









equals和HashCode都是用来去重的,即判断两个对象是否相等。如果是String类则我们直接用.equals()判断,如果是我们自己定义的类,需要有自己的判断方法,重写equals,如果是集合(HashSet、HashMap)判断加入的元素是否为重复,并且加入的元素是我们自己定义的类,这时用重写equals和HashCode两个一起判断:插入的元素是否相等(HashSet中),插入的key是否相同(HashMap中)。
设计一个标准的实体类四大原则:
1、封装:属性私有化,提供get/set方法等;
2、提供无参构造;
3、重写toString()、HashCode()、equals()这三个方法,(继承自根Object,不必须都重写按自己的需求定);
4、实现序列化接口(implements Serializable),这样类的对象可以经过二进制数据流进行传输。
例如:
class Person2 implements Serializable{
private static final long serialVersionUID = 1L;
private String name;
private int age;
public Person2(){}
public Person2(String name, int age){
this.name = name;
this.age = age;
}
// 重写equals,定义同一类型,并且属性name和age全部相等则实例对象相等
public boolean equals(Object obj){
if(this == obj){
return true;
}
if(!(obj instanceof Person2)){
return false;
}
Person2 p = (Person2) obj;
if(this.name.equals(p.name)&&this.age == p.age){
return true;
}else{
return false;
}
}
// 重写HashCode将对象的某些信息映射成一个数值---散列值
public int hashCode(){
return this.name.hashCode()*this.age;
}
// 重写toString打印自己想要的格式,如果不重写默认直接继承Object类的toString 方法是获取对象在内存中的值可能会乱码
public String toString(){
return "姓名:"+this.name+";年龄:"+this.age;
}
}
1、首先说一下,什么情况下要重写toString,object类里的toString只是把字符串的直接打印,数字的要转化成字符再打印,而对象,则直接打印该对象的hash码。所以当你要想按照你想要的格式去字符串一些对象的时候,就需要重写toString了。比如一个Student对象,直接toString肯定是一个hash码。然而你想得到的比如是:name:***,age:***。这时就重写toString就是在toString里写:System.out.println(“name:”+student.getName);System.out.println(“age:”+student.getAge)。这样再toString就直接反回你想要的格式。通过查api我们就可以知道HashSet的toString是把s的值格式化成[*, * ,*],就是给s的加个中括号,而且用逗号分开。而HashMap的toString是把m的值格式化成{key1=value1,key2=value2,key3=value3}所以你打印出来的是那样的格式,这就是重写toString的作用
equals和HashCode都是用来鉴定两个对象是否相等的。2、一般来讲,equals是给用户调用的,如果你想判断两个实例对象是否相等,可以在自己定义的类中重写equals方法,然后在代码中调用这个方法就可以判断是否相等了。
简单的说,equals就是从表面和自己定义的规范内容上看两个对象是否相等。
举个例子,有个学生类,属性只有姓名和性别,那么我们可以认为只要姓名和性别相等,那么就说这2个对象是相等的。
3、HashCode的方法只有在散列集合中用到,这样的散列集合包括HashSet、HashMap以及HashTable。
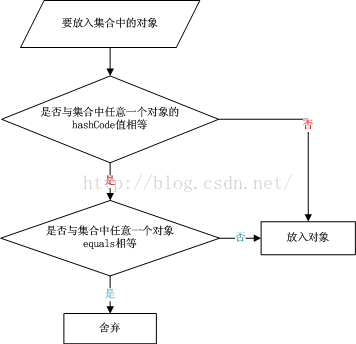
例如在集合存储中,判断并不再插入重复的元素,也许大多数人都会想到调用equals方法来逐个进行比较,这个方法确实可行。但是如果集合中已经存在一万条数据或者更多的数据,如果采用equals方法去逐一比较,效率必然是一个问题。此时hashCode方法的作用就体现出来了。
当集合要添加新的对象时,先调用这个对象的hashCode方法,得到对应的hashcode值,实际上在HashMap的具体实现中会用一个table保存已经存进去的对象的hashcode值,如果table中没有该hashcode值,它就可以直接存进去,不用再进行任何比较了;如果存在该hashcode值, 就调用它的equals方法(可是被重写的)与新元素进行比较,相同的话就不存了,不相同就散列其它的地址,所以这里存在一个冲突解决的问题,这样一来实际调用equals方法的次数就大大降低了,说通俗一点:Java中的hashCode方法就是根据一定的规则将与对象相关的信息(比如对象的存储地址,对象的字段等)映射成一个数值,这个数值称作为散列值
将元素放在集合中的流程:















 155
155

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









