







本文主要介绍python如何通过pyspark的API操作spark
Spark安装略,下载解压配置下就OK 我使用的是spark-2.2.0-bin-hadoop2.7
安装完毕后需要配置一下SPARK_HOME:
SPARK_HOME=C:\spark\spark-2.2.0-bin-hadoop2.7
Path里也要记得添加一下:
Path=XXXX;%SPARK_HOME%\bin;
Python与Spark交互主要用到pyspark这个模块,所以需要准备好扩展包,详细请参考《机器学习入门前准备》
Whl安装好后,能得到一个py4j文件夹,但是还需要pyspark模块这个文件夹里的内容,pyspark的获得更简单,直接去复制spark-2.2.0-bin-hadoop2.7/python/pyspark就好了。
PS:在某些版本的pyspark调用时会出现,自己稍微查下原因,网上都有配套的py文件可以覆盖,这里不是本文的重点,所以略过。
我们在《Spark原理详解》中介绍过,RDD分为转化(transformation)和动作(action)两种操作。RDD是基于当前的partitions生成新的partitions;动作是基于当前的partitions生成返回对象(数值、集合、字典等)。所以在通过python调用spark的API时需要搞清楚返回值是什么。如果返回的是partitions,调用collect()函数可以拿到封装后的数据集,分区部分对客户端是透明的,也可以调用glom()来关心具体的分区情况。如果调用的是action那么就简单得多,API直接返回结果内容。
Map、Reduce API:
最典型,也是最基本的入门API
from pyspark import SparkContext
sc = SparkContext('local')
#第二个参数2代表的是分区数,默认为1
old=sc.parallelize([1,2,3,4,5],2)
newMap = old.map(lambda x:(x,x**2))
newReduce = old.reduce(lambda a,b : a+b)
print(newMap.glom().collect())
print(newReduce)
结果是:
[[(1, 1), (2, 4)], [(3, 9), (4, 16), (5, 25)]]
15
SparkContext是代码的核心,初始化时需要设置spark的启动类型,分为local、Mesos、YARN、Standalone模式(详见Spark原理详解)
Map和reduce里都要设置一个function,我们这里用了lambda匿名函数来实现。从结果可以看将前两和后三个分别放在了1个分区中,reduce是个action直接返回的是key的sum。
预留问题:能否reduce按第二行进行求和合并,how?
flatMap、filter、distinc API:
数据的拆分、过滤和去重
sc = SparkContext('local')
old=sc.parallelize([1,2,3,4,5])
#新的map里将原来的每个元素拆成了3个
newFlatPartitions = old.flatMap(lambda x : (x, x+1, x*2))
#过滤,只保留小于6的元素
newFilterPartitions = newFlatPartitions.filter(lambda x: x<6)
#去重
newDiscinctPartitions = newFilterPartitions.distinct()
print(newFlatPartitions.collect())
print(newFilterPartitions.collect())
print(newDiscinctPartitions.collect())
结果:
[1, 2, 2, 2, 3, 4, 3, 4, 6, 4, 5, 8, 5, 6, 10]
[1, 2, 2, 2, 3, 4, 3, 4, 4, 5, 5]
[1, 2, 3, 4, 5]
Sample、taskSample、sampleByKey API:
数据的抽样,在机器学习中十分实用的功能,而它们有的是传输有的是动作,需要留意这个区别。
代码:
sc = SparkContext('local')
old=sc.parallelize(range(8))
samplePartition = [old.sample(withReplacement=True, fraction=0.5) for i in range(5)]
for num, element in zip(range(len(samplePartition)), samplePartition) :
print('sample: %s y=%s' %(str(num),str(element.collect())))
taskSamplePartition = [old.takeSample(withReplacement=False, num=4) for i in range(5)]
for num, element in zip(range(len(taskSamplePartition)), taskSamplePartition) :
#注意因为是action,所以element是集合对象,而不是rdd的分区
print('taskSample: %s y=%s' %(str(num),str(element)))
mapRdd = sc.parallelize([('B',1),('A',2),('C',3),('D',4),('E',5)])
y = [mapRdd.sampleByKey(withReplacement=False,
fractions={'A':0.5, 'B':1, 'C':0.2, 'D':0.6, 'E':0.8}) for i in range(5)]
for num, element in zip(range(len(y)), y) :
#注意因为是action,所以element是集合对象,而不是rdd的分区
print('y: %s y=%s' %(str(num),str(element.collect())))
结果:
sample: 0 y=[2, 5]
sample: 1 y=[0, 3, 3, 6]
sample: 2 y=[0, 4, 7]
sample: 3 y=[1, 3, 3, 3, 6, 7]
sample: 4 y=[2, 4, 6]
taskSample: 0 y=[3, 4, 1, 6]
taskSample: 1 y=[2, 5, 3, 4]
taskSample: 2 y=[7, 1, 2, 5]
taskSample: 3 y=[6, 3, 1, 2]
taskSample: 4 y=[4, 6, 5, 0]
y: 0 y=[('B', 1)]
y: 1 y=[('B', 1), ('D', 4), ('E', 5)]
y: 2 y=[('B', 1), ('A', 2), ('C', 3), ('E', 5)]
y: 3 y=[('B', 1), ('A', 2), ('D', 4), ('E', 5)]
y: 4 y=[('B', 1), ('A', 2), ('C', 3), ('E', 5)]
有几个参数需要说明下:
withReplacement代表取值后是否重新放回元素池,也就决定了某元素能否重复出现。
Fraction代表每个元素被取出来的概率。
Num代表取出元素的个数。
交集intersection、并集union、排序sortBy API:
sc = SparkContext('local')
rdd1 = sc.parallelize(['C','A','B','B'])
rdd2 = sc.parallelize(['A','A','D','E','B'])
rdd3 = rdd1.union(rdd2)
rdd4 = rdd1.intersection(rdd2)
print(rdd3.collect())
print(rdd4.collect())
print(rdd3.sortBy(lambda x : x[0]).collect())
结果:
['C', 'A', 'B', 'B', 'A', 'A', 'D', 'E', 'B']
['A', 'B']
['A', 'A', 'A', 'B', 'B', 'B', 'C', 'D', 'E']
flod折叠、aggregate聚合API:
这俩都是action,虽然pyspark提供了max、min、sum、count、mean、stdev(标准差,反应平均值的离散程度)、sampleStdev(与stdev意义相同,stdev分母N-1,sampleStdev分母N)、sampleVariance(方差,所有值平方和除N-1)、top、countByValue、first、collectAsMap等内置的统计函数,但是在某型特殊场景下还是希望能人工订制聚合的公式,需要用到这两个动作。
代码:
sc = SparkContext('local')
rdd1 = sc.parallelize([2,4,6,1])
rdd2 = sc.parallelize([2,4,6,1],4)
zeroValue = 0
foldResult = rdd1.fold(zeroValue,lambda element, accumulate : accumulate+element)
zeroValue = (1,2)
seqOp = lambda accumulate,element : (accumulate[0] + element, accumulate[1] * element)
combOp = lambda accumulate,element : (accumulate[0]+element[0], accumulate[1] * element[1])
aggregateResult = rdd1.aggregate(zeroValue,seqOp,combOp)
print(foldResult)
print(aggregateResult)
aggregateResult = rdd2.aggregate(zeroValue,seqOp,combOp)
print(foldResult)
print(aggregateResult)
结果:
13
(15, 192)
13
(18, 1536)
Fold略简单,但是agregate的理解非常难,不同的分区场景会得到不同的结果,这里用图来解释说明下:
默认1个partition的情况:
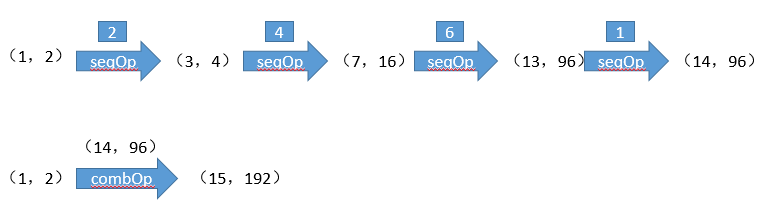
4个partition的情况:
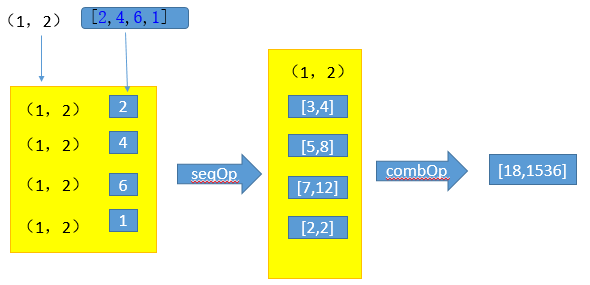
reduceByKey、 reduceByKeyLocal API:
这两个要计算的效果是一样的,但是前者是传输,后者是动作,使用时候需要注意:
sc = SparkContext('local')
oldRdd=sc.parallelize([('Key1',1),('Key3',2),('Key1',3),('Key2',4),('Key2',5)])
newRdd = oldRdd.reduceByKey(lambda accumulate,ele : accumulate+ele)
newActionResult = oldRdd.reduceByKeyLocally(lambda accumulate,ele : accumulate+ele)
print(newRdd.collect())
print(newActionResult)
结果:
[('Key1', 4), ('Key3', 2), ('Key2', 9)]
{'Key1': 4, 'Key3': 2, 'Key2': 9}
回到前面map、reduce尾巴留的那个思考题,实现的方式不止一种,我这里给出两种解题思路:
方案A:
sc = SparkContext('local')
#第二个参数2代表的是分区数,默认为1
old=sc.parallelize([1,2,3,4,5])
newMapRdd = old.map(lambda x : (str(x),x**2))
print(newMapRdd.collect())
mergeRdd = newMapRdd.values()
print(mergeRdd.sum())
方案B:
sc = SparkContext('local')
oldRdd=sc.parallelize([1,2,3,4,5])
newListRdd = oldRdd.map(lambda x : x**2)
newMapRdd = oldRdd.zip(newListRdd)
print(newMapRdd.values().sum())
之所以给出这些思路,是因为我们在使用
pyspark
的时候,除了要关心
transformation
和
action
之分,还需要注意你要处理的
rdd
里的数据是
list
还是
map
,因为对于他们实用的方法又是不同的。如果有必要,可以像这样做
list
和
map
的转换。















 432
432

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









