







二叉树是数据结构中树型结构的一种常用的重要类型。二叉树可以表示实际问题抽象得来的层级结构。因此,灵活熟练使用二叉树及其相关算法是学习者的必修课。
树是由一个个节点组成的,就像是现实中树由主干分支成无数的枝条,二叉树也是由唯一的根结点分支分层,形成相应的数据结构。二叉树就像它的名称形容的那样,每个节点最多分叉出两个节点,一左一右,分别称呼为左节点和右节点。
了解了二叉树的相关结构,先介绍一种简单的二叉树——二叉排序树。
接下来将会介绍,给出一个整型数组中存储着若干个整型数据,如何将其存入二叉排序树,并按照一定的顺序输出。
一、二叉排序树
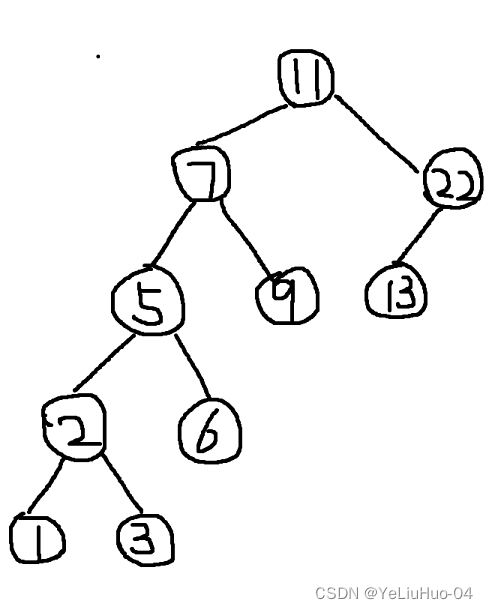
给出的整型数组:
int[] Arr={11,7,9,22,5,13,2,1,6,3};1、节点类的创建
节点作为二叉树的最小单位,节点类的创建一定要满足二叉树的数据逻辑,在节点类中属性设置时,分别设置左节点和右节点,以及整型数据的保存,再创建构造函数方法以便于节点的初始化。代码如下:
class treeNode{
public treeNode left;
public treeNode right;
public int data;
public treeNode(int data){
this.data=data;
}
}2、二叉排序树的搭建
有了节点,我们就可以像搭积木一样把节点组织成二叉树。创建循环遍历数组,并使用结点增添方法,把数组中的每个数据创建的相应节点加入到树中。代码如下:
private treeNode mid=null;
public void addNode(treeNode node){
if(mid==null){
mid=node;
}else {
treeNode current=mid;
while (true) {
if (current.data > node.data){
if(current.left==null) {
current.left = node;
break;
}else {
current = current.left;
}
}
if(current.data < node.data){
if(current.right==null) {
current.right = node;
break;
}else{
current=current.right;
}
}
}
}
}先创建根节点使之为空,创建current节点导航,以便在二叉树中找到合适的位置来插入新节点,后续通过while循环实现如果新节点的值小于当前节点的值(current.data > node.data),则将向左子树移动,如果左子树为空,则将新节点 node 插入到左子树中,否则继续向左移动。如果新节点的值大于当前节点的值(current.data < node.data),则将向右子树移动,如果右子树为空,则将新节点 node 插入到右子树中,否则继续向右移动。
搭建的具象图如下:
3、二叉树排序树的遍历
二叉排序树和链表一样都是线性数据结构,常见的遍历方法包括前序、中序和后序遍历。
(1)递归实现
只需确认当前递归函数的节点不为空即可实现递归遍历:
public void ROut(treeNode mid){
if(mid!=null){
//System.out.print(mid.data+" "); 前序
ROut(mid.left);
System.out.print(mid.data+" "); //中序
ROut(mid.right);
//System.out.print(mid.data+" "); 后序
}
}中序遍历输出结果如下:
1 2 3 5 6 7 9 11 13 22
可见中序遍历结果是升序排列的。
后面会有几种非递归方法的实现。
(2)栈方法实现
该方法要用到java.util包中的Stack类。堆栈(Stack)是一种先进后出(Last-In-First-Out,LIFO)的数据结构,其中最后压入堆栈的元素最先弹出。利用Stack的特性,代码如下:
public void COut(treeNode mid){
if (mid == null) {
return;
}
Stack<treeNode> stack = new Stack<>();
treeNode current = mid;
while (!stack.isEmpty() || current != null) {
if (current != null) {
stack.push(current);
current = current.left;
} else {
current = stack.pop();
System.out.print(current.data+" ");
current = current.right;
}
}
}while循环中的isEmpty()方法用于查询stack中的是否为空,为空返回boolean值true,否则返回true,再通过判断current节点是否为空,当二者都为“空”时才退出循环,确保遍历的完整性。
push()方法是将元素推入堆栈的顶部,pop()方法从堆栈的顶部弹出并删除元素并将该元素返回。stack类中还有其他实用的方法如:peek()查看堆栈的顶部元素,但不删除它。search(Object)查找元素在堆栈中的位置(从顶部开始计数)。如果元素不存在,则返回 -1。
以上代码输出结果与上一条递归实现结果相同。
(3)队列实现分行输出
通过使用嵌套列表来实现分行输出,一个总列表中存储着每一行的列表,每一行的列表中存储着该行的数据。具体实现如下:
public void LOut(treeNode mid){
List<List<Integer>> list=new LinkedList<>();
if(mid==null){
return;
}
Queue<treeNode> queue=new LinkedList<>();
treeNode current=mid;
queue.offer(current);
while(queue.size()>0){
int size= queue.size();
List<Integer> dataList=new LinkedList<>();
for(int i=0;i<size;i++){
treeNode node=queue.poll();
dataList.add(node.data);
if(node.left!=null){
queue.offer(node.left);
}
if(node.right!=null){
queue.offer(node.right);
}
}
list.add(dataList);
}
for(int i=0;i< list.size();i++){
for(int j=0;j<list.get(i).size();j++){
System.out.print(list.get(i).get(j)+" ");
}
System.out.println();
}
}offer()方法用于将指定的元素e插入到队列的末尾(尾部),poll()方法用于获取队列的头部元素,并从队列中移除该元素。最后通过循环输出列表的每一行,输出结果如下:
11
7 22
5 9 13
2 6
1 3 (4)Z型输出
类似于分行输出,二叉排序树的Z型输出是第一行从左往右(第一行只有根节点),第二行从右往左,第三行从左往右......依次遍历结束以达成Z型或者“蛇形”的输出。实现方法如下:
public void ZOut(treeNode mid){
if (mid == null) {
return;
}
Stack<treeNode> currentLevel = new Stack<>();
Stack<treeNode> nextLevel = new Stack<>();
currentLevel.push(mid);
boolean leftToRight = true;
while (!currentLevel.isEmpty()) {
treeNode currentNode = currentLevel.pop();
System.out.print(currentNode.data + " ");
if (leftToRight) {
if (currentNode.left != null) {
nextLevel.push(currentNode.left);
}
if (currentNode.right != null) {
nextLevel.push(currentNode.right);
}
} else {
if (currentNode.right != null) {
nextLevel.push(currentNode.right);
}
if (currentNode.left != null) {
nextLevel.push(currentNode.left);
}
}
if (currentLevel.isEmpty()) {
leftToRight = !leftToRight;
Stack<treeNode> temp = currentLevel;
currentLevel = nextLevel;
nextLevel = temp;
}
}
}在上面的代码中,zTraversal 方法使用两个栈,currentLevel用于存储当前层级的节点,nextLevel 用于存储下一层级的节点。它还使用一个布尔值 leftToRight 来控制当前层级节点值的输出方向。最终,它会按照"Z型"的顺序输出节点值。输出结果如下:
11 22 7 5 9 13 6 2 1 3 二、哈夫曼树
哈夫曼树是二叉树中的特殊的一种,也具有二叉树的特性,这里是利用哈夫曼树的特殊编码属性来进行对文本的压缩和解压。
1.节点类的创建
与二叉排序树不同的是,哈夫曼树的节点类中的属性应更具体且更有针对性,作为二叉树的一种,哈夫曼树的节点应该同样拥有左右节点,并且考虑到是对文本数据的保存,类应具有字符属性,以及整型属性来记录同一字符的出现次数,用字符串来存储该字符对应的哈夫曼编码。以及相关的构造函数,代码如下:
class treeNode{
public treeNode left;
public treeNode right;
public int data;
public char c;
public String string="";
public treeNode(int data){
this.data=data;
}
}2.读取文本内容
输入文件地址和文件名,使用io包中的BufferedReader类及其方法等,实现对文本文件内容的读取,并将读取到的内容以字符串的形式返回,代码如下:
public String readFile(String path){
File file=new File(path);
FileReader fr=null;
String dataStr="";
try{
fr=new FileReader(file);
BufferedReader bfr=new BufferedReader(fr);
String s="";
while((s=bfr.readLine())!=null){
dataStr+=s;
}
}catch (Exception e){
throw new RuntimeException(e);
}
return dataStr;
}3.哈夫曼树的搭建以及哈夫曼编码的形成
先对文本数据进行处理,对以上方法返回的字符串进行遍历,对每个字符都创建一个节点,char属性保存相应的字符,int类型储存出现次数,将所有节点加入到同一个节点队列中,并通过快速排序算法将队列中的节点按照出现次数从少到多排序,代码如下:
public void countString(String str){
for (int i = 0; i < str.length(); i++) {
char currentChar = str.charAt(i);
boolean build=true;
for(int j=0;j<list.size();j++){
if(currentChar==list.get(j).c){
list.get(j).data++;
build=false;
}
}
if(build){
treeNode node = new treeNode(1);
node.c=currentChar;
list.add(node);
}
}
}
public void quickSort(List<treeNode> list,int low,int high){
if (low >= high) {
return;
}
treeNode pivot = list.get(low);
int l = low;
int r = high;
treeNode temp;
while (l < r) {
while (l < r && list.get(r).data >= pivot.data) {
r--;
}
while (l < r && list.get(l).data <= pivot.data) {
l++;
}
if (l < r) {
temp = list.get(l);
list.set(l,list.get(r));
list.set(r,temp);
}
}
list.set(low,list.get(l));
list.set(l,pivot);
if (low < l) {
quickSort(list, low, l - 1);
}
if (r < high) {
quickSort(list, r + 1, high);
}
}接下来是哈夫曼树的搭建,已经排序好的队列中的节点int属性最小的两项移除并相加得到的和创建为新的节点的int类型属性,并将得到的新节点作为移除的最小两项的双亲,再将该新节点加入到队列中,重新排序,重复以上操作,代码如下:
public treeNode buildTree(List<treeNode> list){
while(list.size()>1){
quickSort(list,0, list.size()-1);
treeNode leftNode=list.remove(0);
treeNode rightNode=list.remove(0);
treeNode node=new treeNode(leftNode.data+rightNode.data);
node.left=leftNode;
node.right=rightNode;
list.add(node);
}
return list.remove(0);
}哈夫曼树搭建好后,就要对每个叶子节点进行编码,从根节点开始,每向左节点前进一次就对节点的String属性进行加“0”,而每向右前进一次就加“1”。最终得到的每个叶子节点的String属性为只含有0和1的字符串就是该节点代表的字符哈夫曼编码,并将编码完毕的叶子节点加入队列,代码如下:
public void setCode(treeNode root){
if(root!=null){
if(root.left!=null) {
root.left.string = root.string+"0";
setCode(root.left);
}
if(root.right!=null) {
root.right.string = root.string+"1";
setCode(root.right);
}
}
}
public void outLeave(treeNode root){
if(root.left==null&&root.right==null){
list.add(root);
System.out.println(root.c+" : "+root.string);
}else{
if(root.left!=null) {
outLeave(root.left);
}
if(root.right!=null) {
outLeave(root.right);
}
}
}再对原文本得到的字符串中的每个字符进行替换,得到只由哈夫曼编码表示的字符串,代码如下:
public String Replace(String str){
String reStr=str;
for(int i=0;i<list.size();i++){
reStr=reStr.replace(String.valueOf(list.get(i).c),list.get(i).string);
}
System.out.println(reStr);
return reStr;
}4.编码数据的保存
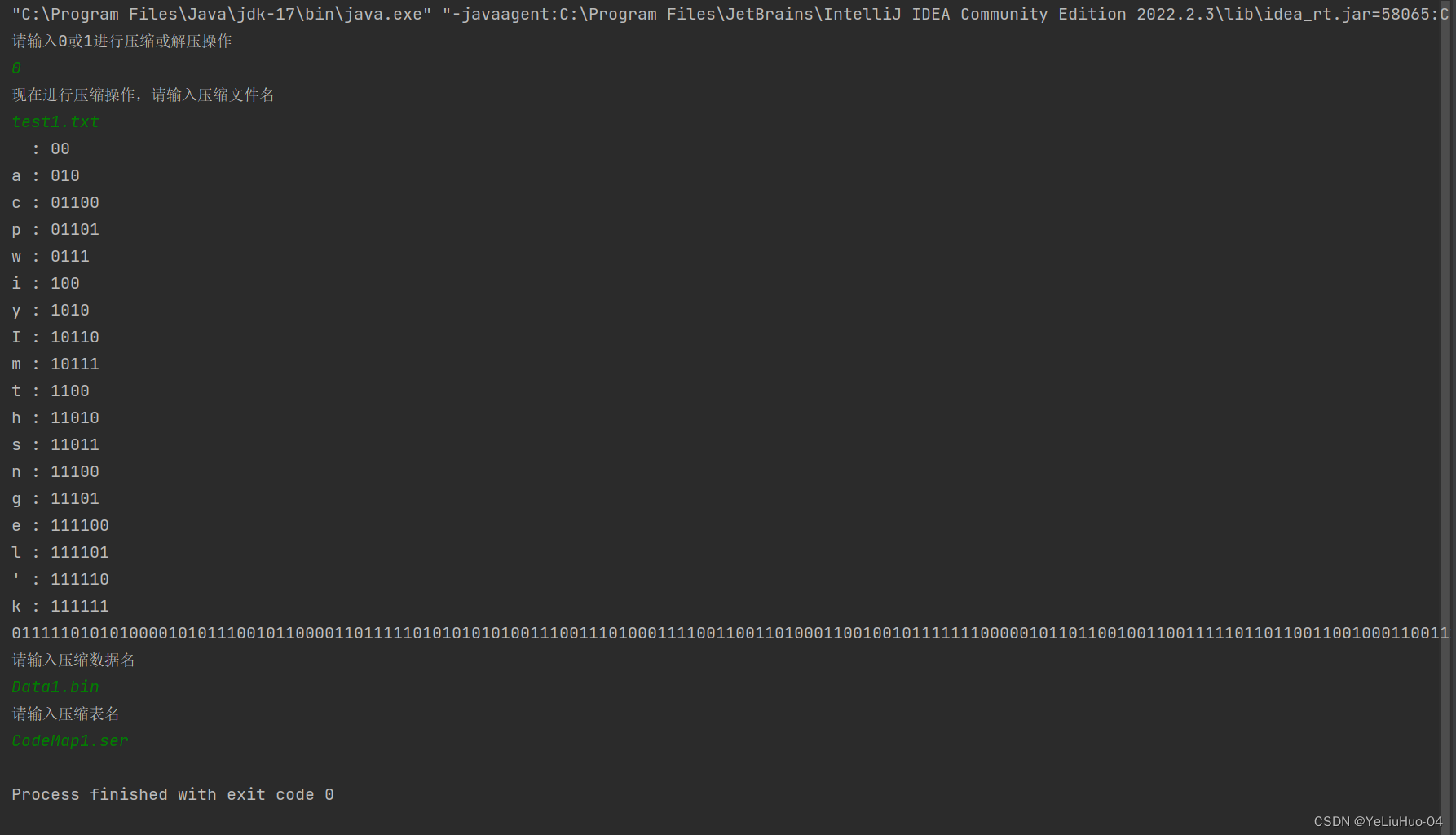
用哈夫曼编码替换字符得到的01字符串,每八位存为一个字节,不足八位的在后位补0凑成一个字节。用一个字节数组将这些byte类型的字节储存起来。再用io包类的FileOutputStream类的write()方法,将字节数组以.bin文件的格式保存到文件夹。并创建哈希表将每个字符及其对应哈夫曼编码对应存储,同样使用io包类的ObjectOutputStream方法的writeObject()方法,将哈希表以.ser格式的文件保存到文件夹。代码如下:
public int transByte(String str){
int length = str.length();
int padding = 8 - (length % 8);
if(length%8!=0) {
for (int i = 0; i < padding; i++) {
str += "0";
}
}
byte[] bytes = new byte[str.length() / 8];
for (int i = 0; i < bytes.length; i++) {
String byteString = str.substring(i * 8, (i + 1) * 8);
byte b = (byte) Integer.parseInt(byteString, 2);
bytes[i] = b;
}
System.out.println("请输入压缩数据名");
Scanner scanner=new Scanner(System.in);
String dataName=scanner.next();
try (FileOutputStream fos = new FileOutputStream(dataName)) {
fos.write(bytes);
} catch (IOException e) {
e.printStackTrace();
}
return padding;
}
public void cMap(){
Map<Character,String> codeMap=new HashMap<>();
for(int i=0;i<list.size();i++){
codeMap.put(list.get(i).c,list.get(i).string);
}
System.out.println("请输入压缩表名");
Scanner scanner=new Scanner(System.in);
String mapName=scanner.next();
try (ObjectOutputStream oos = new ObjectOutputStream(new FileOutputStream(mapName))) {
oos.writeObject(codeMap);
} catch (IOException e) {
e.printStackTrace();
}
}5.解压实现
解压时同样要用到io包内的类与方法。BufferedInputStream来缓冲输入数据的文件,while循环中从缓冲输入流中读取数据,将读取的字节数存储在bytesRead中,如果已经读取到文件末尾,read 方法将返回 -1。buffer[i] & 0xFF将字节数据转换成无符号整数,确保字节中的位不会被当作负数处理。Integar.toBinaryString是将无符号整数转换成二进制字符串。String.format("%8s",...)确保二进制字符串是 8 位长,不足的位数用0填充。另外,还要将补充的0位进行删除,以确保后续替换的正常进行。originCode.append()将格式化后的二进制字符串追加到 originCode 中。不仅要对原数据码解压,还要读取码表以实现对解压01代码的字符与哈夫曼编码的替换,得到原来的文本。代码如下:
public static String unzipData(String path){
StringBuilder originCode=new StringBuilder();
try{
FileInputStream file=new FileInputStream(path);
BufferedInputStream bfi=new BufferedInputStream(file);
int bytesRead;
byte[] buffer = new byte[1024];
while ((bytesRead = bfi.read(buffer)) != -1) {
for (int i = 0; i < bytesRead; i++) {
originCode.append(String.format("%8s", Integer.toBinaryString(buffer[i] & 0xFF)).replace(' ', '0'));
}
}
bfi.close();
}catch(Exception e){
e.printStackTrace();
}
int length = originCode.length();
int i = length - 1;
while (i >= 0 && originCode.charAt(i) == '0') {
i--;
}
return originCode.substring(0, i + 1).toString();
}
public static Map<String, Character> unzipRule(String path){
Map<Character,String> map=null;
try {
FileInputStream file = new FileInputStream(path);
ObjectInputStream objI=new ObjectInputStream(file);
map=(Map<Character, String>) objI.readObject();
}catch (IOException | ClassNotFoundException e){
e.printStackTrace();
}
Map<String, Character> newMap = new HashMap<>();
for (Map.Entry<Character, String> entry : map.entrySet()) {
char key = entry.getKey();
String value = entry.getValue();
newMap.put(value, key);
}
return newMap;
}将01字符串替换为原文本的方法是从前往后按顺序推进,嵌套的for循环,用于从字符串中提取不同长度的子串,从start开始,end逐渐增加,直到等于字符串的长度。在这个循环中,遍历映射map中的所有键。检查提取的子串cut是否与当前映射的键key相等。如果子串匹配映射的键,就将映射中对应的字符追加到builder中。注意:能够按照次序从前往后进行的基础在于,字符的哈夫曼编码长度不一,但是短的编码不会与长的编码有重复,体现了哈夫曼编码的高效和稳定。代码如下:
public String restore(String Str, HashMap<String, Character> map) {
boolean ifAdd=map.containsValue('@');
String addStr="";
if(ifAdd) {
for (Map.Entry<String, Character> entry : map.entrySet()) {
if (entry.getValue().equals('@')) {
addStr=entry.getKey();
}
}
}
int addNum=addStr.length();
Str=Str.substring(0,Str.length()-addNum);
int start = 0;
StringBuilder builder = new StringBuilder();
while (start < Str.length()) {
for (int end = start + 1; end <= Str.length(); end++) {
String cut = Str.substring(start, end);
if (map.containsKey(cut)) {
builder.append(map.get(cut));
start = end;
break;
}
}
}
return builder.toString();
}
public void writeStringToFile(String content, String fileName) {
try {
BufferedWriter writer = new BufferedWriter(new FileWriter(fileName));
writer.write(content);
writer.close();
System.out.println("字符串已成功写入文件 " + fileName);
} catch (IOException e) {
System.err.println("写入文件时发生错误: " + e.getMessage());
}
}以下的主函数能够实现在输入框内选择压缩或者解压和实现输入文件名的作用。
public static void main(String[] args) {
HfmTree hfmTree=new HfmTree();
String file="C:\\Users\\罗浩洋\\Desktop\\JAVA\\HfmTree\\";
System.out.println("请输入0或1进行压缩或解压操作");
Scanner scanner=new Scanner(System.in);
int choose=scanner.nextInt();
boolean judge = false;
if(choose==0){
judge=false;
}
if(choose==1){
judge=true;
}
if(!judge) {
System.out.println("现在进行压缩操作,请输入压缩文件名");
String txtName=scanner.next();
String Str=hfmTree.readFile(file+txtName);
hfmTree.countString(Str);
treeNode root=hfmTree.buildTree(hfmTree.list);
hfmTree.setCode(root);
hfmTree.outLeave(root);
String reStr=hfmTree.Replace(Str);
int add=hfmTree.transByte(reStr);
String addStr="";
if(add!=0&&add!=8){
for(int i=0;i<add;i++){
addStr+="z";
}
}
hfmTree.cMap(addStr);
}
if(judge) {
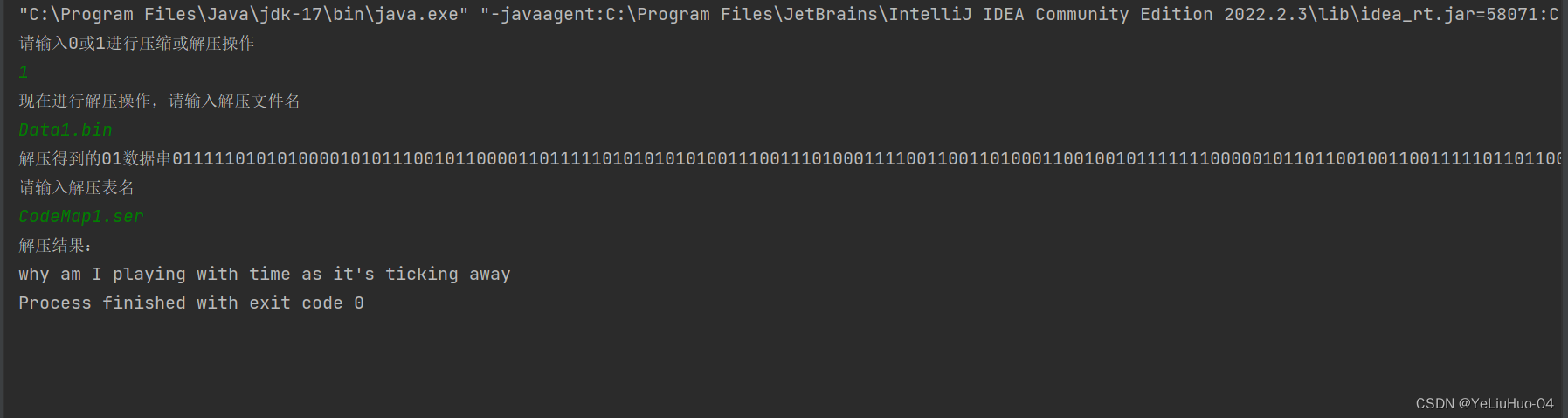
System.out.println("现在进行解压操作,请输入解压文件名");
String unzipDataName=scanner.next();
String unzipStr = unzipData(file+unzipDataName);
System.out.println("解压得到的01数据串"+unzipStr);
System.out.println("请输入解压表名");
String unzipMapName=scanner.next();
HashMap<String, Character> map = unzipRule(file+unzipMapName);
String contentToWrite = hfmTree.restore(unzipStr, map);
System.out.println("请输入你的输出文档名");
String fileName = scanner.next();
hfmTree.writeStringToFile(contentToWrite, fileName);
}
}效果图如下:
以上就是全部关于二叉排序树和基于哈夫曼编码的解压缩实现。
















 2801
2801











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











