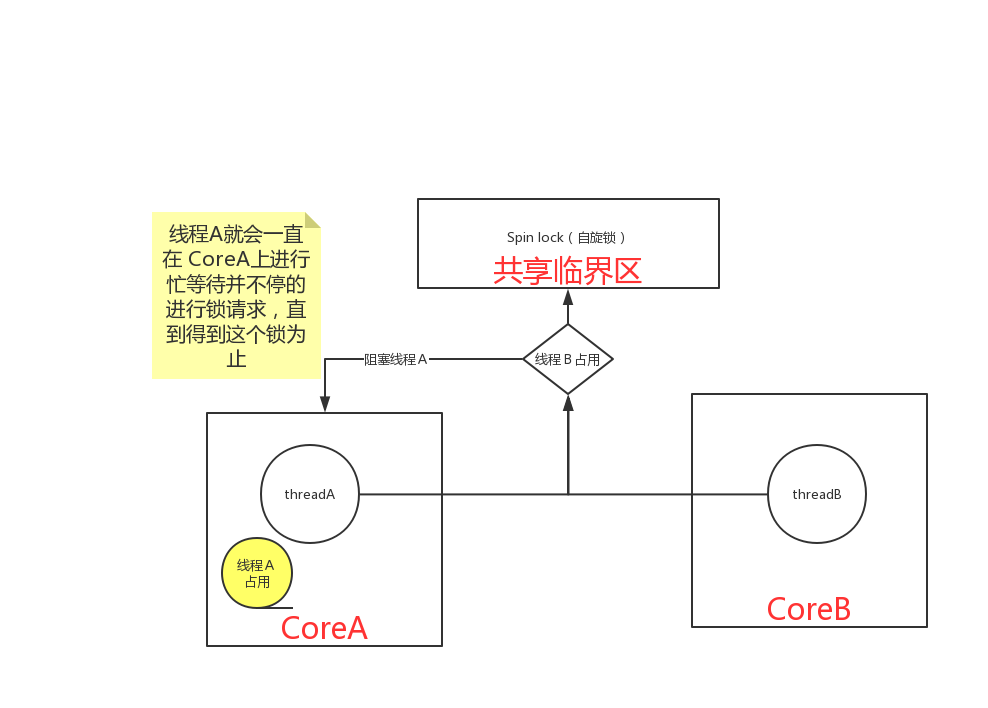
spinlock 方式:(busy-wait)
spin lock 性能更好(花费更少的cpu指令),但是它只适应用于临界区运行时间很短的场景。
临界区运行时间很短:
例如测试程序关键线程代码,每获取一次锁,执行 1次 赋值和 pop_front 操作,耗时非常短
//---取出列表第一个值
//--每获取一次锁,执行 1次 赋值和 pop_front 操作
//--耗时非常短
i = the_list.front();
the_list.pop_front();
而在实际软件开发中,除非程序员对自己的程序的锁操作行为非常的了解,否则使用spin lock不是一个好主意。
通常一个多线程程序中对锁的操作有数以万次,如果失败的锁操作(contended lock requests)过多的话就会浪费很多的时间进行空等待。
消耗时间的地方:
两个线程分别运行在两个核上,大部分时间只有一个线程能拿到锁,所以另一个线程就一直在它运行的core上进行忙等待,CPU占用率一直是100%
而在实际软件开发中,除非程序员对自己的程序的锁操作行为非常的了解,否则使用spin lock不是一个好主意。
通常一个多线程程序中对锁的操作有数以万次,如果失败的锁操作(contended lock requests)过多的话就会浪费很多的时间进行空等待。
消耗时间的地方:
两个线程分别运行在两个核上,大部分时间只有一个线程能拿到锁,所以另一个线程就一直在它运行的core上进行忙等待,CPU占用率一直是100%
而在实际软件开发中,除非程序员对自己的程序的锁操作行为非常的了解,否则使用spin lock不是一个好主意。
通常一个多线程程序中对锁的操作有数以万次,如果失败的锁操作(contended lock requests)过多的话就会浪费很多的时间进行空等待。
消耗时间的地方:
两个线程分别运行在两个核上,大部分时间只有一个线程能拿到锁,所以另一个线程就一直在它运行的core上进行忙等待,CPU占用率一直是100%
测试代码(临界区运行时间很短):
1 编译spin lock版本 : g++ -o spin_version -DUSE_SPINLOCK spinlockvsmutex1.cc -lpthread
2 编译mutex 版本 : g++ -o mutex_version spinlockvsmutex1.cc -lpthread
// Name: spinlockvsmutex1.cc
// Source: http://www.alexonlinux.com/pthread-mutex-vs-pthread-spinlock
// Compiler(spin lock version): g++ -o spin_version -DUSE_SPINLOCK spinlockvsmutex1.cc -lpthread
// Compiler(mutex version): g++ -o mutex_version spinlockvsmutex1.cc -lpthread
#include <stdio.h>
#include <unistd.h>
#include <sys/syscall.h>
#include <errno.h>
#include <sys/time.h>
#include <list>
#include <pthread.h>
#define LOOPS 50000000
using namespace std;
list<int> the_list;
//-- spinlock 或者 mutex
#ifdef USE_SPINLOCK
pthread_spinlock_t spinlock;
#else
pthread_mutex_t mutex;
#endif
//Get the thread id
pid_t gettid() { return syscall( __NR_gettid ); }
void *consumer(void *ptr)
{
int i;
//--打印线程ID
printf("Consumer Thread ID %lu\n", (unsigned long)gettid());
while (1)
{
#ifdef USE_SPINLOCK
pthread_spin_lock(&spinlock);
#else
pthread_mutex_lock(&mutex);
#endif
//--列表为空,结束
if (the_list.empty())
{
#ifdef USE_SPINLOCK
pthread_spin_unlock(&spinlock);
#else
pthread_mutex_unlock(&mutex);
#endif
break;
}
//---取出列表第一个值
//--每获取一次锁,执行 1次 赋值和 pop_front 操作
//--耗时非常短
i = the_list.front();
the_list.pop_front();
#ifdef USE_SPINLOCK
pthread_spin_unlock(&spinlock);
#else
pthread_mutex_unlock(&mutex);
#endif
}
return NULL;
}
int main()
{
int i;
pthread_t thr1, thr2;
struct timeval tv1, tv2;
#ifdef USE_SPINLOCK
pthread_spin_init(&spinlock, 0);
#else
pthread_mutex_init(&mutex, NULL);
#endif
// Creating the list content...
//--生产者,创建列表内容
for (i = 0; i < LOOPS; i++)
the_list.push_back(i);
// Measuring time before starting the threads...
//--启动线程前时间
gettimeofday(&tv1, NULL);
//--创建两个消费者线程
pthread_create(&thr1, NULL, consumer, NULL);
pthread_create(&thr2, NULL, consumer, NULL);
//--主线程等待两个消费者线程结束
pthread_join(thr1, NULL);
pthread_join(thr2, NULL);
// Measuring time after threads finished...
//--线程结束时间
gettimeofday(&tv2, NULL);
if (tv1.tv_usec > tv2.tv_usec)
{
tv2.tv_sec--;
tv2.tv_usec += 1000000;
}
//--打印耗时
printf("Result - %ld.%ld\n", tv2.tv_sec - tv1.tv_sec,
tv2.tv_usec - tv1.tv_usec);
#ifdef USE_SPINLOCK
pthread_spin_destroy(&spinlock);
#else
pthread_mutex_destroy(&mutex);
#endif
return 0;
}
运行
wmx@wmx-ubuntu:~/workspace/Multi-core scheduling/spinlockvsmutex1$ time ./mutex_version
Consumer TID 17599
Consumer TID 17600
Result - 23.863041
real 0m26.455s
user 0m30.596s
sys 0m19.712s
wmx@wmx-ubuntu:~/workspace/Multi-core scheduling/spinlockvsmutex1$ time ./spin_version
Consumer TID 17606
Consumer TID 17607
Result - 3.743531
real 0m6.293s
user 0m9.719s
sys 0m0.317s
可以看见spin lock的版本在该程序中表现出来的性能更好。另外值得注意的是sys时间,mutex版本花费了更多的系统调用时间,这就是因为mutex会在锁冲突时调用system wait造成的。
测试代码(锁冲突程度非常剧烈的实例程序):
//Name: svm2.c
//Source: http://www.solarisinternals.com/wiki/index.php/DTrace_Topics_Locks
//Compile(spin lock version): gcc -o spin -DUSE_SPINLOCK svm2.c -lpthread
//Compile(mutex version): gcc -o mutex svm2.c -lpthread
#include <stdio.h>
#include <stdlib.h>
#include <pthread.h>
#include <sys/syscall.h>
//--线程数量
#define THREAD_NUM 2
pthread_t g_thread[THREAD_NUM];
//-- spinlock 或者 mutex
#ifdef USE_SPINLOCK
pthread_spinlock_t g_spin;
#else
pthread_mutex_t g_mutex;
#endif
__uint64_t g_count;
pid_t gettid()
{
return syscall(SYS_gettid);
}
void *run_amuck(void *arg)
{
int i, j;
//--打印线程ID
printf("Thread %lu started.\n", (unsigned long)gettid());
//--10000次请求锁
for (i = 0; i < 10000; i++) {
#ifdef USE_SPINLOCK
pthread_spin_lock(&g_spin);
#else
pthread_mutex_lock(&g_mutex);
#endif
//--每获取一次锁,执行 100000次 累加 操作
//--耗时比较长
for (j = 0; j < 100000; j++) {
//--打印优先完成的线程ID
if (g_count++ == 123456789){
printf("Thread %lu wins!\n", (unsigned long)gettid());
}
}
#ifdef USE_SPINLOCK
pthread_spin_unlock(&g_spin);
#else
pthread_mutex_unlock(&g_mutex);
#endif
}
//--打印线程ID
printf("Thread %lu finished!\n", (unsigned long)gettid());
return (NULL);
}
int main(int argc, char *argv[])
{
int i, threads = THREAD_NUM;
//--打印线程数量
printf("Creating %d threads...\n", threads);
//-- spinlock 或者 mutex
#ifdef USE_SPINLOCK
pthread_spin_init(&g_spin, 0);
#else
pthread_mutex_init(&g_mutex, NULL);
#endif
for (i = 0; i < threads; i++)
pthread_create(&g_thread[i], NULL, run_amuck, (void *) i);
/*!
* @brief pthread_join
* 主线程会一直等待直到等待的线程结束自己才结束
* 对线程的资源进行回收
*/
for (i = 0; i < threads; i++)
pthread_join(g_thread[i], NULL);
printf("Done.\n");
return (0);
}
测试
wmx@wmx-ubuntu:~/workspace/Multi-core scheduling/spinlockvsmutex2$ time ./mutex
Creating 2 threads...
Thread 18389 started.
Thread 18390 started.
Thread 18389 wins!
Thread 18389 finished!
Thread 18390 finished!
Done.
real 0m3.150s
user 0m3.202s
sys 0m0.020s
wmx@wmx-ubuntu:~/workspace/Multi-core scheduling/spinlockvsmutex2$ time ./spin
Creating 2 threads...
Thread 18403 started.
Thread 18404 started.
Thread 18403 wins!
Thread 18403 finished!
Thread 18404 finished!
Done.
real 0m3.107s
user 0m4.641s
sys 0m0.004s
这个程序的特征就是临界区非常大,这样两个线程的锁竞争会非常的剧烈。当然这个是一个极端情况,实际应用程序中临界区不会如此大,锁竞争也不会如此激烈。测试结果显示mutex版本性能更好
spin lock耗费了更多的user time。这就是因为两个线程分别运行在两个核上,大部分时间只有一个线程能拿到锁,所以另一个线程就一直在它运行的core上进行忙等待,CPU占用率一直是100%
自旋锁是一种非阻塞锁,也就是说,如果某线程需要获取自旋锁,但该锁已经被其他线程占用时,该线程不会被挂起,而是在不断的消耗CPU的时间,不停的试图获取自旋锁。
互斥量是阻塞锁,当某线程无法获取互斥量时,该线程会被直接挂起,该线程不再消耗CPU时间,当其他线程释放互斥量后,操作系统会激活那个被挂起的线程,让其投入运行。
两种锁适用于不同场景:
如果是多核处理器,如果预计线程等待锁的时间很短,短到比线程两次上下文切换时间要少的情况下,使用自旋锁是划算的。
如果是多核处理器,如果预计线程等待锁的时间较长,至少比两次线程上下文切换的时间要长,建议使用互斥量。
如果是单核处理器,一般建议不要使用自旋锁。因为,在同一时间只有一个线程是处在运行状态,那如果运行线程发现无法获取锁,只能等待解锁,但因为自身不挂起,所以那个获取到锁的线程没有办法进入运行状态,只能等到运行线程把操作系统分给它的时间片用完,才能有机会被调度。这种情况下使用自旋锁的代价很高。
如果加锁的代码经常被调用,但竞争情况很少发生时,应该优先考虑使用自旋锁,自旋锁的开销比较小,互斥量的开销较大。
参考文献
《多核程序设计技术》
《linux内核设计与实现》
自旋锁是一个互斥设备,它只有两个值:“锁定”和“解锁”。它通常实现为某个整数值中的某个位。希望获得某个特定锁得代码测试相关的位。如果锁可用,则“锁定”被设置,而代码继续进入临界区;相反,如果锁被其他人获得,则代码进入忙循环(而不是休眠,这也是自旋锁和一般锁的区别)并重复检查这个锁,直到该锁可用为止,这就是自旋的过程。“测试并设置位”的操作必须是原子的,这样,即使多个线程在给定时间自旋,也只有一个线程可获得该锁。
自旋锁最初是为了在多处理器系统(SMP)使用而设计的,但是只要考虑到并发问题,单处理器在运行可抢占内核时其行为就类似于SMP。因此,自旋锁对于SMP和单处理器可抢占内核都适用。可以想象,当一个处理器处于自旋状态时,它做不了任何有用的工作,因此自旋锁对于单处理器不可抢占内核没有意义,实际上,非抢占式的单处理器系统上自旋锁被实现为空操作,不做任何事情。
自旋锁有几个重要的特性:1、被自旋锁保护的临界区代码执行时不能进入休眠。2、被自旋锁保护的临界区代码执行时是不能被被其他中断中断。3、被自旋锁保护的临界区代码执行时,内核不能被抢占。从这几个特性可以归纳出一个共性:被自旋锁保护的临界区代码执行时,它不能因为任何原因放弃处理器。
考虑上面第一种情况,想象你的内核代码请求到一个自旋锁并且在它的临界区里做它的事情,在中间某处,你的代码失去了处理器。或许它已调用了一个函数(copy_from_user,假设)使进程进入睡眠。也或许,内核抢占发威,一个更高优先级的进程将你的代码推到了一边。此时,正好某个别的线程想获取同一个锁,如果这个线程运行在和你的内核代码不同的处理器上(幸运的情况),那么它可能要自旋等待一段时间(可能很长),当你的代码从休眠中唤醒或者重新得到处理器并释放锁,它就能得到锁。而最坏的情况是,那个想获取锁得线程刚好和你的代码运行在同一个处理器上,这时它将一直持有CPU进行自旋操作,而你的代码是永远不可能有任何机会来获得CPU释放这个锁了,这就是悲催的死锁。
考虑上面第二种情况,和上面第一种情况类似。假设我们的驱动程序正在运行,并且已经获取了一个自旋锁,这个锁控制着对设备的访问。在拥有这个锁得时候,设备产生了一个中断,它导致中断处理例程被调用,而中断处理例程在访问设备之前,也要获得这个锁。当中断处理例程和我们的驱动程序代码在同一个处理器上运行时,由于中断处理例程持有CPU不断自旋,我们的代码将得不到机会释放锁,这也将导致死锁。
因此,如果我们有一个自旋锁,它可以被运行在(硬件或软件)中断上下文中的代码获得,则必须使用某个禁用中断的spin_lock形式的锁来禁用本地中断(注意,只是禁用本地CPU的中断,不能禁用别的处理器的中断),使用其他的锁定函数迟早会导致系统死锁(导致死锁的时间可能不定,但是发生上述死锁情况的概率肯定是有的,看处理器怎么调度了)。如果我们不会在硬中断处理例程中访问自旋锁,但可能在软中断(例如,以tasklet的形式运行的代码)中访问,则应该使用spin_lock_bh,以便在安全避免死锁的同时还能服务硬件中断。
补充:
锁定一个自旋锁的函数有四个:
void spin_lock(spinlock_t *lock);
最基本得自旋锁函数,它不失效本地中断。
void spin_lock_irqsave(spinlock_t *lock, unsigned long flags);
在获得自旋锁之前禁用硬中断(只在本地处理器上),而先前的中断状态保存在flags中
void spin_lockirq(spinlock_t *lock);
在获得自旋锁之前禁用硬中断(只在本地处理器上),不保存中断状态
void spin_lock_bh(spinlock_t *lock);
在获得锁前禁用软中断,保持硬中断打开状态
————————————————
版权声明:本文为CSDN博主「vivi」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/vividonly/article/details/6594195
————————————————
版权声明:本文为CSDN博主「swordmanwk」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/swordmanwk/article/details/6819457
————————————————
版权声明:本文为CSDN博主「科技ing」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/WMX843230304WMX/article/details/100052812

















 824
824

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









