






我又回来了我。从开学到现在仔细想想干了点啥,嗯。。。。。没啥。一直想着补博客,然后就想着。。刚为祖国大人庆完生,又被老妈拽去地里各种折腾,回来都不想动脑子,不想不想不想,啊。。。。。还是补博客吧。
说说要达到的目标:
就是获取六个热门城市中数据挖掘职位的招聘职位、职位要求、面试评价等,最后转存为json格式。
遇到的问题大概就是模拟登陆和验证码识别两大块问题吧。
前提啊,我代码写的不好,没怎么测试,所以~~~~~~~~~~。还请大神们谅解,我还很菜。
崔大大的博客里应该有一篇关于phantomjs和selenium结合使用的文章,http://cuiqingcai.com/2577.html
1,介绍一下phantomjs
简单来说,它就是一个无界面的,可脚本编程的WebKit浏览器引擎。
借鉴一下人家说的,忘记从哪弄来的了。
(1)一个基于webkit内核的无头浏览器,即没有UI界面,即他就是一个浏览器,只是其内的点击、翻页等人为相关操作需要程序设计实现。
(2)提供JavaScript API接口,即通过编写js程序可以直接与webkit内核交互,在此之上可以结合Java语言等,通过java调用js等相关操作。从而解决了以前c/c++才能比较好的机遇webkit开发优质采集器的限制。
(3)提供Windows、Linux、mac等不同os的安装使用包,也就是说可以在不同平台上二次开发采集项目或是自动项目测试等工作。
phantomjs可以干什么?
无UI界面的网站测试
屏幕快照
页面操作自动化
网络监控
下载安装也很简单,直接找到相应的版本phantomjs.exe直接可用。
这里就是主要用它来当一个浏览器使用,稍微提高一下速度。
2.介绍一下selenium
selenium 是一个 web 的自动化测试工具,selenium 测试直接在浏览器中运行,就像真实用户所做的一样。
以前用过selenium实现漫画的自动翻页,看的野良神,嘿嘿嘿。不过仅此而已,没有深入玩过。
有一本书(selenium_webdriver(python)第一版.pdf),可以参照练练手。
可以直接用pip安装,很简单。啊,我说的都是在Windows下。
3.我们开始吧。
主要流程:

接下来:

定位好地点,点击进入详细页面:
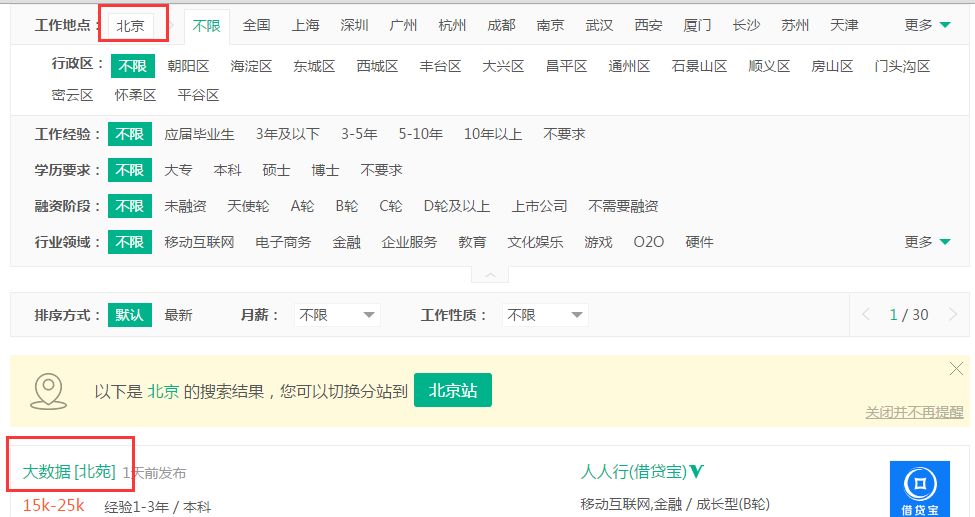
需要获取的内容:
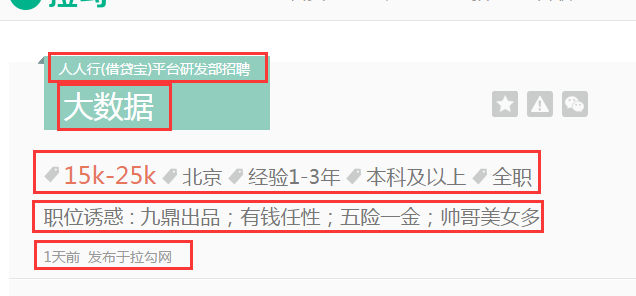
下拉还有面试评价,有的有评价,有的没有评价:
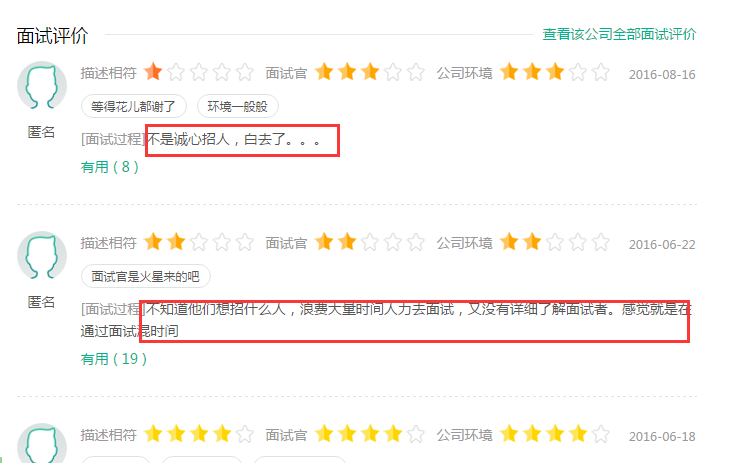
下面就开始写代码了呀。
访问频繁了会出现验证码,我一开始想着获取出现验证码的源代码,找出图片的链接,不过我看我的代码不是这么写的,所以,大概,或许,应该是因为这些验证码的图片是js加载的。。。。我真的。。忘了。。
因为对于识别验证码这方面没有什么经验,所以只能手动填写验证码。
全部代码:
<span style="font-size:18px;"># -*- coding:utf-8 -*-
import requests
from selenium import webdriver
import json
import time
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
user_agent = 'Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.106 Safari/537.36'
headers = {'User-Agent': user_agent}
driver = webdriver.PhantomJS(executable_path='D:\phantomjs-2.1.1-windows\\bin\phantomjs.exe')
loginurl = "https://passport.lagou.com/login/login.html"
# service_args = ['--proxy=101.72.117.223:8123', '--proxy-type=http', ]
# driver = webdriver.PhantomJS(executable_path='D:\phantomjs-2.1.1-windows\\bin\phantomjs.exe', service_args=service_args)
# driver = webdriver.Chrome(service_args=service_args)
# 模拟登陆
def Login():
driver.get(loginurl)
# 窗口最大化
driver.maximize_window()
driver.find_element_by_xpath('/html/body/section/div[1]/form/div/div[1]/input').clear()
driver.find_element_by_xpath('/html/body/section/div[1]/form/div/div[1]/input').send_keys('账号')
time.sleep(2)
driver.find_element_by_xpath('/html/body/section/div[1]/form/div/div[2]/input').clear()
driver.find_element_by_xpath('/html/body/section/div[1]/form/div/div[2]/input').send_keys('密码')
time.sleep(2)
driver.find_element_by_xpath('/html/body/section/div[1]/form/div/div[5]/input').click()
time.sleep(10)
# 如果出现验证码问题
def code():
# 获取当前页面的URL
current_url = driver.current_url
# print current_url
while current_url == loginurl:
# 截屏,为了获取验证码,在参数处找不到规律,直接截屏
driver.save_screenshot("yzm.png")
print '获取截图成功!'
# 手动填写验证码
print 'please input the verify code:'
verifycode = sys.stdin.readline()
driver.find_element_by_xpath('/html/body/section/div[1]/form/div/div[3]/input').clear()
driver.find_element_by_xpath('/html/body/section/div[1]/form/div/div[3]/input').send_keys(verifycode)
# 输入验证码之后,点击登录,若验证码错误,print。
try:
driver.find_element_by_xpath('/html/body/section/div[1]/form/div/div[5]/input').click()
print 'click success!'
except Exception, e:
print '验证码输入错误!', e
######
# 我突然发现一个问题,我没尝试过真的输错验证码,如果输错,那这个代码就应该有。。问题了。
# 应该再加上 删除后重新填写的 代码
######
time.sleep(5)
current_url = driver.current_url
print "哈哈哈,我登上了!"
# 获取招聘信息
def getItems():
# 获取cookies
cookies = "; ".join([item["name"] + "=" + item["value"] for item in driver.get_cookies()])
# 在头部信息里加入cookies
headers['cookie'] = cookies
requests.get(driver.current_url, headers=headers)
# 抓取6个主要城市
cities = ['成都', '广州', '深圳', '杭州', '上海', '北京']
for city in cities:
# data字典为最后获取的所有内容,方便转换为json格式,列表里是每个职位所获取的信息,一个城市对应一个列表
data = {}
list = []
driver.switch_to_window(driver.current_window_handle)
time.sleep(5)
# 在搜索框里输入关键词
driver.find_element_by_id('search_input').send_keys('大数据'.decode(encoding='utf-8'))
driver.find_element_by_id('search_button').click()
time.sleep(5)
driver.find_element_by_link_text(city).click()
time.sleep(5)
f = open(u"%s.json" % city, "w")
# 每个城市职位信息的页数不同,不一定都是30页,需要获取一下实际总页数
page_num = driver.find_element_by_class_name('totalNum').text
print page_num
for page in range(1, int(page_num)+1):
links = driver.find_elements_by_class_name('position_link')
time.sleep(5)
for link in links:
time.sleep(2)
link.click()
time.sleep(5)
# 切换句柄,因为页面是在新窗口打开的,获取的内容在新窗口,
# 下面用了一个if语句进行判断,如果还停留在当前页面,就切换一下
current_handle = driver.current_window_handle
all_handles = driver.window_handles
for handle in all_handles:
if handle != current_handle:
driver.switch_to_window(handle)
time.sleep(5)
company = driver.find_element_by_xpath('//*[@id="job_detail"]/dt/h1').text
company = company.replace('\n', ' ')
job_request = driver.find_element_by_class_name('job_request').text
job_request = job_request.replace("职位诱惑 : ",'')
job_request = job_request.split('\n')
pingjia = driver.find_elements_by_class_name('interview-process')
content = {}
# print company, job_request[0], job_request[1], job_request[2]
# 在字典中添加所获取的内容
content['招聘职位'] = company
content['职位要求'] = job_request[0]
content['职位诱惑'] = job_request[1]
content['发布时间'] = job_request[2]
# 面试评价有的没有,有的是多条。
if pingjia:
for each in pingjia:
print each.text
each_text = each.text.split('\n')
print each_text
content['面试评价'] = each_text
else:
print "暂无评价"
content['面试评价'] = ["暂无评价"]
list.append(content)
driver.close()
time.sleep(3)
# 这一步是 获取完这一页的信息,再返回前一页,点击下一个职位链接
driver.switch_to_window(current_handle)
time.sleep(2)
driver.find_element_by_class_name('pager_next ').click()
time.sleep(5)
# print "第"+str(page)+"页完成"
# data字典中用city对应list,并转换为json格式
data[city] = list
jsonData = json.dumps(data)
f.write(jsonData)
f.close()
# 返回首页,进行下一轮,再输入关键词,定位地点再来一遍。(是不是有点麻烦。。。)
driver.find_element_by_xpath('//*[@id="lg_tnav"]/div/ul/li[1]/a').click()
time.sleep(5)
Login()
code()
getItems()
</span>
我还有话说。。。
用phantomjs不会看到任何操作,我就换了谷歌看了看,然后,就会报错。
报错原因是定位不到元素,查了好多关于定位不到元素的原因,原来是因为元素没有出现在屏幕中,没出现在界面中(比如Button在页面底部,但是屏幕只能显示页面上半部分),使用默认的WebElement.Click()可能会触发不了Click事件,所以加了最大化再点击就成功了。
但是最大化后只能定位到屏幕中能显示的最后一个选项,也就是说滚动条它是自己不滚的,需要人为的加一段js代码让它滚起来,就像这样driver.execute_script(js代码)。但在phantomjs里我没有遇到这个问题。
还遇到了socket的问题,就出现了一次,后来又莫名其妙的消失了,我想应该是测试的还不够。
哦,我还发现了一个Python自带的验证码识别的包pytesser,不怎么好用。
哦,我还用scrapy爬了一下这个拉勾,好多问题,我得想想。
还请大家多提问题,我会多多改正滴。















 473
473

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









