







#!/bin/bash
# name: remove_duplicates.sh
# Purpose: Find and delete duplicate files, keep only one copy of each file
ls -lS --time-style=long-iso | awk 'BEGIN {
getline; getline;
name1=$8; size=$5
}
{
name2=$8;
if (size==$5)
{
"md5sum "name1 | getline; csum1=$1;
"md5sum "name2 | getline; csum2=$1;
if ( csum1==csum2 )
{
print name1; print name2
}
};
size=$5; name1=name2;
}' | sort -u > duplicate_files
cat duplicate_files | xargs -I {} md5sum {} | \
sort | uniq -w 32 | awk '{ print $2 }' | \
sort -u > unique_files
echo Removing..
comm duplicate_files unique_files -3 | tee /dev/stderr | \
xargs rm
echo Removed duplicates files successfully. ls -lS 对当前目录下的所有文件按照文件大小进行排序并列出文件的详细信息。
--time-style=long-iso 告诉 ls 依照 ISO 格式打印日期。awk 读取 ls -lS 的输出,对行列进行
比较,找出重复文件。
代码的执行逻辑:
文件依据大小排序并列出,这样大小相同的文件就会排列在一起。识别大小相同
的文件是我们查找重复文件的第一步。接下来,计算这些文件的校验和。如果校验和相
同,那么这些文件就是重复文件,将被删除。
在进行主要处理之前,首先要执行 awk 的 BEGIN{} 语句块。该语句块读取文件所有的行并
初始化变量。处理 ls 剩余的输出都是在 {} 语句块中完成的。读取并处理完所有的行之后,
执行 END{} 语句块。
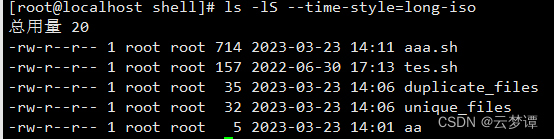
第1行输出告诉了我们文件的总数量,这个信息在本例中没什么用处。用 getline 读
取该行,然后丢弃掉。
接下来,需要比对每一行及其下一行的文件大小。在 BEGIN 语句块中,
使用 getline 读取文件列表的第一行并存储文件名和大小分别对应第8列和第5列)。当
awk 进入 {} 语句块后,依次读取余下的行(一次一行)。在该语句块中,将从当前行中得
到的文件大小与之前存储在变量 size 中的值进行比较。如果相等,那就意味着两个文件
至少在大小上是相同的,必须再用 md5sum 做进一步的检查。
读入一行后,该行就被保存在 $0 中,行中的每一列分别被保存在 $1 、 $2 … $n 中。我们将文
件的md5校验和分别保存在变量 csum1 和 csum2 中。变量 name1 和 name2 保存文件列表中相邻两个文件的文件名。如果两个文件的校验和相同,那它们肯定是重复文件,其文件名会被打印出来。从每组重复文件中找出一个文件,这样就可以删除其他副本了。计算重复文件的
md5sum 值并从每一组重复文件中打印出其中一个。这是通过用 -w 32 比较每一行的 md5sum 输出中的前32个字符( md5sum 的输出通常由32个字符的散列值和文件名组成)来找出那些不相同的行。这样,每组重复文件中的一个采样就被写入 unique_files 文件。
接下来,需要将 duplicate_files 中列出的、未包含在 unique_files 之内的文件全部删除。
comm 命令可以将其打印出来。对此,可以使用差集操作来实现。comm 只能处理排序过的文件。因此,使用 sort -u 来过滤 duplicate_files 和 unique_files文件。 tee 可以将文件名传给 rm 命令并输出。 tee 可以将输出发送至 stdout 和另一个文件中。也可以将文本重定向到 stderr 来实现终端打印功能。/dev/stderr是对应于 stderr (标准错误)的设备。通过重定向到 stderr 设备文件,发送到 stdin 的文本将会以标准错误的形式出现在终
端中。

















 247
247

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









