







面试题汇总第三弹
Springboot集成RabbitMQ关于对象传输过程中的序列化及反序列化
在Springboot项目中使用RabbitMQ作为消息中间件使用过程中,有时候我们会使用java对象作为传输的消息,默认情况下允许使用java对象作为传输的消息,但是却有着严格的条件限制:
1、生产者和消费者中的java对象必须相同;
2、java对象中的包名也必须一致。
如果在项目中开发者和消费者属于同一个项目则没有问题,如果开发者和消费者属于不同项目则第2个条件则比较麻烦,当然也有解决办法。
- 比如实体类作为基础包引入生产者和消费者项目中等等。
- 通过在生产者中将java对象转为json字符串,在消费者中将json字符串转回java对象。这种方法有很多弊端,首先要增加代码量(互相转换),还有就是针对不同的对象需要增加转换的代码。例如Jackson转译器。
- 生产者
/**
* 测试传输对象消息
* @return
*/
@GetMapping("/sendDirectMessage2")
public String sendDirectMessage2() {
Person person = new Person();
person.setId(String.valueOf(UUID.randomUUID()));
person.setName("zhangsan");
//将对象序列化为json串
rabbitTemplate.setMessageConverter(new Jackson2JsonMessageConverter());
//将消息携带绑定键值:TestDirectRouting 发送到交换机TestDirectExchange
rabbitTemplate.convertAndSend("testDirectExchange", "testDirectRouting2", person);
return "ok";
}
- 消费端
package com.yemuxia.config;
import org.springframework.amqp.rabbit.annotation.RabbitListenerConfigurer;
import org.springframework.amqp.rabbit.listener.RabbitListenerEndpointRegistrar;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.messaging.converter.MappingJackson2MessageConverter;
import org.springframework.messaging.handler.annotation.support.DefaultMessageHandlerMethodFactory;
import org.springframework.messaging.handler.annotation.support.MessageHandlerMethodFactory;
/**
* @author 史凯强
* @date 2021/12/23 21:11
* @desc
**/
@Configuration
public class RabbitConfig implements RabbitListenerConfigurer {
// 可以将json串反序列化为对象
@Override
public void configureRabbitListeners(RabbitListenerEndpointRegistrar rabbitListenerEndpointRegistrar) {
rabbitListenerEndpointRegistrar.setMessageHandlerMethodFactory(messageHandlerMethodFactory());
}
@Bean
MessageHandlerMethodFactory messageHandlerMethodFactory(){
DefaultMessageHandlerMethodFactory messageHandlerMethodFactory = new DefaultMessageHandlerMethodFactory();
messageHandlerMethodFactory.setMessageConverter(mappingJackson2MessageConverter());
return messageHandlerMethodFactory;
}
@Bean
public MappingJackson2MessageConverter mappingJackson2MessageConverter(){
return new MappingJackson2MessageConverter();
}
}

HashMap的底层原理
数据结构
数组+链表+(红黑树jdk>=8)
Map的底层都是通过哈希表进行实现的,那先来看看什么是哈希表。
JDK1.8之前,哈希表底层采用数组+链表实现,即使用链表处理冲突,同一hash值的元素都存储在一个链表里。但是当位于一个桶中的元素较多,即hash值相等的元素较多时,通过key值依次查找的效率较低。
JDK1.8中,哈希表存储采用数组+链表+红黑树实现,当链表长度超过阈值(8)时,将链表转换为红黑树,这样大大减少了查找时间。

说明:
1,进行键值对存储时,先通过hashCode()计算出键(K)的哈希值,然后再数组中查询,如果没有则保存。
2,但是如果找到相同的哈希值,那么接着调用equals方法判断它们的值是否相同。只有满足以上两种条件才能认定为相同的数据,因此对于Java中的包装类里面都重写了hashCode()和equals()方法。
JDK1.8引入红黑树大程度优化了HashMap的性能,根据对象的hashCode和equals方法来决定的。如果我们往集合中存放自定义的对象,那么保证其唯一,就必须复写hashCode和equals方法建立属于当前对象的比较方式。
简述RPC远程调用
RPC是指远程过程调用(英语:Remote Procedure Call,缩写为 RPC)是一个计算机通信协议。处于OSI体系结构的第五层:会话层,也是tcp/ip协议栈的第4层(应用层)。其下就是TCP/IP协议。
也就是说两台服务器A,B,一个应用部署在A服务器上,想要调用B服务器上应用提供的函数/方法,由于不在一个内存空间,不能直接调用,需要通过网络来表达调用的语义和传达调用的数据
实现远程通信的大致步骤
-
要解决通讯的问题,主要是通过在客户端和服务器之间建立TCP连接,远程过程调用的所有交换的数据都在这个连接里传输。连接可以是按需连接,调用结束后就断掉,也可以是长连接,多个远程过程调用共享同一个连接。
-
要解决寻址的问题,也就是说,A服务器上的应用怎么告诉底层的RPC框架,如何连接到B服务器(如主机或IP地址)以及特定的端口,方法的名称名称是什么,这样才能完成调用。比如基于Web服务协议栈的RPC,就要提供一个endpoint URI,或者是从UDDI服务上查找。如果是RMI调用的话,还需要一个RMI Registry来注册服务的地址。
-
当A服务器上的应用发起远程过程调用时,方法的参数需要通过底层的网络协议如TCP传递到B服务器,由于网络协议是基于二进制的,内存中的参数的值要序列化成二进制的形式,也就是序列化(Serialize)或编组(marshal),通过寻址和传输将序列化的二进制发送给B服务器。
-
B服务器收到请求后,需要对参数进行反序列化(序列化的逆操作),恢复为内存中的表达方式,然后找到对应的方法(寻址的一部分)进行本地调用,然后得到返回值。
-
返回值还要发送回服务器A上的应用,也要经过序列化的方式发送,服务器A接到后,再反序列化,恢复为内存中的表达方式,交给A服务器上的应用

rpc的简单实现:
参考文档1
mysql主从复制实现数据库同步
MySQL服务的主从架构一般都是通过binlog日志文件来进行的。即在主服务上打开binlog记录每一步的数据库操作,然后从服务上会有一个IO线程,负责跟主服务建立一个TCP连接,请求主服务将binlog传输过来。这时,主库上会有一个IO dump线程,负责通过这个TCP连接把Binlog日志传输给从库的IO线程。接着从服务的IO线程会把读取到的binlog日志数据写入自己的relay日志文件中。然后从服务上另外一个SQL线程会读取relay日志里的内容,进行操作重演,达到还原数据的目的。我们通常对MySQL做的读写分离配置就必须基于主从架构来搭建。

MySQL的binlog不光可以用于主从同步,还可以用于缓存数据同步等场景。
例如Canal,可以模拟一个slave节点,向MySQL发起binlog同步,然后将数据落地到Redis、Kafka等其他组件,实现数据实时流转。
搭建主从集群时,有两个必要的要求:
双方MySQL必须版本一致。至少需要主服务的版本低于从服务
两节点间的时间需要同步。
搭建的文章可以参考
参考文档1
java类和对象的生命周期
了解一下jvm(java虚拟机)中的几个比较重要的内存区域,这几个区域在java类的生命周期中扮演着比较重要的角色
- 方法区:在java的虚拟机中有一块专门用来存放已经加载的类信息、常量、静态变量以及方法代码的内存区域,叫做方法区。
- 常量池:常量池是方法区的一部分,主要用来存放常量和类中的符号引用等信息。
- 堆区:用于存放类的对象实例。
- 栈区:也叫java虚拟机栈,是由一个一个的栈帧组成的后进先出的栈式结构,栈桢中存放方法运行时产生的局部变量、方法出口等信息。当调用一个方法时,虚拟机栈中就会创建一个栈帧存放这些数据,当方法调用完成时,栈帧消失,如果方法中调用了其他方法,则继续在栈顶创建新的栈桢。
- 除了以上四个内存区域之外,jvm中的运行时内存区域还包括本地方法栈和程序计数器
类的生命周期
当我们编写一个java的源文件后,经过编译会生成一个后缀名为class的文件,这种文件叫做字节码文件,只有这种字节码文件才能够在java虚拟机中运行,java类的生命周期就是指一个class文件从加载到卸载的全过程。
一个java类的完整的生命周期会经历加载、连接、初始化、使用、和卸载五个阶段,当然也有在加载或者连接之后没有被初始化就直接被使用的情况,如图所示:
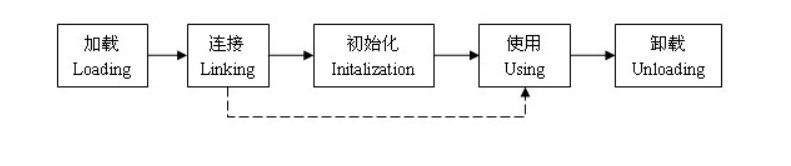
下面我们就依次来说一说这五个阶段
加载
在java中,我们经常会接触到一个词——类加载,它和这里的加载并不是一回事,通常我们说类加载指的是类的生命周期中加载、连接、初始化三个阶段。
在加载阶段,java虚拟机会做什么工作呢?其实很简单,就是找到需要加载的类并把类的信息加载到jvm的方法区中,然后在堆区中实例化一个java.lang.Class对象,作为方法区中这个类的信息的入口。
类的加载方式比较灵活,我们最常用的加载方式有两种,一种是根据类的全路径名找到相应的class文件,然后从class文件中读取文件内容;另一种是从jar文件中读取。另外,还有下面几种方式也比较常用:
- 从网络中获取:比如Applet。
- 根据一定的规则实时生成,比如设计模式中的动态代理模式,就是根据相应的类自动生成它的代理类。
- 从非class文件中获取,其实这与直接从class文件中获取的方式本质上是一样的,这些非class文件在jvm中运行之前会被转换为可被jvm所识别的字节码文件。
我们常用的hotspot虚拟机是采用的是当真正用到一个类的时候才对它进行加载。
加载阶段是类的生命周期中的第一个阶段,加载阶段之后,是连接阶段。有一点需要注意,就是有时连接阶段并不会等加载阶段完全完成之后才开始,而是交叉进行,可能一个类只加载了一部分之后,连接阶段就已经开始了。但是这两个阶段总的开始时间和完成时间总是固定的:加载阶段总是在连接阶段之前开始,连接阶段总是在加载阶段完成之后完成。
连接
连接阶段比较复杂,一般会跟加载阶段和初始化阶段交叉进行,这个阶段的主要任务就是做一些加载后的验证工作以及一些初始化前的准备工作,可以细分为三个步骤:验证、准备和解析。
验证:
当一个类被加载之后,必须要验证一下这个类是否合法,比如这个类是不是符合字节码的格式、变量与方法是不是有重复、数据类型是不是有效、继承与实现是否合乎标准等等。总之,这个阶段的目的就是保证加载的类是能够被jvm所运行。
准备:
准备阶段的工作就是为类的静态变量分配内存并设为jvm默认的初值,对于非静态的变量,则不会为它们分配内存。有一点需要注意,这时候,静态变量的初值为jvm默认的初值,而不是我们在程序中设定的初值。jvm默认的初值是这样的:
- 基本类型(int、long、short、char、byte、boolean、float、double)的默认值为0。
- 引用类型的默认值为null。
- 常量的默认值为我们程序中设定的值,比如我们在程序中定义final static int a = 100,则准备阶段中a的初值就是100。
解析:
这一阶段的任务就是把常量池中的符号引用转换为直接引用。那么什么是符号引用,什么又是直接引用呢?我们来举个例子:我们要找一个人,我们现有的信息是这个人的身份证号是1234567890。只有这个信息我们显然找不到这个人,但是通过公安局的身份系统,我们输入1234567890这个号之后,就会得到它的全部信息:比如安徽省黄山市余暇村18号张三,通过这个信息我们就能找到这个人了。这里,123456790就好比是一个符号引用,而安徽省黄山市余暇村18号张三就是直接引用。在内存中也是一样,比如我们要在内存中找一个类里面的一个叫做show的方法,显然是找不到。但是在解析阶段,jvm就会把show这个名字转换为指向方法区的的一块内存地址,比如c17164,通过c17164就可以找到show这个方法具体分配在内存的哪一个区域了。这里show就是符号引用,而c17164就是直接引用。在解析阶段,jvm会将所有的类或接口名、字段名、方法名转换为具体的内存地址。
连接阶段完成之后会根据使用的情况(直接引用还是被动引用)来选择是否对类进行初始化。
初始化
如果一个类被直接引用,就会触发类的初始化。在java中,直接引用的情况有:
- 通过new关键字实例化对象、读取或设置类的静态变量、调用类的静态方法。
- 通过反射方式执行以上三种行为。
- 初始化子类的时候,会触发父类的初始化。
- 作为程序入口直接运行时(也就是直接调用main方法)。
除了以上四种情况,其他使用类的方式叫做被动引用,而被动引用不会触发类的初始化。请看主动引用的示例代码:
- 案例演示了主动引用触发类的初始化的四种情况。
import java.lang.reflect.Field;
import java.lang.reflect.Method;
class InitClass{
static {
System.out.println("初始化InitClass");
}
public static String a = null;
public static void method(){}
}
class SubInitClass extends InitClass{}
public class Test1 {
/**
* 主动引用引起类的初始化的第四种情况就是运行Test1的main方法时
* 导致Test1初始化,这一点很好理解,就不特别演示了。
* 本代码演示了前三种情况,以下代码都会引起InitClass的初始化,
* 但由于初始化只会进行一次,运行时请将注解去掉,依次运行查看结果。
* @param args
* @throws Exception
*/
public static void main(String[] args) throws Exception{
// 主动引用引起类的初始化一: new对象、读取或设置类的静态变量、调用类的静态方法。
// new InitClass();
// InitClass.a = "";
// String a = InitClass.a;
// InitClass.method();
// 主动引用引起类的初始化二:通过反射实例化对象、读取或设置类的静态变量、调用类的静态方法。
// Class cls = InitClass.class;
// cls.newInstance();
// Field f = cls.getDeclaredField("a");
// f.get(null);
// f.set(null, "s");
// Method md = cls.getDeclaredMethod("method");
// md.invoke(null, null);
// 主动引用引起类的初始化三:实例化子类,引起父类初始化。
// new SubInitClass();
}
}
- 案例一
类的初始化过程是这样的:按照顺序自上而下运行类中的变量赋值语句和静态语句,如果有父类,则首先按照顺序运行父类中的变量赋值语句和静态语句。先看一个例子,首先建两个类用来显示赋值操作:
package cn.yemuxia.bean.lifecycle.test1;
/**
* @author 史凯强
* @date 2021/12/25 11:23
* @desc
**/
public class Field1 {
public Field1(){
System.out.println("Field1构造方法");
}
}
package cn.yemuxia.bean.lifecycle.test1;
/**
* @author 史凯强
* @date 2021/12/25 11:23
* @desc
**/
public class Field2 {
public Field2(){
System.out.println("Field2构造方法");
}
}
package cn.yemuxia.bean.lifecycle.test1;
/**
* @author 史凯强
* @date 2021/12/25 11:22
* @desc
**/
public class InitClass2 {
static{
System.out.println("运行父类静态代码");
}
public static Field1 f1 = new Field1();
public static Field1 f2;
}
package cn.yemuxia.bean.lifecycle.test1;
/**
* @author 史凯强
* @date 2021/12/25 11:21
* @desc
**/
public class SubInitClass2 extends InitClass2{
static{
System.out.println("运行子类静态代码");
}
public static Field2 f2 = new Field2();
}
package cn.yemuxia.bean.lifecycle.test1;
/**
* @author 史凯强
* @date 2021/12/25 11:20
* @desc 类的初始化过程是这样的:按照顺序自上而下运行类中的变量赋值语句和静态语句,
* 如果有父类,则首先按照顺序运行父类中的变量赋值语句和静态语句
**/
public class Test1 {
public static void main(String[] args) {
new SubInitClass2();
/**
* 运行结果预测:
* 运行父类静态代码
* Field1构造方法
* 运行子类静态代码
* Field2构造方法
*/
}
}

- 案例二
在类的初始化阶段,只会初始化与类相关的静态赋值语句和静态语句,也就是有static关键字修饰的信息,而没有static修饰的赋值语句和执行语句在实例化对象的时候才会运行。
package cn.yemuxia.bean.lifecycle.test2;
/**
* @author 史凯强
* @date 2021/12/25 11:23
* @desc
**/
public class Field1 {
public Field1(){
System.out.println("Field1构造方法");
}
}
package cn.yemuxia.bean.lifecycle.test2;
/**
* @author 史凯强
* @date 2021/12/25 11:23
* @desc
**/
public class Field2 {
public Field2(){
System.out.println("Field2构造方法");
}
}
package cn.yemuxia.bean.lifecycle.test2;
/**
* @author 史凯强
* @date 2021/12/25 12:20
* @desc
**/
public class InitClass2 {
public static Field1 f1 = new Field1();
public static Field1 f2;
static{
System.out.println("运行父类静态代码");
}
}
package cn.yemuxia.bean.lifecycle.test2;
/**
* @author 史凯强
* @date 2021/12/25 12:20
* @desc
**/
public class SubInitClass2 extends InitClass2{
public static Field2 f2 = new Field2();
static{
System.out.println("运行子类静态代码");
}
}
package cn.yemuxia.bean.lifecycle.test2;
/**
* @author 史凯强
* @date 2021/12/25 12:21
* @desc
**/
public class Test2 {
public static void main(String[] args) {
new SubInitClass2();
/**
* 预测结果
* Field1构造方法
* 运行父类静态代码
* Field2构造方法
* 运行子类静态代码
*/
}
}

- 案例三
类的使用包括主动引用和被动引用,主动引用在初始化的章节中已经说过了,下面我们主要来说一下被动引用:
引用父类的静态字段,只会引起父类的初始化,而不会引起子类的初始化。
定义类数组,不会引起类的初始化。
引用类的常量,不会引起类的初始化。
package cn.yemuxia.bean.lifecycle.test3;
/**
* @author 史凯强
* @date 2021/12/25 12:36
* @desc
**/
public class InitClass {
static {
System.out.println("初始化InitClass");
}
public static String a = null;
public final static String b = "b";
public static void method(){}
}
package cn.yemuxia.bean.lifecycle.test3;
/**
* @author 史凯强
* @date 2021/12/25 12:36
* @desc
**/
public class SubInitClass extends InitClass{
static {
System.out.println("初始化SubInitClass");
}
}
package cn.yemuxia.bean.lifecycle.test3;
/**
* @author 史凯强
* @date 2021/12/25 12:37
* @desc
**/
public class Test3 {
public static void main(String[] args) {
//String a = SubInitClass.a;// 引用父类的静态字段,只会引起父类初始化,而不会引起子类的初始化
/**
* 运行结果
* 初始化InitClass
*/
//String b = InitClass.b;// 使用类的常量不会引起类的初始化
/**
* 运行结果
* 无任何打印
*/
SubInitClass[] sc = new SubInitClass[10];// 定义类数组不会引起类的初始化
/**
* 运行结果
* 无任何打印
*/
}
}
最后总结一下使用阶段:使用阶段包括主动引用和被动引用,主动饮用会引起类的初始化,而被动引用不会引起类的初始化。
当使用阶段完成之后,java类就进入了卸载阶段。
卸载
在类使用完之后,如果满足下面的情况,类就会被卸载:
- 该类所有的实例都已经被回收,也就是java堆中不存在该类的任何实例。
- 加载该类的ClassLoader已经被回收。
- 该类对应的java.lang.Class对象没有任何地方被引用,无法在任何地方通过反射访问该类的方法。
如果以上三个条件全部满足,jvm就会在方法区垃圾回收的时候对类进行卸载,类的卸载过程其实就是在方法区中清空类信息,java类的整个生命周期就结束了。
总结
对象基本上都是在jvm的堆区中创建,在创建对象之前,会触发类加载(加载、连接、初始化),当类初始化完成后,根据类信息在堆区中实例化类对象,初始化非静态变量、非静态代码以及默认构造方法,当对象使用完之后会在合适的时候被jvm垃圾收集器回收。读完本文后我们知道,对象的生命周期只是类的生命周期中使用阶段的主动引用的一种情况(即实例化类对象)。而类的整个生命周期则要比对象的生命周期长的多。
参考阅读
socket连接和http连接的区别
-
HTTP协议:应用层协议,HTTP协议是基于TCP连接的。主要解决如何包装数据
-
Socket是对TCP/IP协议的封装,Socket本身并不是协议,而是一个调用接口(API),通过Socket,我们才能使用TCP/IP协议。
tcp协议: 对应于传输层,ip协议: 对应于网络层 。TCP和IP协议主要解决数据如何在网络中传输;
-
http连接:http连接就是所谓的短连接,即客户端向服务器端发送一次请求,服务器端响应后连接即会断掉;
-
socket连接:socket连接就是所谓的长连接,理论上客户端和服务器端一旦建立起连接将不会主动断掉;但是由于各种环境因素可能会是连接断开,比如说:服务器端或客户端主机down了,网络故障,或者两者之间长时间没有数据传输,网络防火墙可能会断开该连接以释放网络资源。所以当一个socket连接中没有数据的传输,那么为了维持连接需要发送心跳消息~~具体心跳消息格式是开发者自己定义的。
















 266
266











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











