







零、思考
1. 场景
-
学工部 整个部门解散了,该部门及部门下的员工都需要删除了。
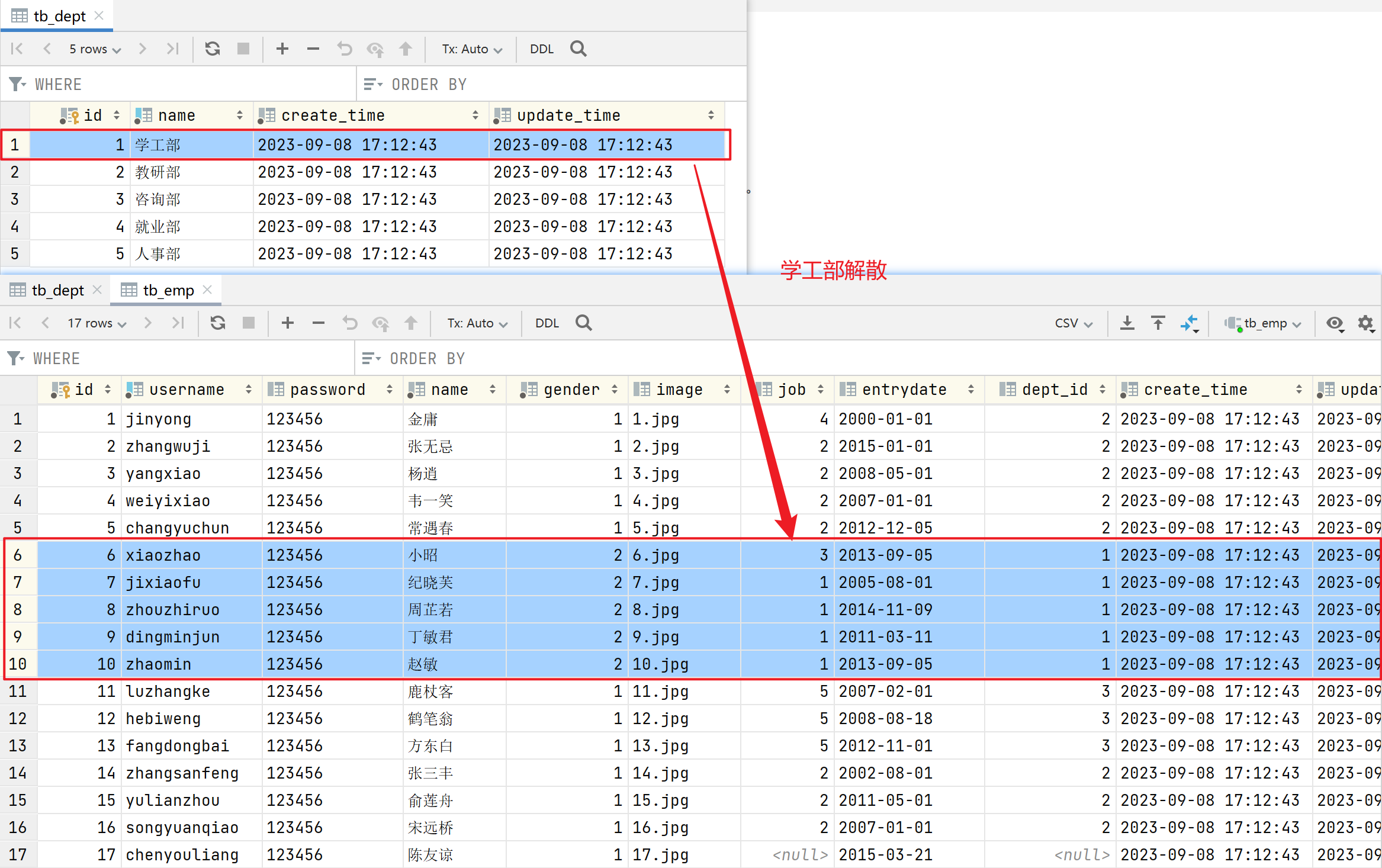
2. 正常操作
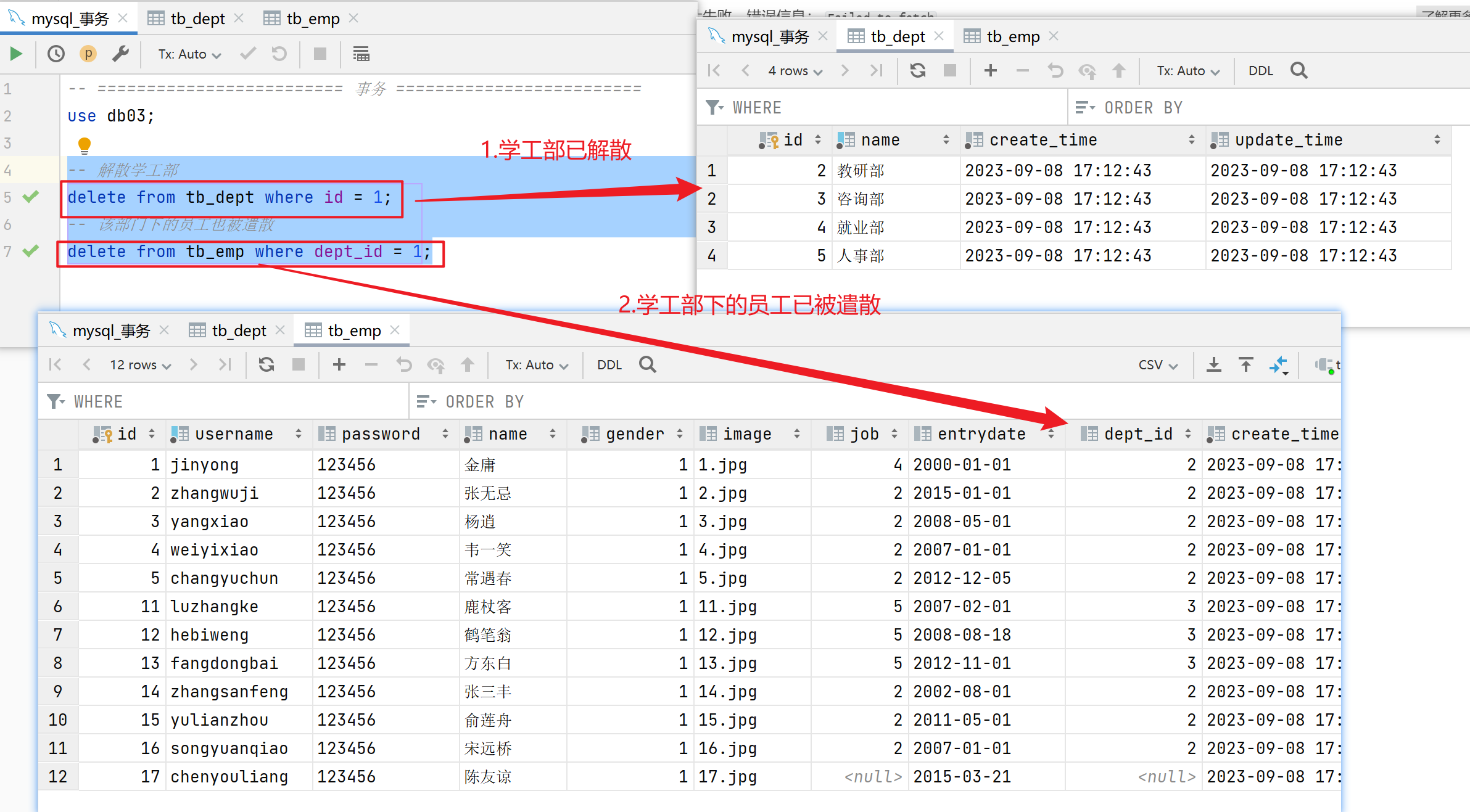
3. 异常操作
-
如果删除部门成功了,而删除该部门的员工时失败了,就造成了数据的不一致。



- 要想解决这类问题,就需要用到数据库中的事务。
一、事务
1. 介绍
-
事务:
-
是一组操作的集合,它是一个不可分割的工作单位。事务会把所有的操作作为一个整体一起向系统提交或撤销操作请求,即这些操作:要么同时成功,要么同时失败。

-
因此,也属于一个事务。
-
为什么刚刚删除部门成功了,但是删除部门下的员工却失败了,没有同时失败呢?

-
注意事项:默认MySQL的事务是自动提交的,也就是说,当执行一条DML语句,MySQL会立即隐式的提交事务。
- 其实,以下两个执行属于两个事务,所以当第二条DML语句提交事务时就出现了问题:
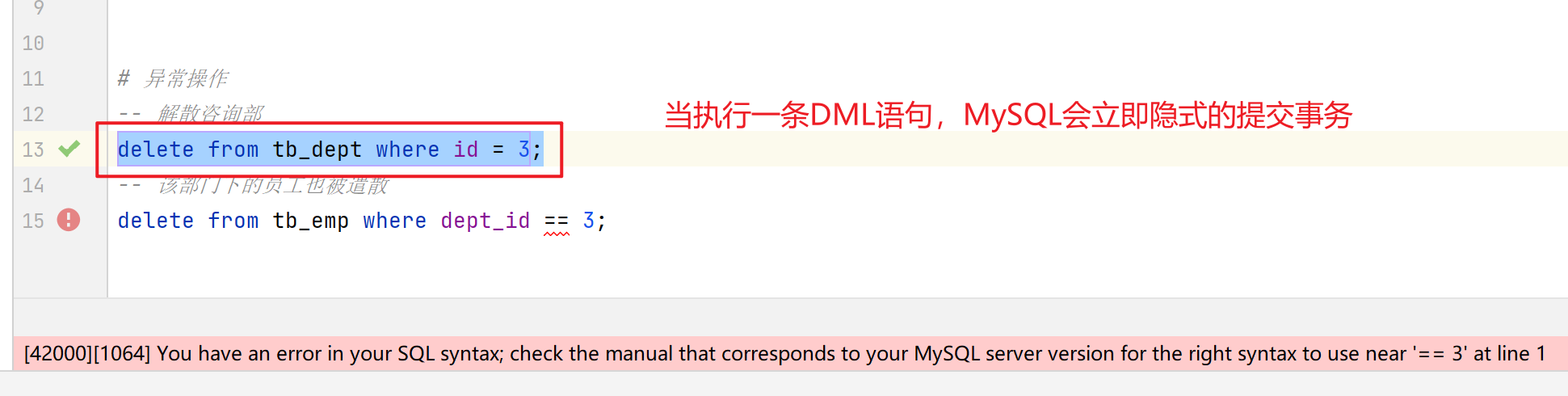
-
事务控制:因此我们需要将这两步操作控制在一个事务的范围内
-
2. 语法
-
开启事务:
- 业务操作执行之前执行以下任一指令来开启事务:
-- 方式1 start transaction; -- 方式2 / begin ; -
提交事务:
- 当一组操作都执行成功之后,执行以下指令来提交事务(将所执行的操作真正的提交到数据库来修改表结构当中的数据):
commit; -
回滚事务:
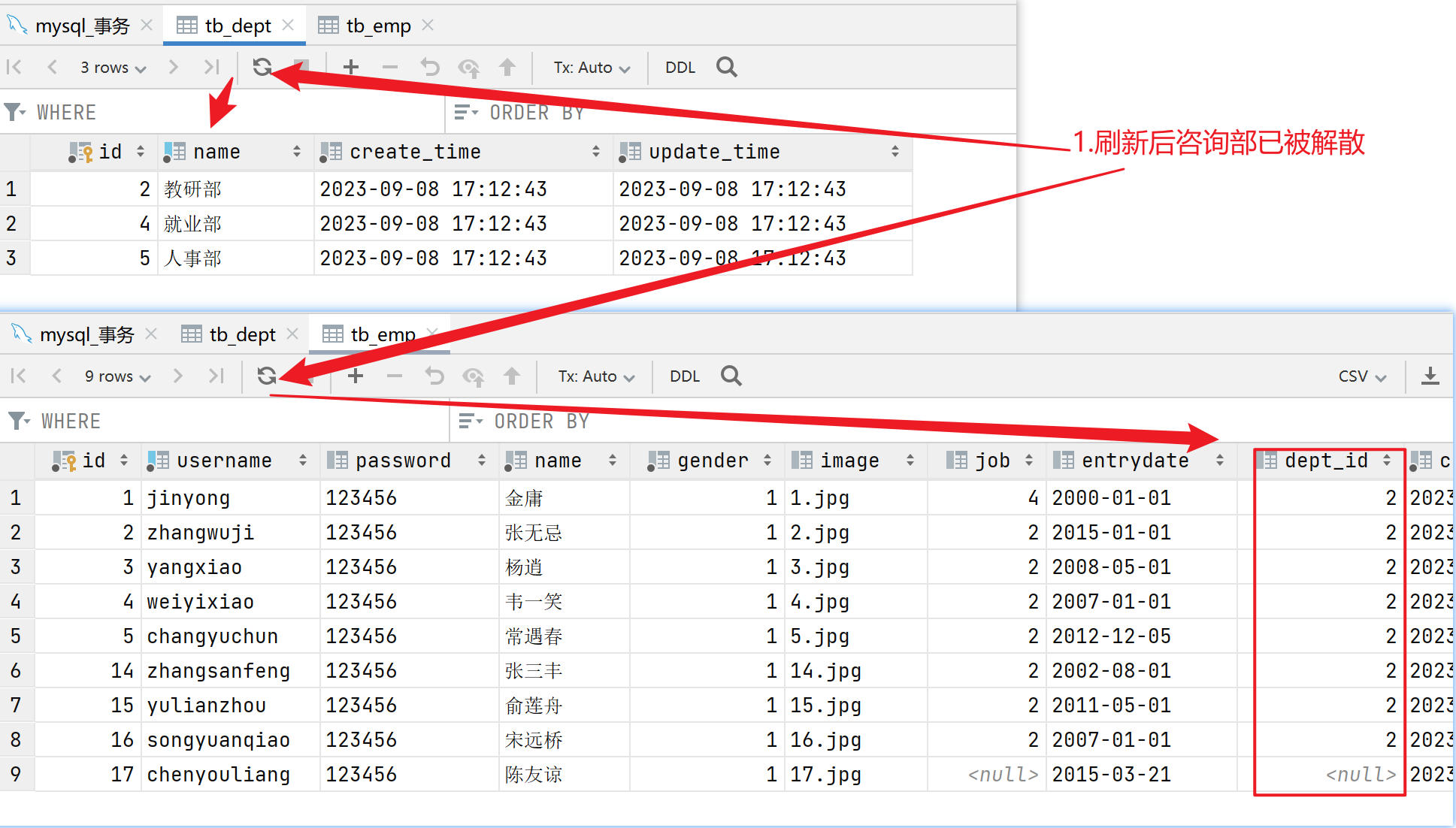
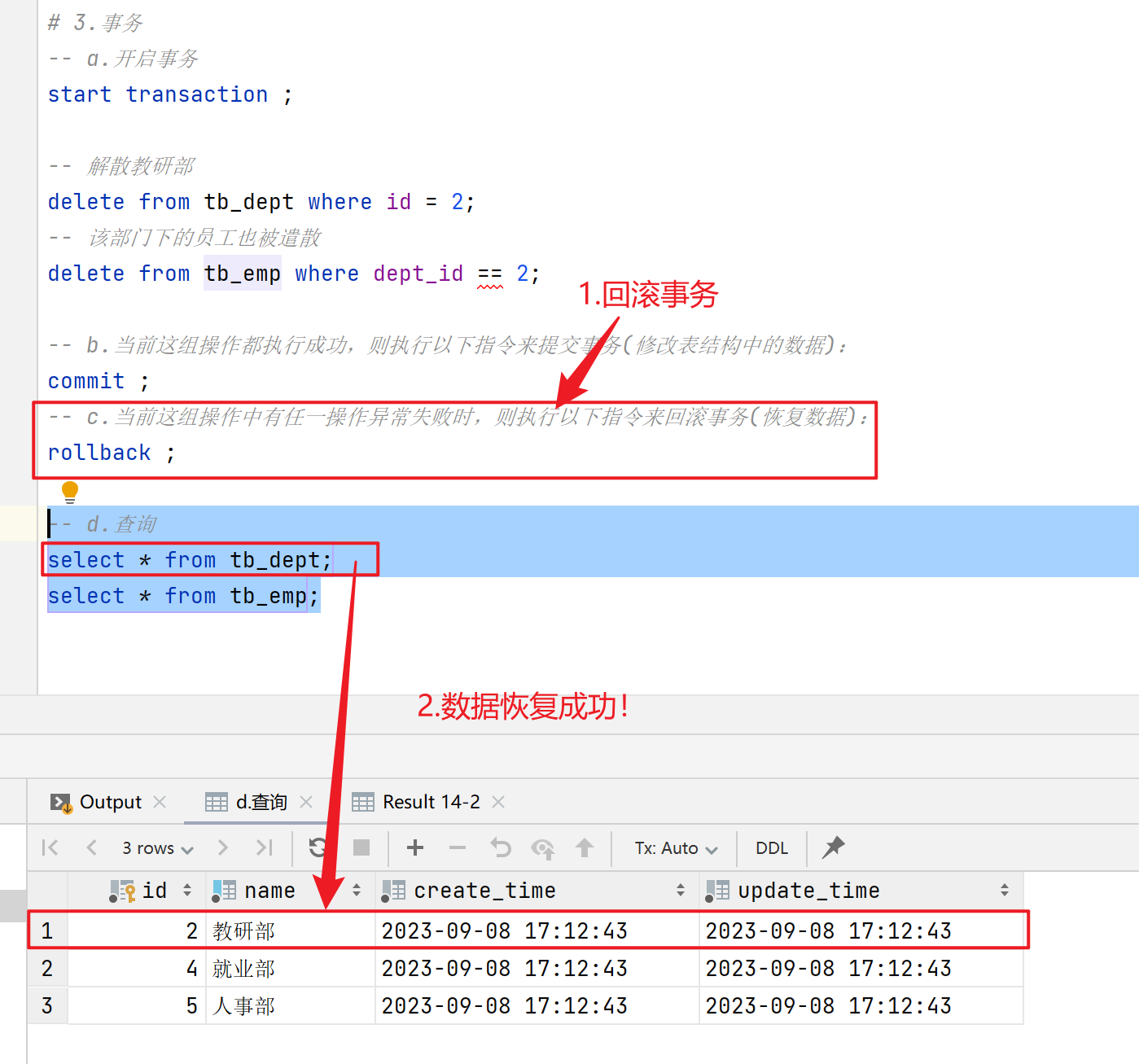
- 当一组操作中有任一操作失败时,此时需要执行以下指令来回滚事务(就是把所有数据恢复到原样):
rollback;
3. 操作
-
先将刚刚操作失败,删除掉的数据手动恢复一下:
-
事务:
-
解散咨询部:
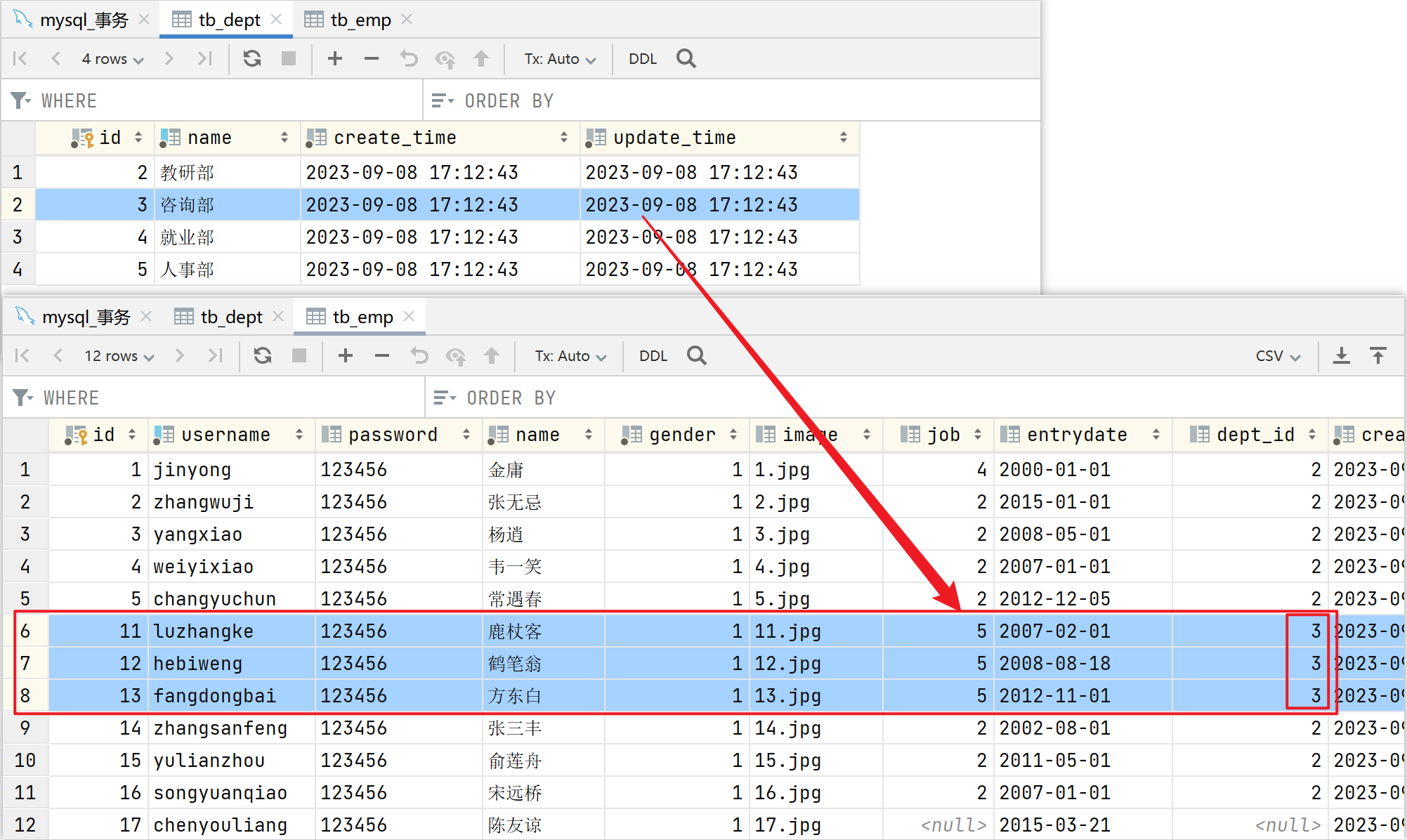
-
正常执行:
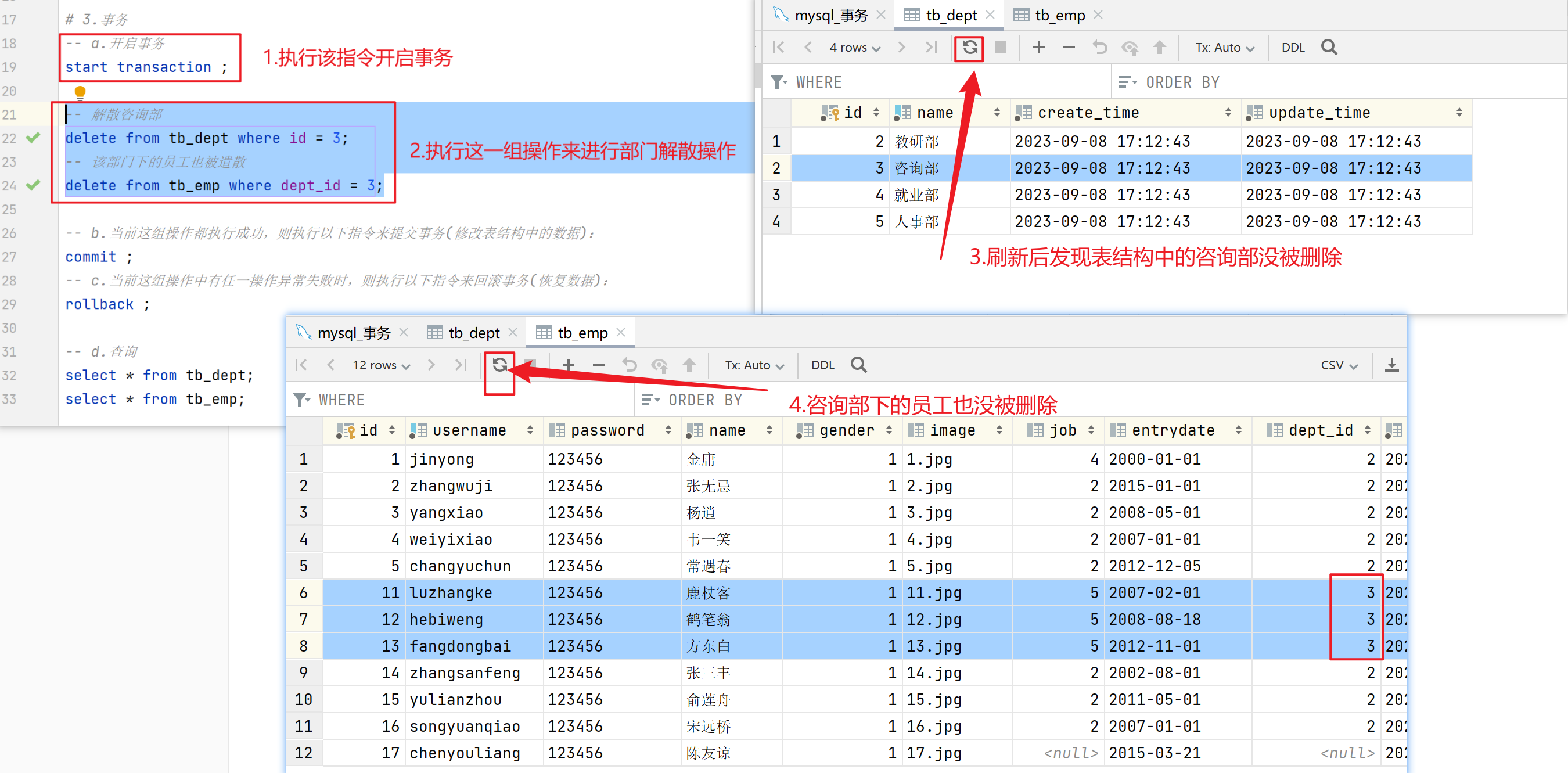

-
异常操作:
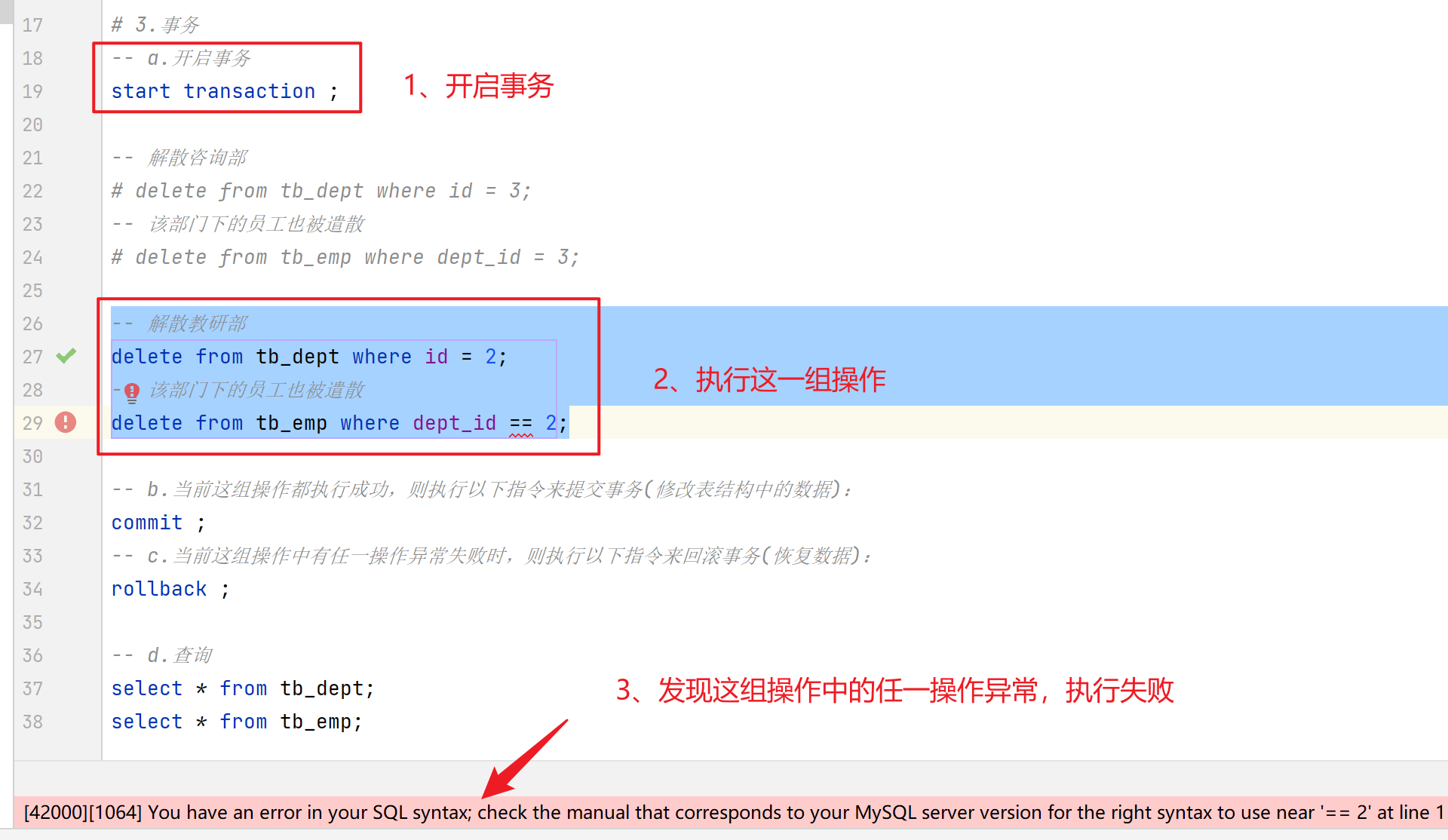
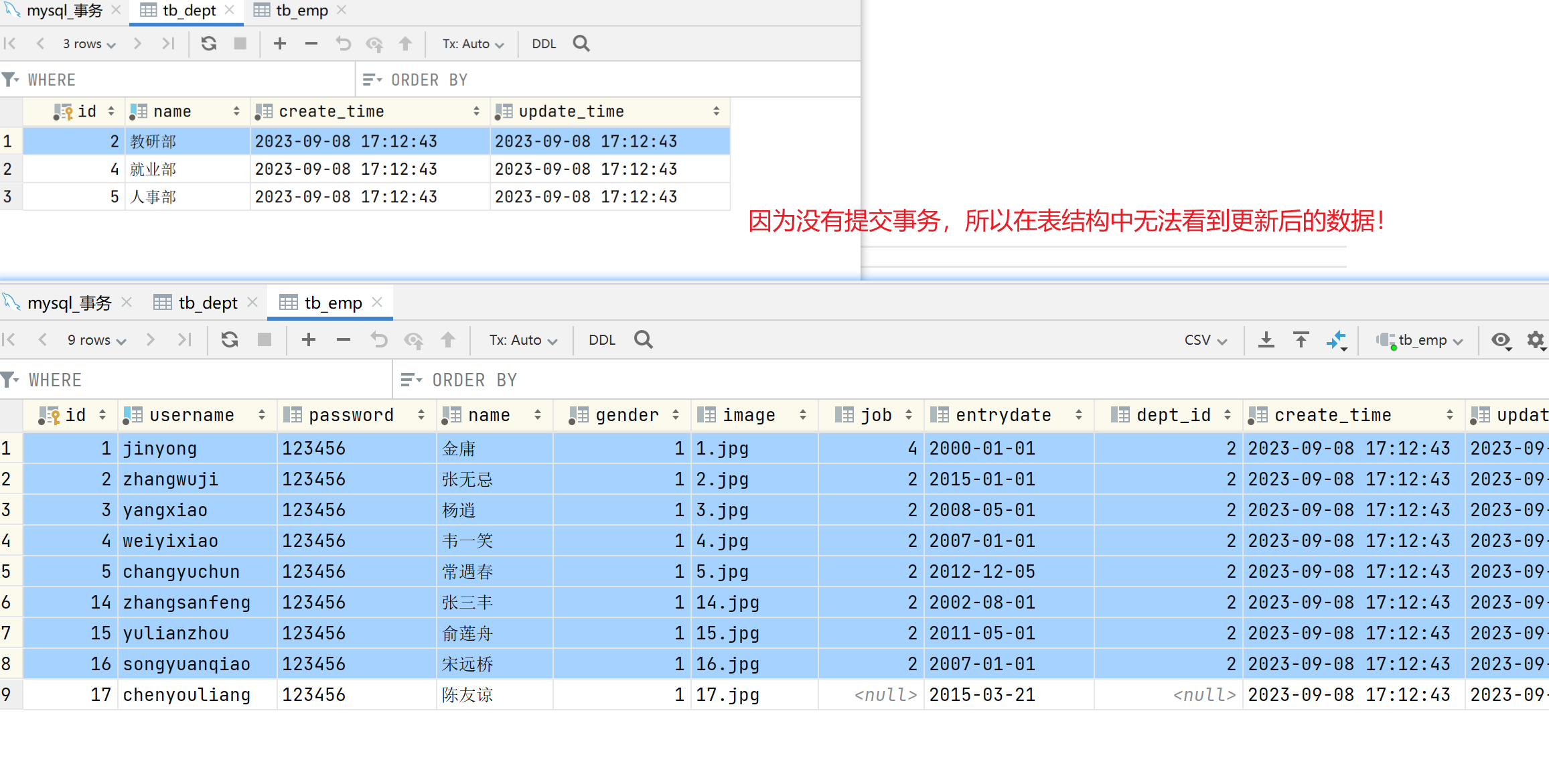

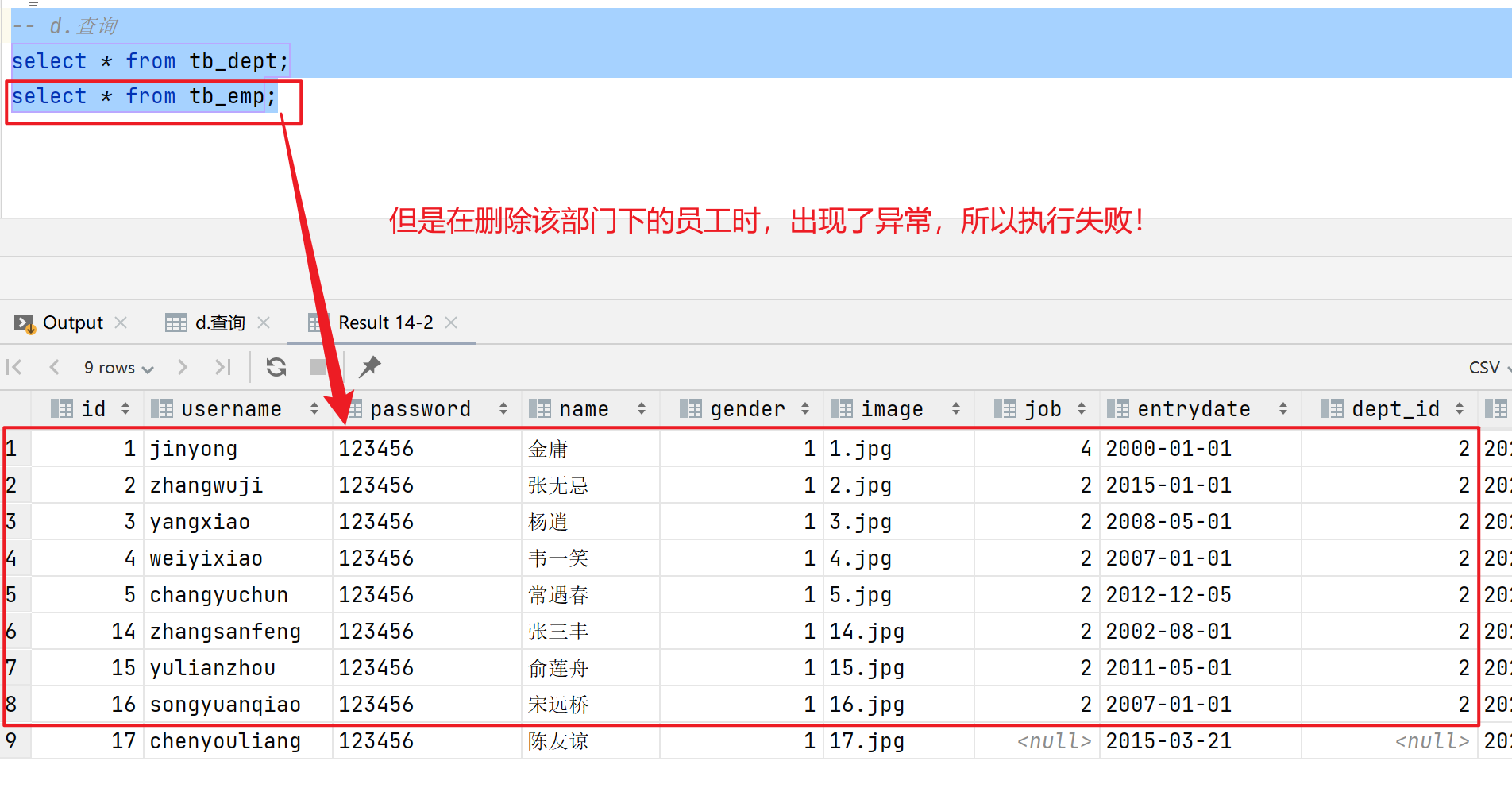
-
回滚事务:
- 这样可以保证操作前后,数据是一致的。
-
4. 四大特性-ACID(面试)
(1) 原子性(Atomicity)
- 事务是不可分割的最小单元,要么全部成功,要么全部失败
(2) 一致性(Consistency)
- 事务完成时,必须使所有的数据都保持一致状态:
- 比如刚才解散部门的例子:
- 事务完成之后,要么部门以及部门下的员工数据都还在
- 事务完成之后,要么部门以及部门下的员工数据都被删除
- 如果部门的数据没了,部门下的员工数据还在,这个数据就不一致了!
- 比如刚才解散部门的例子:
(3) 隔离性(Isolation)
-
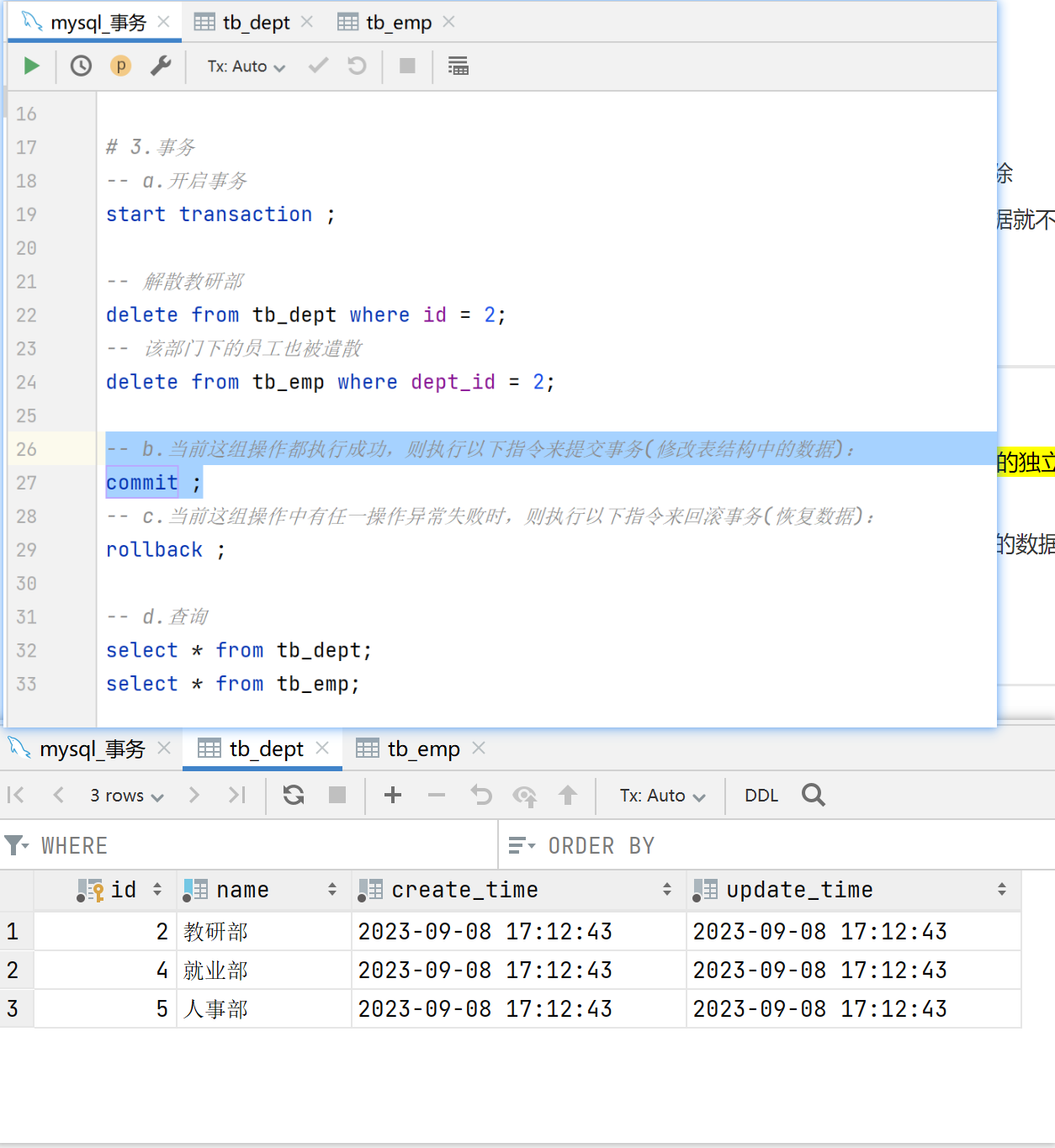
数据库系统提供的隔离机制,保证事务在不受外部并发操作影响的独立环境下运行(可以通过隔离级别来设置的,隔离性越高事务越安全,但是效率就越低)
-
只要我们这边的事务不提交,别的窗口就看不到我们所操作的数据
-
(4) 持久性(Durability)
- 事务一旦提交或回滚,它对数据库中的数据的改变就是永久的
5. 总结
(1)事务介绍
- 一组操作的集合,这组操作要么全部成功,要么全部失败。
(2)事务操作
start transaction; / begin ;
commit ;
rollback ;
(3)事务四大特性
- 原子性
- 一致性
- 隔离性
- 持久性
二、索引
1. 体验
-
体验一下索引对于查询效率的提升:
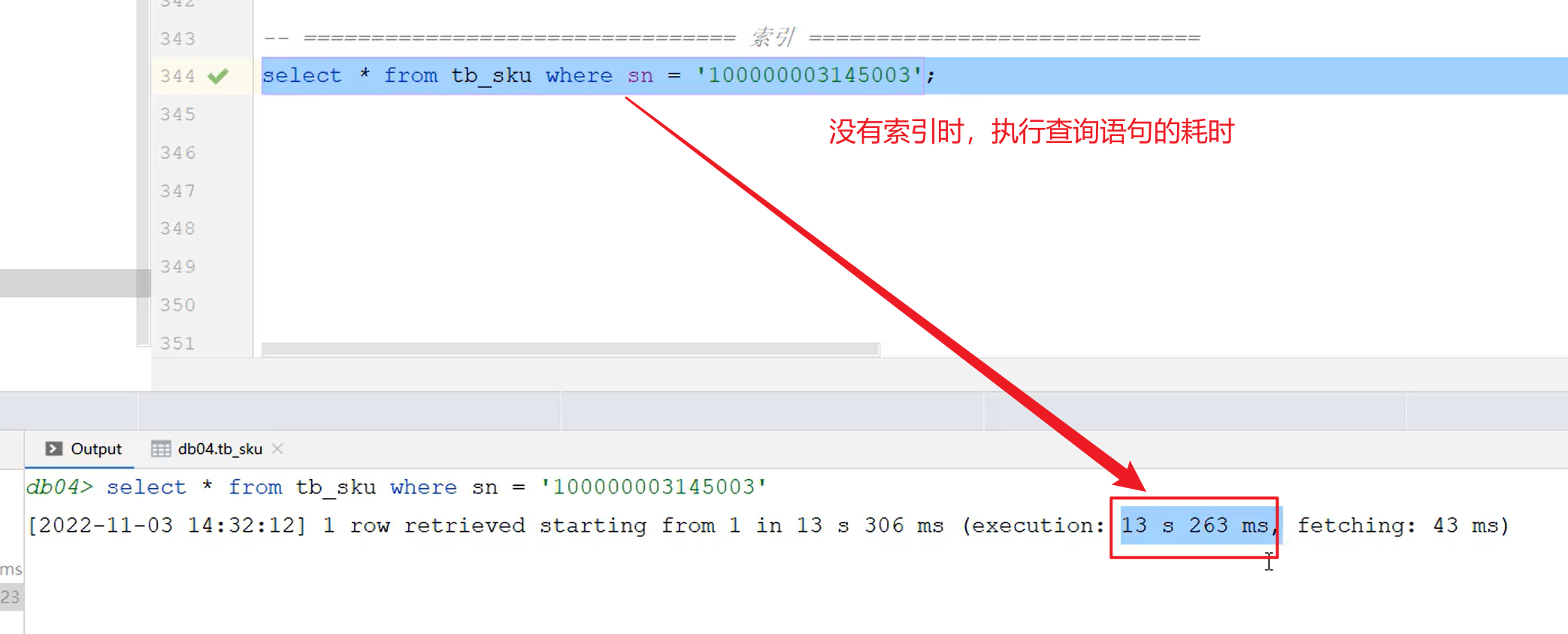


2. 介绍
(1) 概述
-
索引(index):是帮助数据库 高效获取数据 的 数据结构 。
-
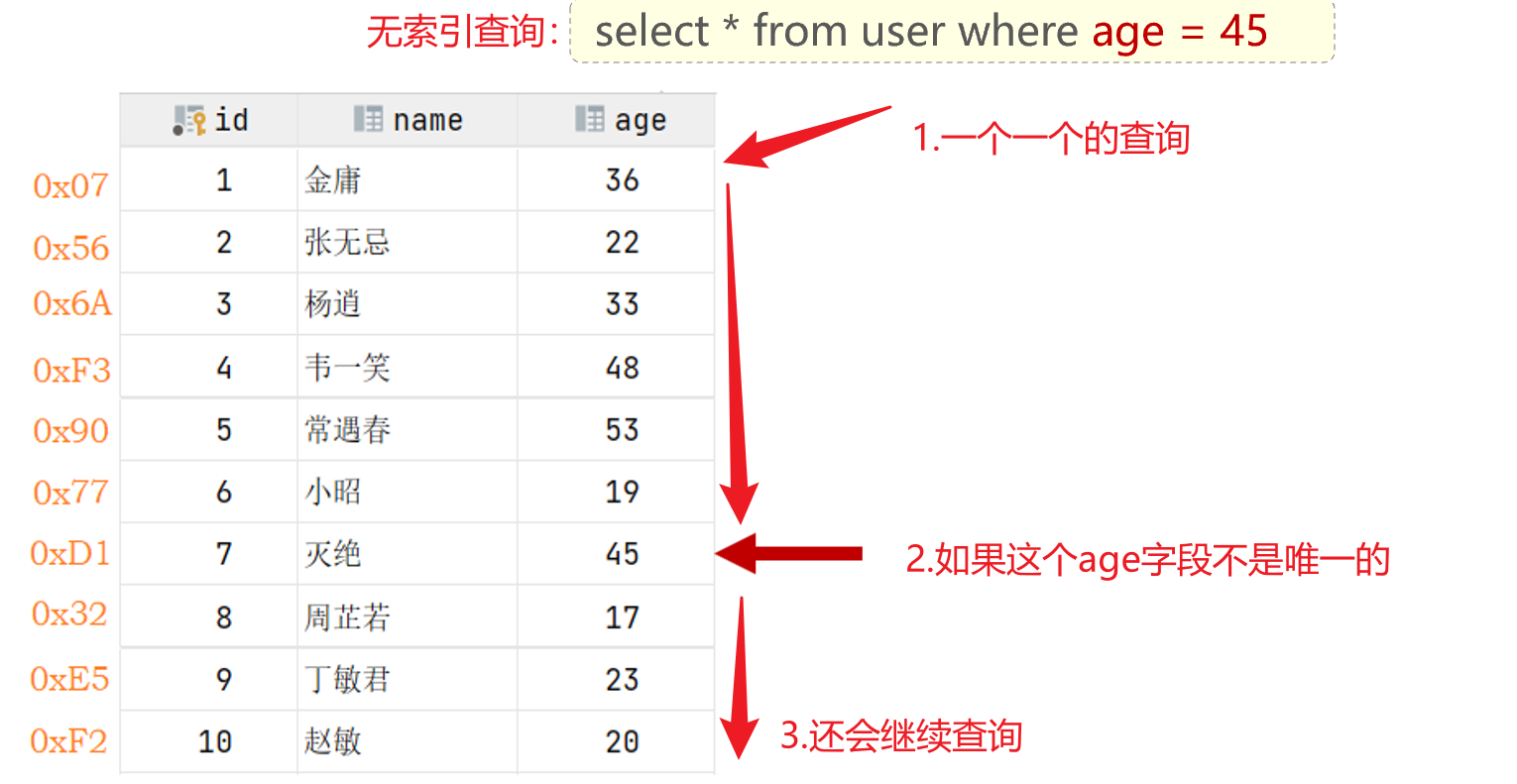
无索引查询原理:全表扫描(数据量越大,性能越低)
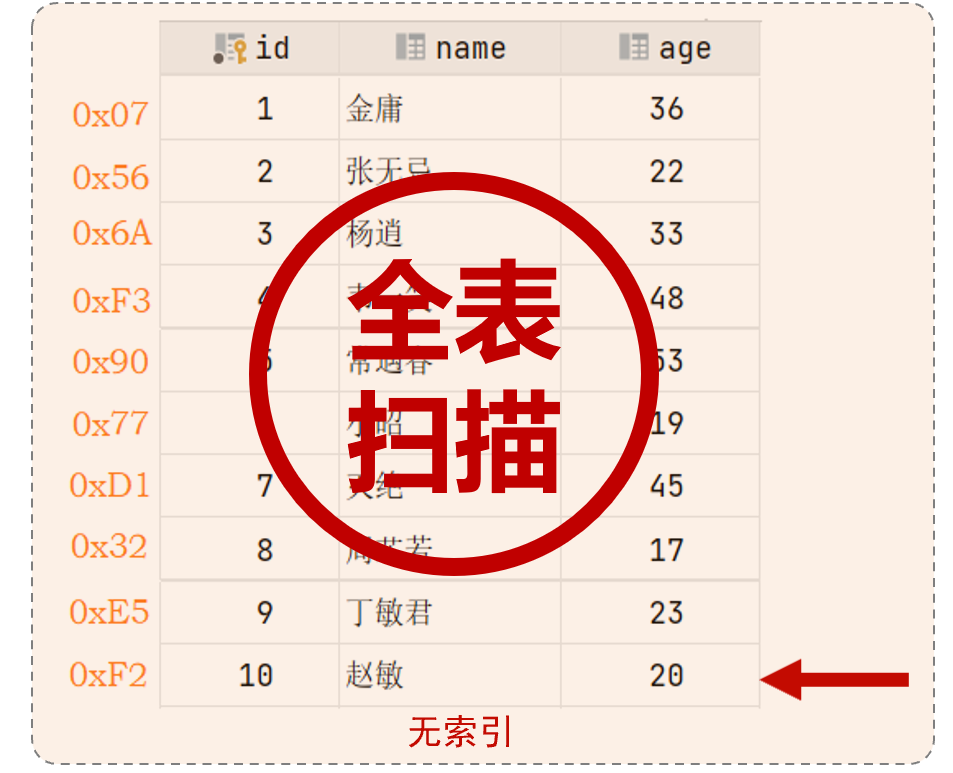
-
有索引查询原理:如果为age字段创建一个索引,就会维护一个索引对应的数据结构(大大提高查询效率)
-
二叉搜索树作为示意图:

-
查询数据:查询age=45的用户信息,45只需要与36、48、45进行比较,不需要进行全表扫描,效率大大提升
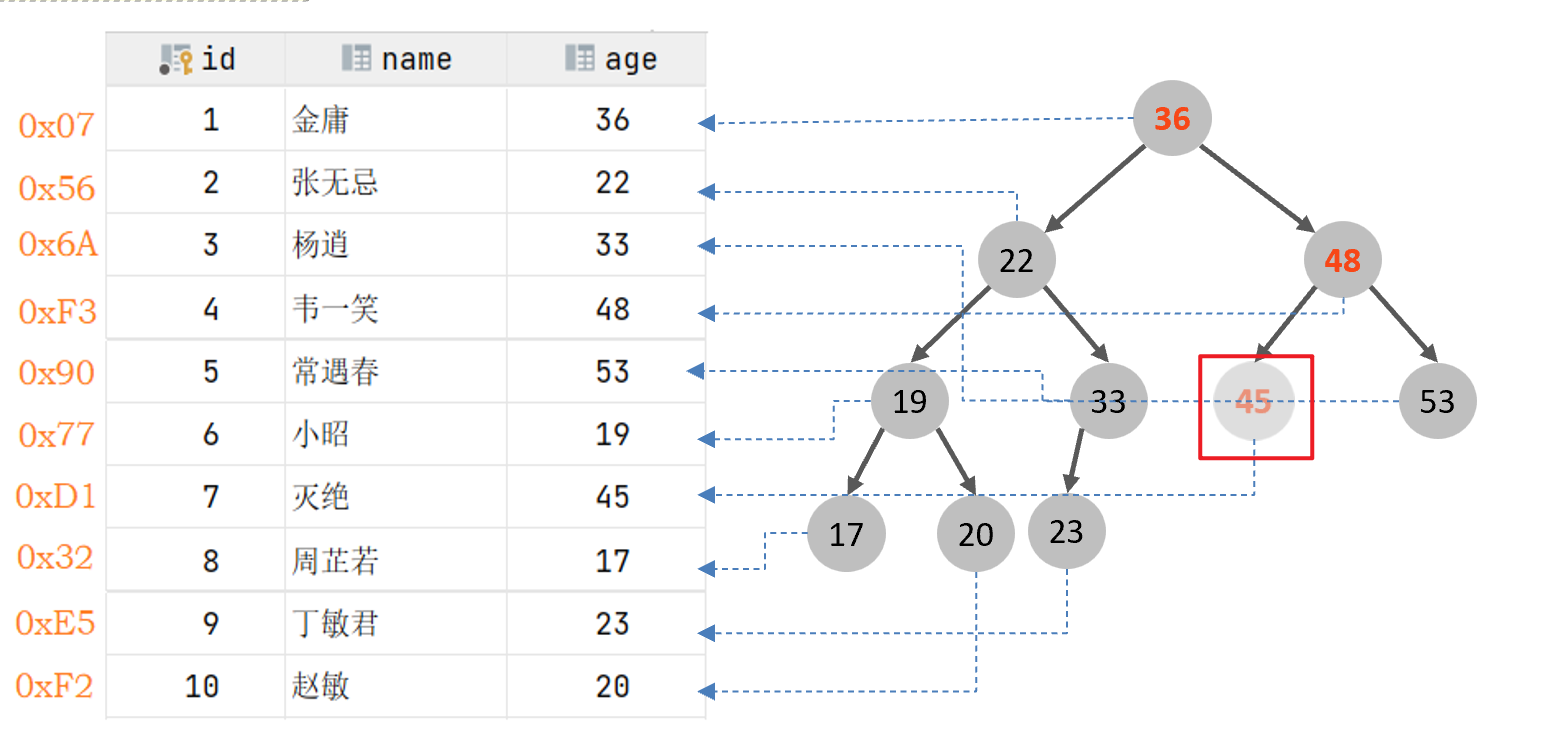
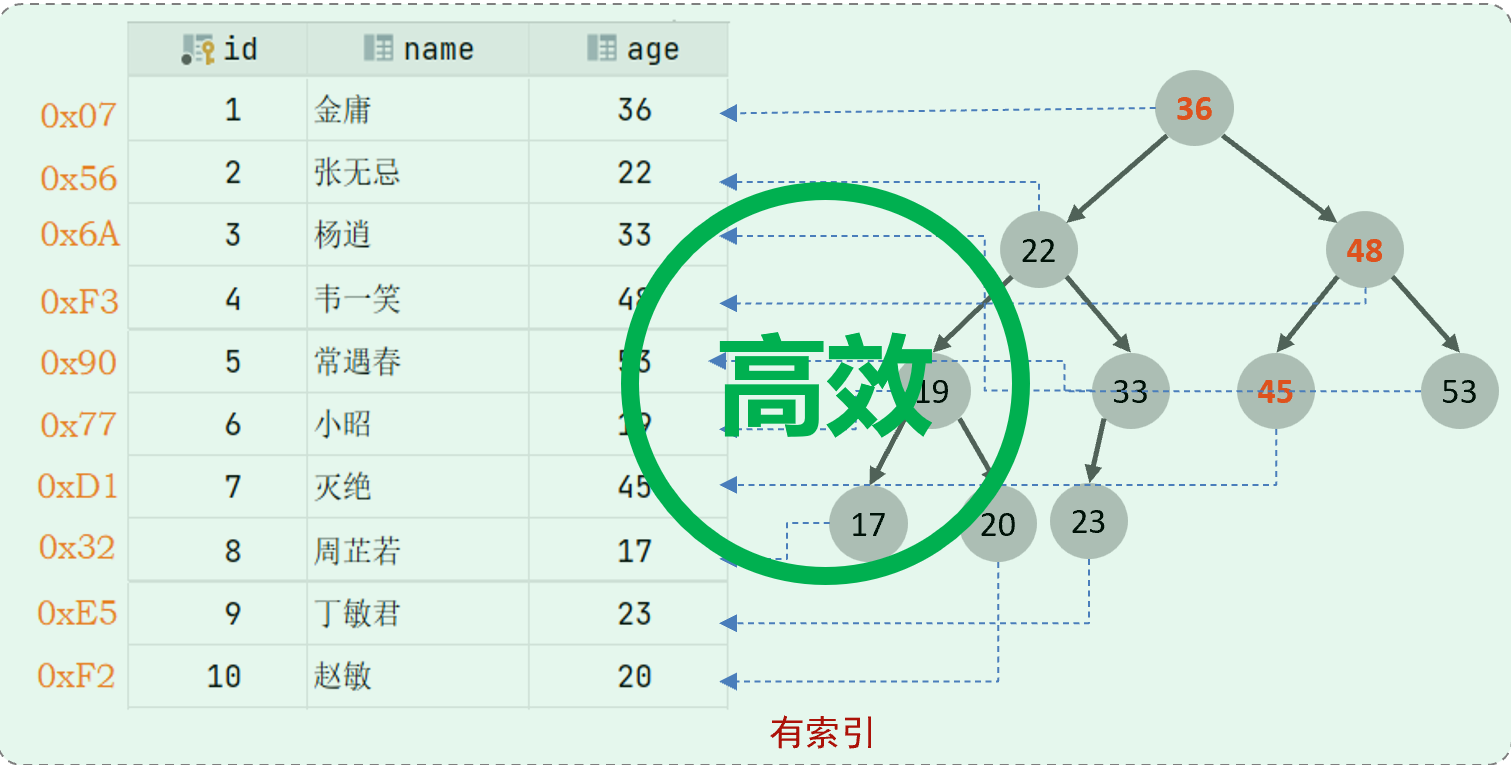
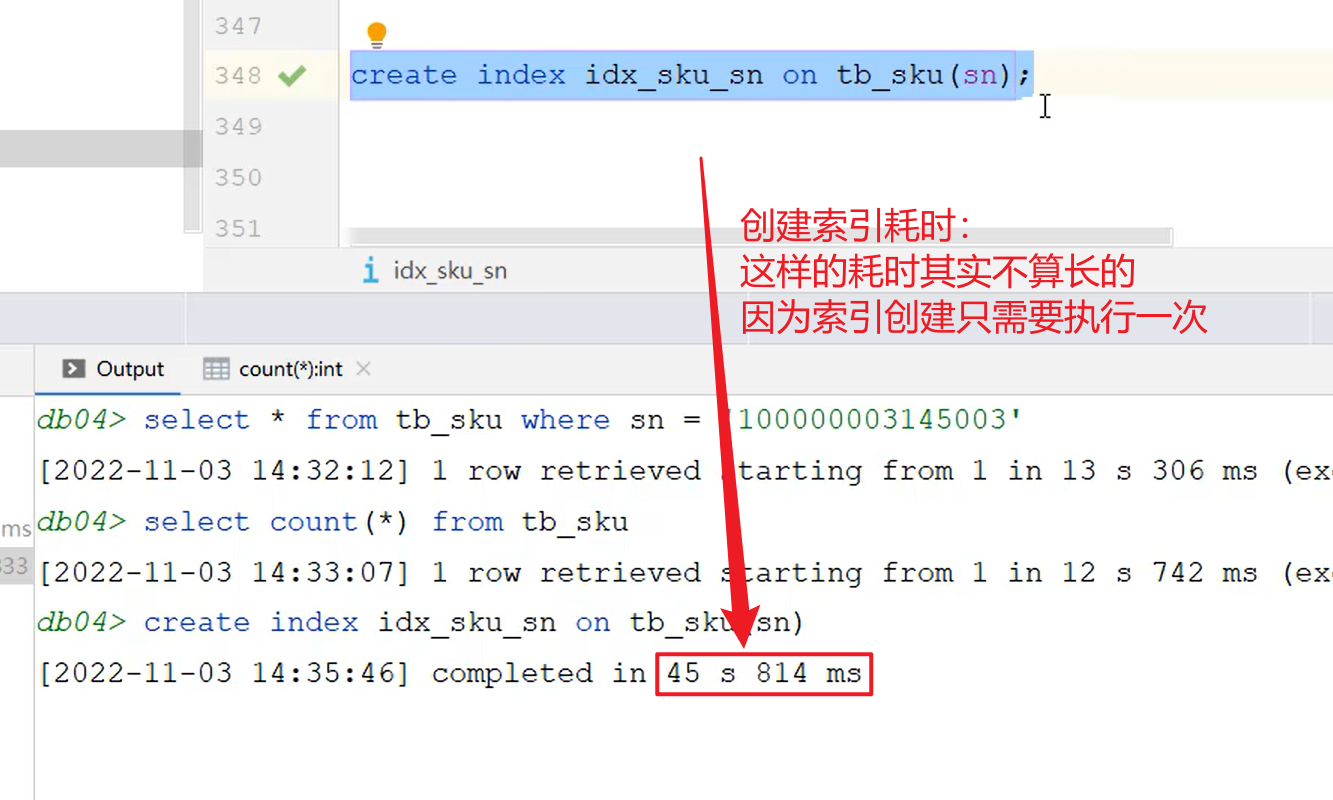
-
- 当数据量庞大时,创建索引时,因为需要构建树形结构,所以耗时久一点;
- 不过是值得的,因为索引创建只需要一次执行,之后的每一次查询效率都能得到大大提升。
-
-
也可以把 索引 理解为 一本书的目录,假如一本书没有目录,你要找某段内容,就要一页一页往后翻,直到找到要找的内容。
-
那如果建立了目录,只需要看一眼目录,就能知道某段内容在第几页,就可以精确找到。

(2) 优缺点
-
优点:
①. 提高数据查询的效率,降低数据库的IO成本。
②. 通过索引列对数据进行排序,降低数据排序的成本,降低CPU消耗。
-
缺点(可以忽略不计):
①. 索引会占用存储空间。
②. 索引大大提高了查询效率,同时却也降低了insert、update、delete的效率。
- 因为进行增删改操作时,除了需要去操作数据本身以外,还需要来维护这个索引结构。
3. 结构
(1) 介绍
-
MySQL数据库支持的索引结构有很多,如:Hash索引、B+Tree索引、Full-Text索引等。我们平常所说的索引,如果没有特别指明,都是指默认的 B+Tree 结构组织的索引。

-
存在问题:
- 大数据量情况下,层级深,检索速度慢。
(2) B+Tree(多路平衡搜索树)
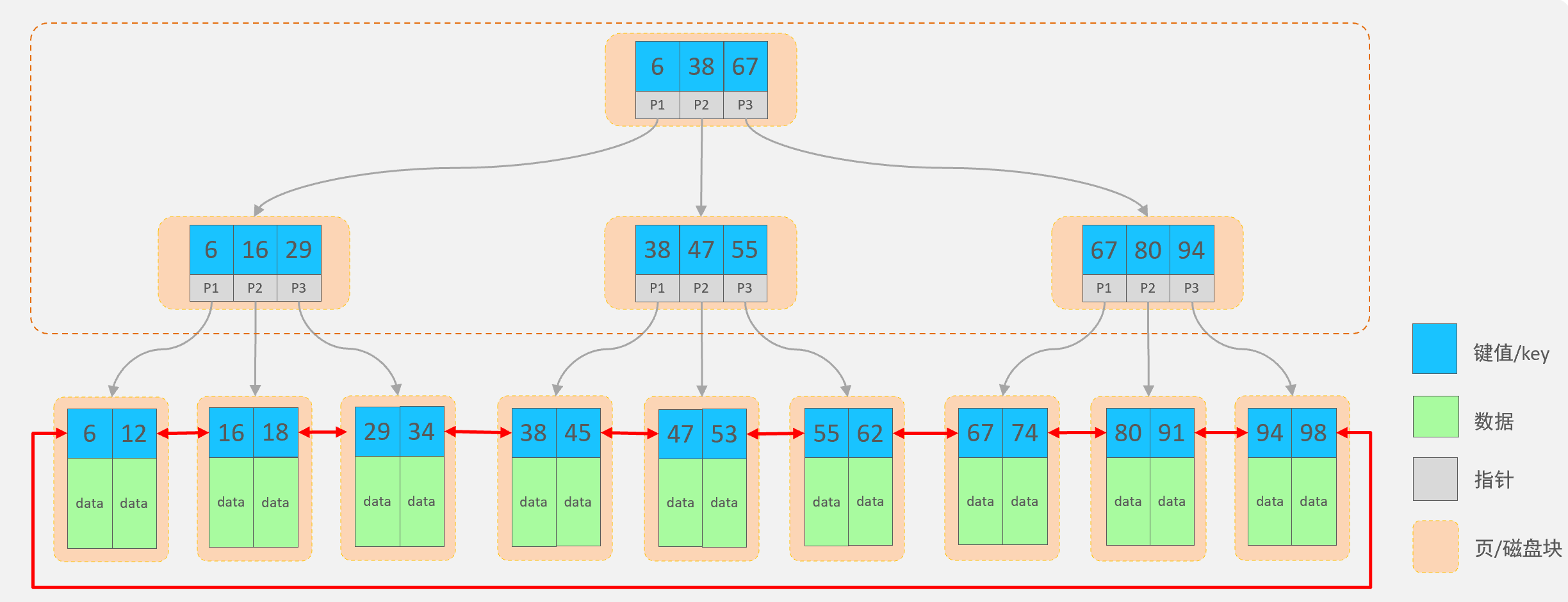
-
B+Tree(多路平衡搜索树)
-
特点:
①. 每一个节点,可以存储多个key(有n个key,就有n个指针)。
- 有n个指针,意味着节点下可以有多个子节点
- 相对于平衡二叉树、红黑树的话,相同数据量的情况下,树的高度要低得多
- 树的层级一般在3-4层
②. 所有的数据都存储在叶子节点,非叶子节点仅用于索引数据。
- 所有的key都会出现在叶子节点,不管查找哪一条数据,最终都要找到叶子节点才能拿到对应的数据
- 可以保证数据库服务器的查询性能比较稳定
③. 叶子节点形成了一颗双向链表,便于数据的排序及区间范围查询。
-
-
查找流程:
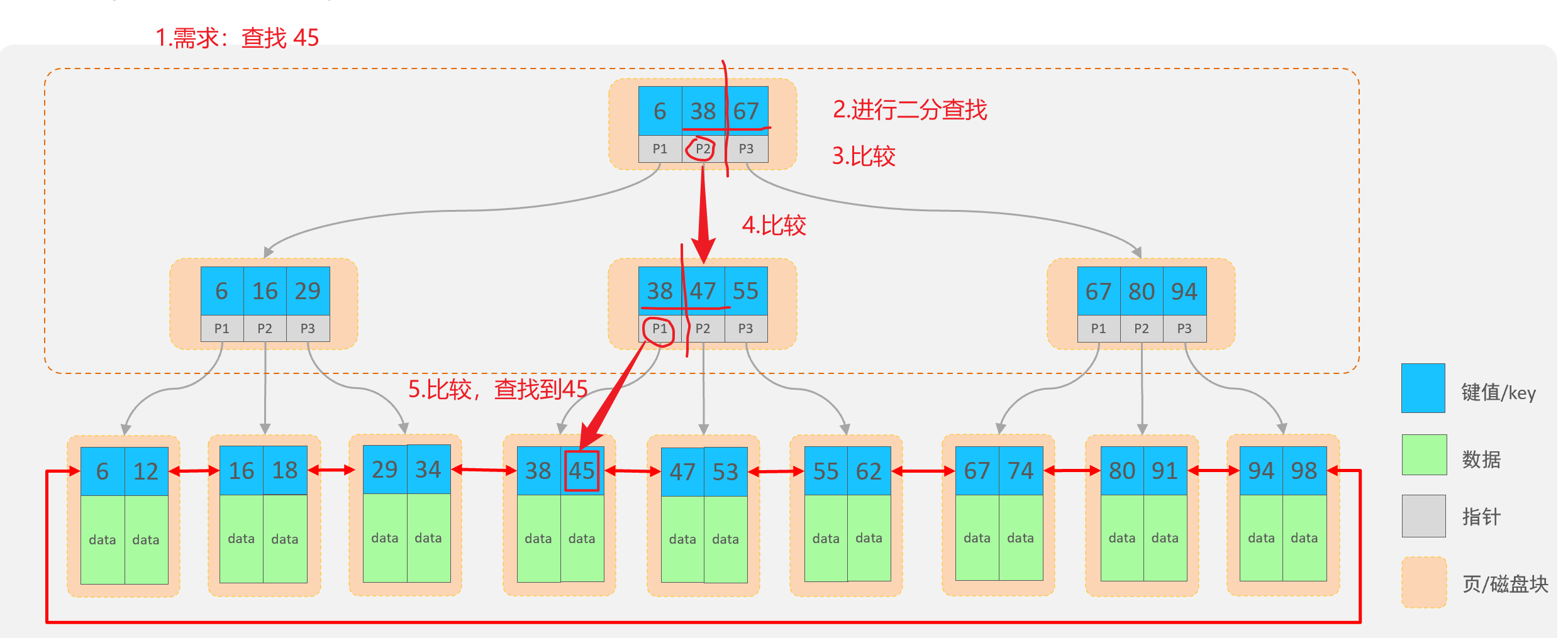
4. 语法
(1) 创建索引
create [ unique ] index 索引名 on 表名 (字段名,... ) ;
(2) 查看索引
show index from 表名;
(3) 删除索引
drop index 索引名 on 表名;
(4) 需求实现
-
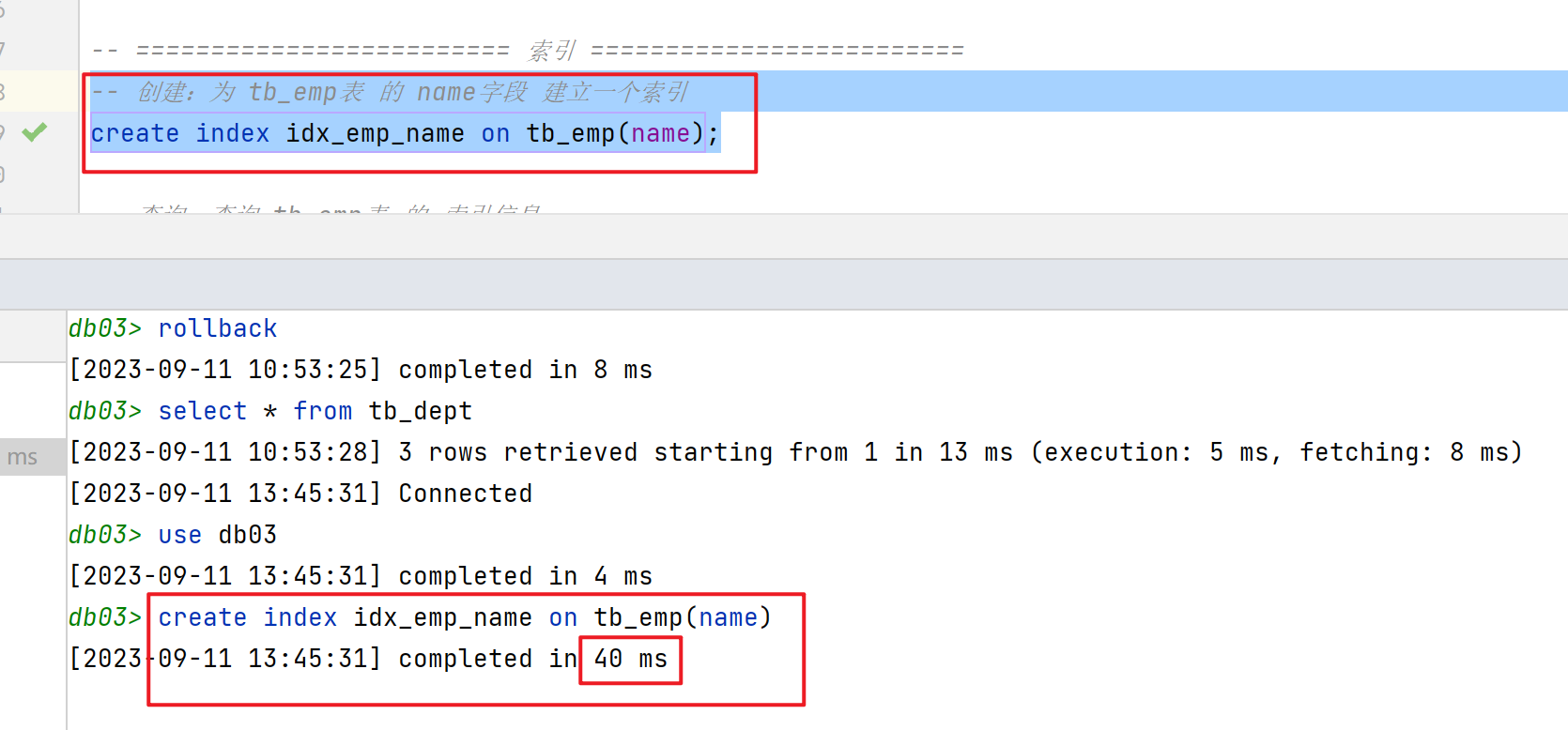
创建:为 tb_emp表 的 name字段 建立一个索引
-
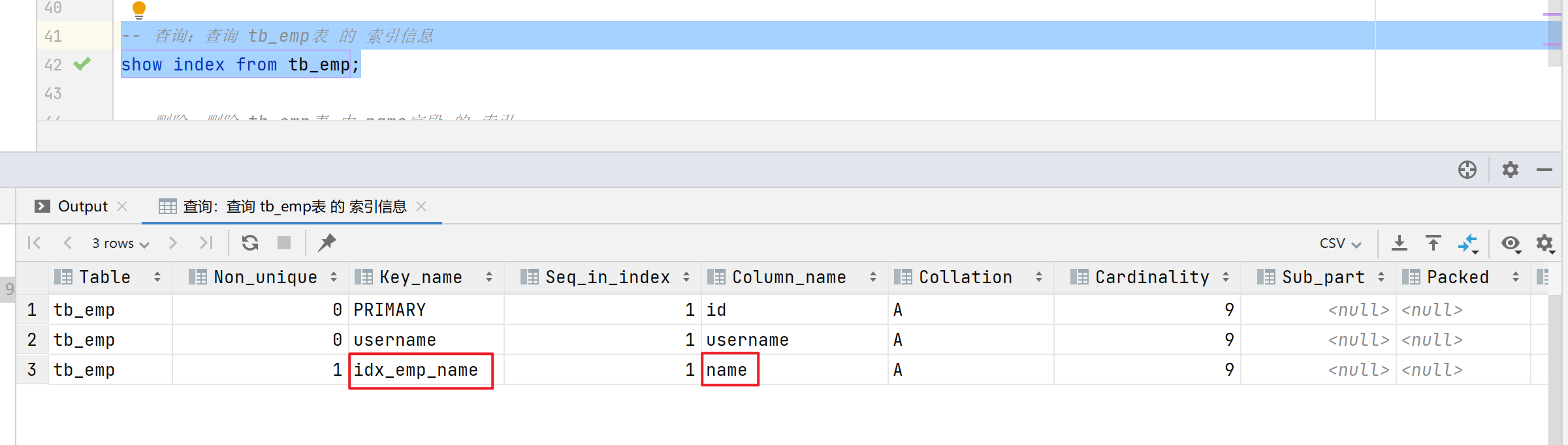
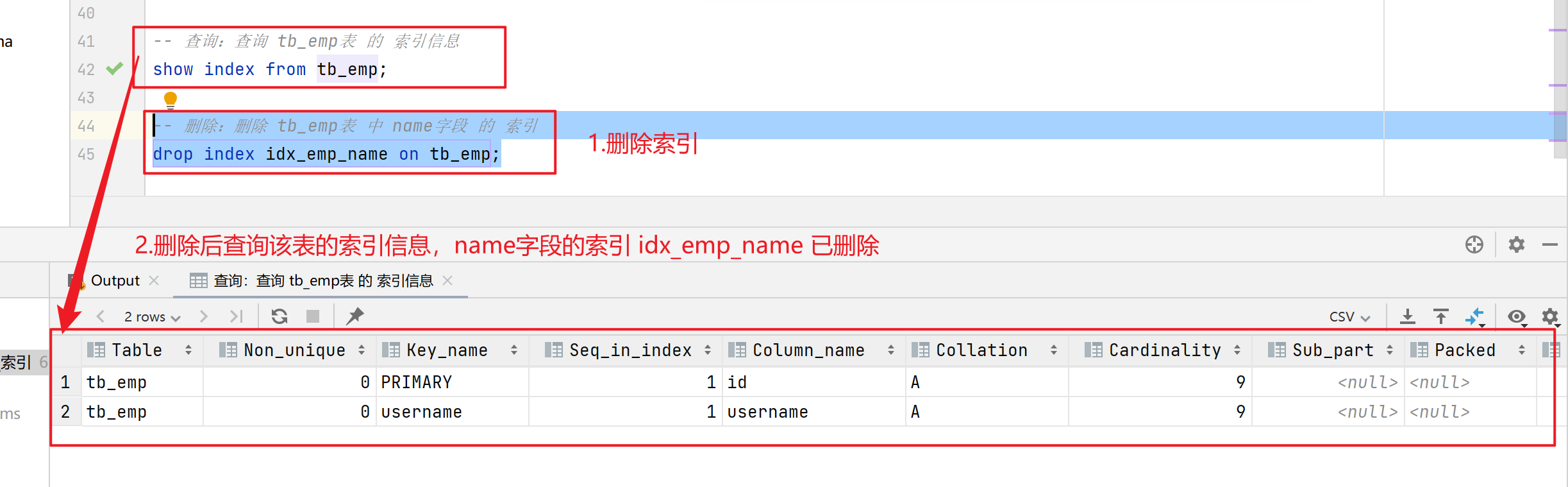
查询:查询 tb_emp表 的 索引信息
-
删除:删除 tb_emp表 中 name字段 的 索引
(5) 注意事项
-
主键字段,在建表时,会自动创建主键索引(所有索引中性能最高的)。

-
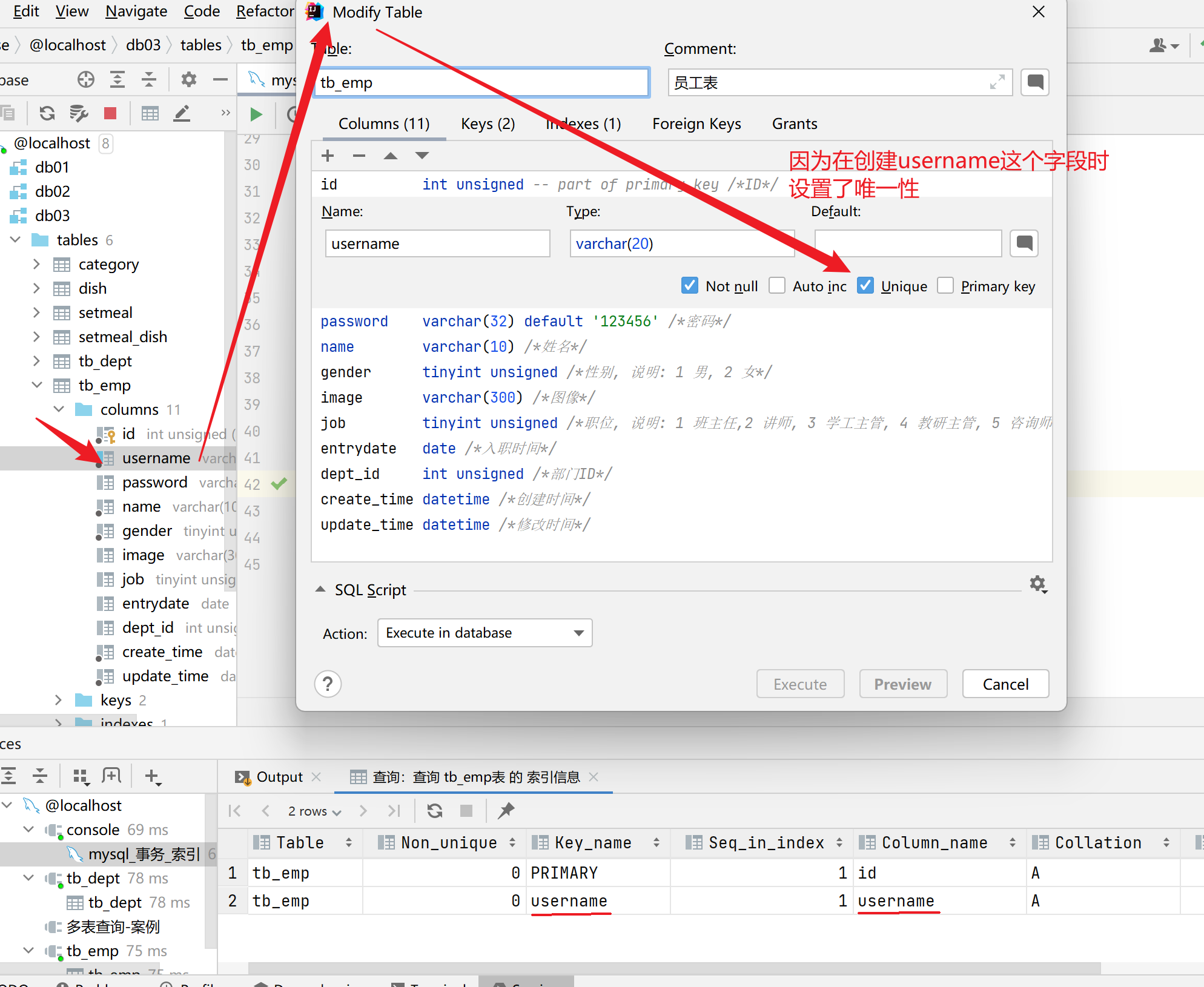
添加唯一约束时,数据库实际上会添加唯一索引。
(6) 总结
①. 介绍
- 索引是帮助数据库高效获取数据的数据结构 。
②. 结构
- MySQL数据库中默认的索引结构是 B+tree (重点理解其特点)。
③. 语法
- 创建
- 查询
- 删除















 193
193











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









