







在大语言模型(LLM)的部署中,通常采用“预训练-微调”范式。为了适应多样化的任务,参数高效的微调方法如低秩适应(LoRA)被广泛使用。然而,如何高效地服务这些微调变体仍然是一个未探索的问题。S-LoRA,一个为可扩展服务设计的LoRA适配器系统。S-LoRA通过统一分页、异构批处理和多GPU张量并行策略,实现了在单个GPU或多GPU上以极小的开销服务数千个LoRA适配器。
LoRA是一种参数高效的微调方法,通过在训练阶段添加可训练的低秩矩阵来适应预训练的LLM。这种方法显著减少了可训练参数的数量和内存消耗。在推理阶段,LoRA建议将低秩矩阵与基础模型的权重合并,从而在推理期间不增加额外的开销。
S-LoRA概述
S-LoRA包含三个主要创新点:统一分页、异构批处理和多GPU张量并行策略。这些创新使得S-LoRA能够有效地管理和调度主机和GPU内存,并在多个GPU之间协调并行性。
-
统一分页(Unified Paging):
- 内存池:S-LoRA引入了一个统一的内存池,用于管理动态的适配器权重和KV缓存张量。这个内存池通过分页机制来优化内存的使用,减少内存碎片,并平衡KV缓存和适配器权重的动态变化大小。
- 内存管理:由于GPU内存有限,S-LoRA将所有适配器存储在主内存中,并根据当前正在运行的查询动态地将所需的适配器加载到GPU内存中。这种管理方式允许系统在单个机器上存储和访问大量的适配器,而不受GPU内存大小的限制。
-
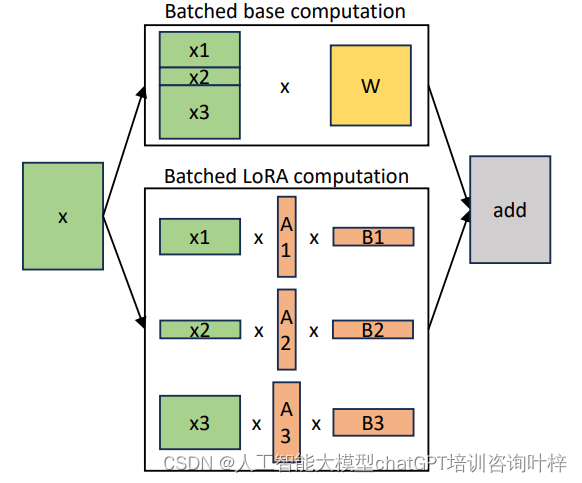
异构批处理(Heterogeneous Batching):
- 自定义CUDA内核:S-LoRA使用高度优化的自定义CUDA内核来执行不同秩和序列长度的LoRA适配器的批处理计算。这些内核能够在非连续的内存布局上运行,从而有效地处理来自不同适配器的计算。
- 延迟最小化:为了最小化在批处理不同适配器时引入的延迟开销,S-LoRA特别设计了这些内核,以支持不同秩的适配器进行高效的批处理,从而减少了与基线模型相比的额外开销。
-
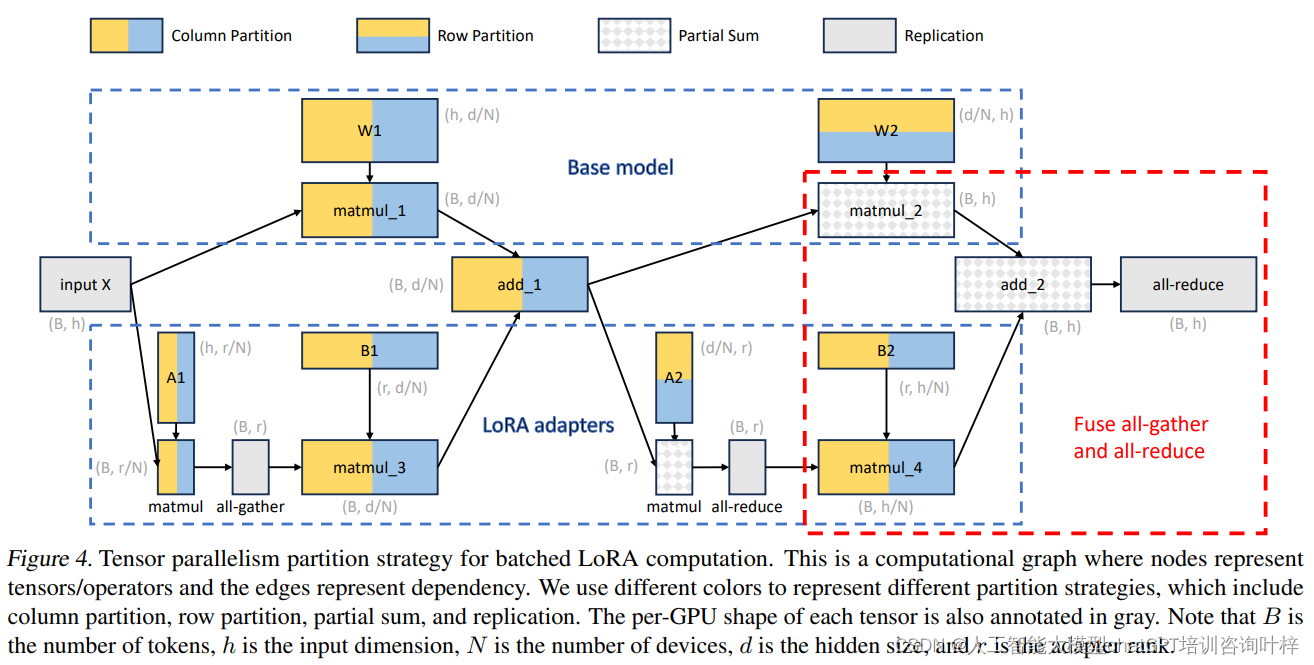
多GPU张量并行策略(Multi-GPU Tensor Parallelism):
- 模型并行性:S-LoRA设计了一种新的张量并行策略,用于在多个GPU上进行批量LoRA推理,支持大型变换器模型的高效服务。
- 通信成本:这种策略通过在小的中间张量上调度通信,并与基础模型的通信融合,最小化了LoRA计算引入的通信成本。
- 内存使用:该策略在内存使用上是最优的,因为它将所有权重矩阵分割到所有设备上,没有复制的权重矩阵,从而减少了每GPU的内存使用和延迟。
这些创新点共同作用,使得S-LoRA能够有效地管理和调度主机和GPU内存,并且在多个GPU之间协调并行性,从而实现了对数千个LoRA适配器的高效服务。通过这种方式,S-LoRA不仅提高了吞吐量,还保证了服务的低延迟,这对于实时应用和服务至关重要。此外,S-LoRA的架构还允许它扩展到更多的适配器和更大的模型,而不受单一GPU内存容量的限制。
评估
S-LoRA的性能评估是通过一系列实验来完成的,这些实验旨在模拟合成和真实生产工作负载下的性能表现。在这些评估中,S-LoRA展示了其在单个GPU或多GPU环境下服务大量LoRA适配器的能力,并且具有很低的额外开销。
- 实验设置:
- 模型和硬件:评估使用了Llama模型系列,这是流行的大语言模型之一。实验在不同的硬件配置上进行,包括单个NVIDIA A10G GPU、A100 GPU,以及多A100 GPU的设置。
- 基线系统:S-LoRA与现有的参数高效微调库HuggingFace PEFT和高吞吐量服务系统vLLM进行了比较。这些系统代表了当前技术水平,它们在某些方面有各自的优化,但在处理大量LoRA适配器时存在限制。
2.评估指标:
- 吞吐量:系统每秒可以处理的请求数量。
- 平均请求延迟:处理每个请求所需的平均时间。
- 平均首令牌延迟:模型生成其首个输出令牌所需的平均时间。
- SLO(服务水平目标)达成率:在特定时间内完成请求的百分比。
3.实验结果:
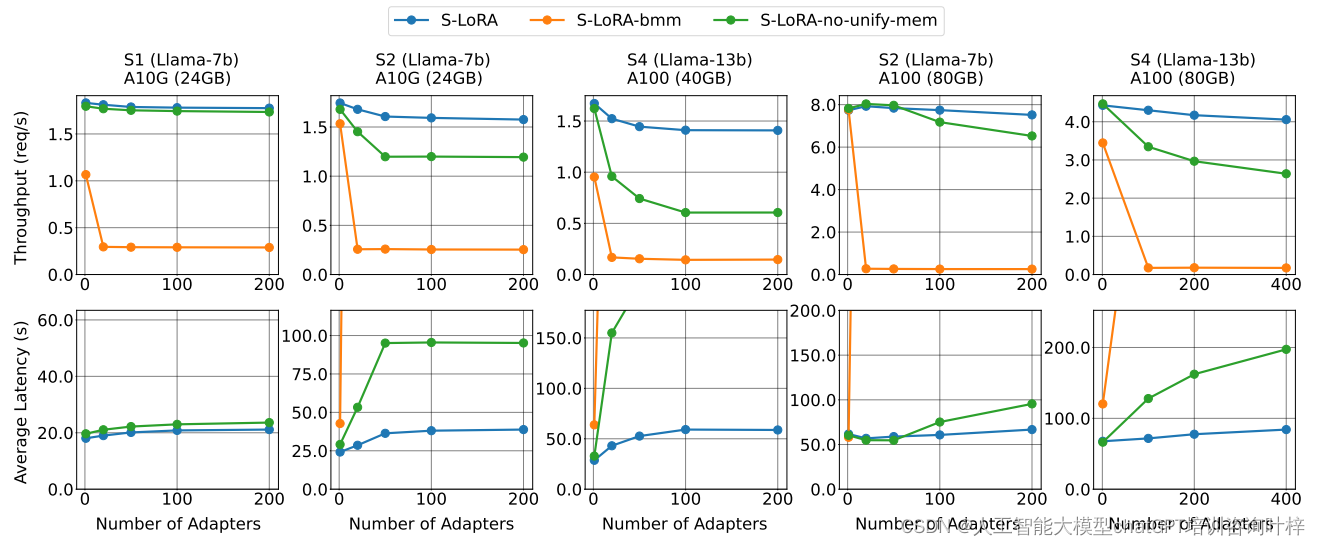
- S-LoRA在合成工作负载上的表现非常出色,能够以极小的开销服务多达2000个LoRA适配器。相比之下,vLLM-packed由于GPU内存限制,只能服务少于5个适配器,并且由于错过了批处理机会,其吞吐量也显著低于S-LoRA。
- 在与PEFT的比较中,尽管PEFT可以通过批次之间交换适配器权重来处理大量适配器,但由于缺乏高级批处理方法和内存管理,其性能显著较差。S-LoRA的吞吐量比PEFT高出30倍。
- 当与vLLM进行比较时,S-LoRA在服务少量适配器时的吞吐量提高了4倍,并且能够支持显著更多的适配器。
4.多GPU张量并行性:
- S-LoRA还对多GPU张量并行性进行了测试,包括在不同数量的GPU上运行大型模型,如Llama-30B和Llama-70B,并调整适配器的数量。
- 实验结果显示,S-LoRA在多GPU设置中表现出良好的扩展性,当从2个GPU增加到4个GPU时,服务吞吐量超过了两倍的增长。这表明,随着GPU数量的增加,系统能够有效地缓解内存限制,实现超线性的扩展。

S-LoRA的性能评估结果证明了其在服务大规模LoRA适配器方面的优势。与现有的技术相比,S-LoRA不仅在吞吐量上有显著提升,而且在内存管理和批处理策略上也更加高效。这些评估结果强调了S-LoRA在实际部署中的潜力,特别是在需要定制化微调和高吞吐量服务的场景中。
原论文链接:
https://arxiv.org/pdf/2311.03285.pdf
代码链接:
https://github.com/S-LoRA/S-LoRA
















 1484
1484











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









