







人工智能咨询培训老师叶梓 转载标明出处
在自然语言处理(NLP)的诸多任务中,标注数据的稀缺往往限制了模型性能的进一步提升。随着大型语言模型(LLMs)的兴起,研究者们现在面临一个关键问题:在有限的标注数据条件下,是应该依赖于通用的大型模型,还是应该通过微调来定制更为专业的小型模型?大型模型虽然具备广泛的适用性,能够在多种任务上展现出不错的性能,但专业模型通过针对性的微调,有可能在特定任务上实现更优的性能表现。本文旨在解决的问题是:专业模型在何种程度上需要标注样本以实现超越通用模型的优越性能,并考虑结果的变异性。通过深入分析,我们发现专业模型通常只需要少量样本(100-1000)就能与通用模型相媲美或更优,但这一需求数量强烈依赖于任务的复杂性和结果的变异性。
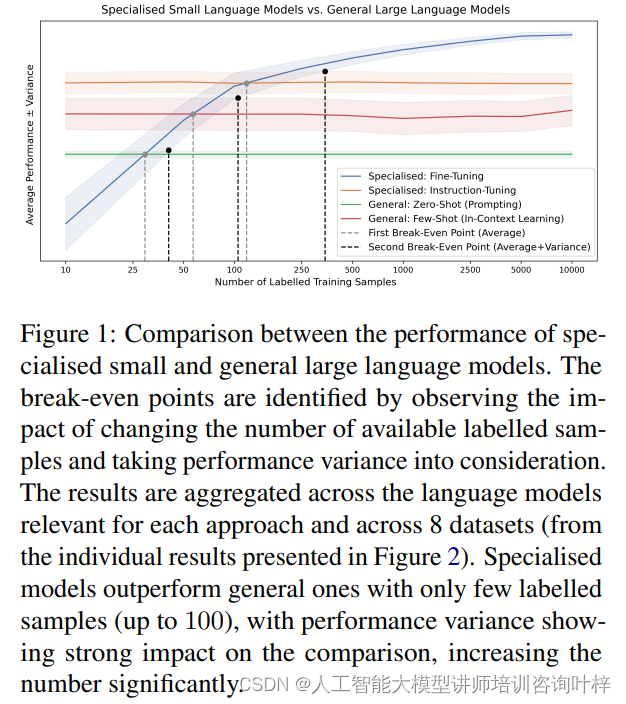
图1提供了特定领域小型语言模型与通用大型语言模型性能的对比视图。通过观察改变可用标记样本数量的影响,并考虑性能变化,确定了两种模型间的平衡点。这些结果是在考虑每种方法相关的语言模型以及8个数据集(来自图2中呈现的单独结果)的综合基础上得出的。特定领域模型仅用少量标记样本(多达100个),就能超越通用模型,性能变化对比较有显著影响,显著增加了所需的样本数量。
图1的分析揭示了小型特定领域模型在少量数据上的优势,这些模型能够快速适应特定任务,并在只有少量标记样本的情况下实现高性能。然而,这种性能的比较受到结果变化性的影响很大,当结果变化性较高时,可能需要更多的标记样本来确保特定领域模型的稳定性和可靠性。
这种观察结果强调了在选择模型时考虑任务特性和可用数据的重要性。如果任务允许并且只有少量的标记数据可用,小型特定领域模型可能是一个有效的选择。但如果有足够的数据并且对模型性能的稳定性有更高的要求,可能需要更多的标记样本来实现这一点,或者考虑使用通用大型语言模型,这些模型可能在广泛的任务上提供稳定的表现。
通过图1我们看到即使在数据量较少的情况下,特定领域模型也能展现出与大型通用模型相当的性能,这为资源有限的实际应用提供了有价值的见解。但这也提示了在实际应用中需要仔细考虑数据的质量和数量,以及模型训练过程中的随机性,以确保模型能够在实际部署中达到预期的性能。
研究结果表明,尽管大型语言模型在多种任务上具有较好的通用性,但在许多具体的NLP任务上,它们仍难以超越那些拥有足够标注数据的专业小型模型。这一发现强调了在特定任务上进行模型微调的重要性,尤其是在考虑到标注成本和任务性能的双重因素时。通过对这些方法的深入比较和分析,本文为研究者在有限标注数据条件下选择合适的模型和方法提供了指导。
总的来说,特定领域模型与通用模型的比较揭示了一个关键的权衡点:在有限的数据条件下,特定领域模型通过更精准地适应任务需求,能够在较少样本的情况下实现与通用模型相媲美甚至更优的性能。这一发现对于指导未来的模型选择、数据集构建和资源分配具有重要的启示作用。
在评估模型性能时,结果的变化性是一个不可忽视的因素,尤其在数据集规模较小的情况下,它对性能比较的影响尤为显著。这种变化性或变异度通常由多个因素引起,包括数据集中样本的多样性、模型训练过程中的随机性,以及模型对特定数据的敏感度等。
当数据集规模较小时,样本的多样性不足可能导致模型训练结果的高变化性。如果数据集中的样本不能全面代表目标任务的所有情况,那么模型在这些有限样本上训练得到的性能可能无法准确反映其在更大数据集上的真实性能。例如,如果一个数据集在某些类别上样本数量偏少,模型可能无法学习到这些类别的特征,导致在这些类别上的预测性能不稳定。
模型训练过程中的随机性也会导致结果的变化。大多数机器学习算法在训练过程中都涉及到一定程度的随机性,如随机初始化权重、随机数据增强或随机样本抽样等。这些随机因素可能会导致不同次训练的结果存在差异,特别是在数据量不足时,这种差异可能更加明显。
模型对特定数据的敏感度也会影响结果的稳定性。一些模型可能对训练数据中的某些特征过于敏感,导致在这些特征出现变化时模型性能波动较大。在小规模数据集上,这种敏感性可能会被放大,因为模型没有足够多的数据来学习到更鲁棒的特征表示。
针对这些情况,研究中采取了一些措施来评估和减少结果变化对性能比较的影响。例如,通过多次重复实验并报告平均性能和标准差,可以更全面地了解模型在不同运行中的表现。此外,通过使用交叉验证等技术,可以在有限的数据上更准确地估计模型的性能。
在比较不同模型的性能时必须认真考虑结果的变化性。如果两种模型的性能在多次实验中变化趋势相似,那么可以更有信心地得出它们性能相对优劣的结论。相反,如果结果变化性很大,那么就需要更多的数据或更稳健的实验设计来确保性能比较的可靠性。
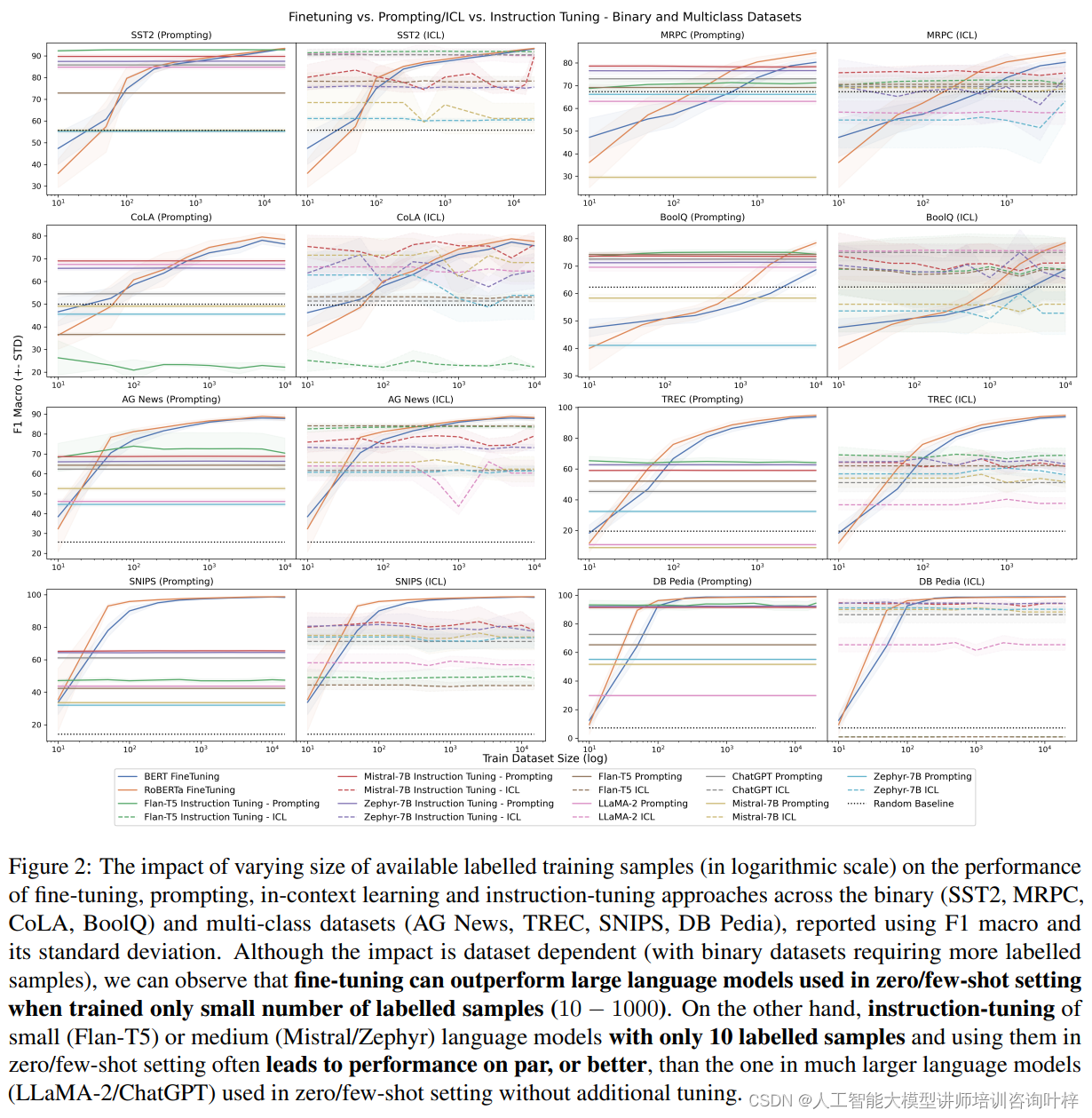
图2在论文中展示了不同规模的可用标记训练样本(以对数刻度表示)对微调、提示、上下文学习和指令调整方法在二元分类(SST2、MRPC、CoLA、BoolQ)和多类分类数据集(AG News、TREC、SNIPS、DB Pedia)上性能的影响。性能以F1宏观平均值及其标准差来报告。尽管影响因数据集而异(二元分类数据集需要更多的标记样本),可以观察到即使只使用少量标记样本(10-1000个),微调也可以在零样本/少样本设置中超越大型语言模型的性能。即使是只使用10个标记样本的小型(Flan-T5)或中型(Mistral/Zephyr)语言模型,在零样本/少样本设置中的指令调整通常也能带来与大型语言模型(LLaMA-2/ChatGPT)相当或更好的性能,而这些大型模型在没有额外调整的情况下使用零样本/少样本设置。
图2的发现强调了即使是较小的语言模型,通过适当的指令调整,也能在很少的标记数据上实现与大型模型相媲美的性能。这为资源有限或特定任务提供了重要的见解,表明不需要大量的标记数据或大型模型就能达到有效的性能。这也表明在某些情况下,通过精心设计的指令和少量样本的调整,可以有效地利用小型或中型模型来处理复杂的分类任务。
结果变化对模型性能比较的影响在小规模数据集上尤为显著,需要通过细致的实验设计和统计分析来准确评估模型性能。理解并量化这种变化性对于确保研究结果的准确性和可靠性至关重要。
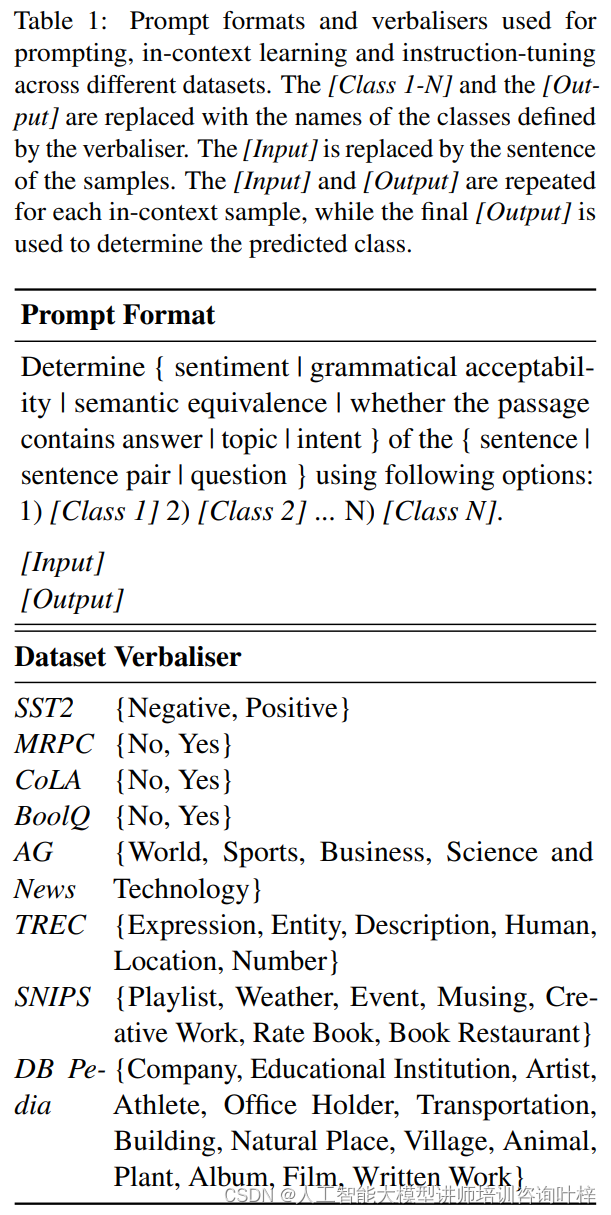
数据集规模对模型性能有着直接的影响。小型数据集可能无法充分展现模型的潜力,特别是对于复杂模型而言,它们需要大量数据来学习任务的细微差别。然而,随着数据集规模的增加,模型能够学习到更多的特征和模式,从而提高性能。但这种提升并非无限制,当数据集规模达到一定程度后,性能增益将逐渐减少。
模型复杂性也是一个关键因素。复杂模型拥有更多的参数,理论上能够捕捉更细致的数据特征,但这同样也带来了更高的过拟合风险,特别是在数据量不足的情况下。相对而言,简单模型虽然参数较少,泛化能力可能更强,但在处理复杂任务时可能力不从心。
结果变化性或性能波动对模型选择和评估至关重要。研究中发现,即使是在数据量较小的情况下,特定领域模型也可能展现出与通用模型相媲美的性能,但这种性能往往伴随着较大的变化性。这意味着在实际应用中,我们不仅要考虑模型的平均性能,还要考虑其稳定性和可靠性。
综合这些因素,建议在选择模型时,应考虑任务的复杂性、可用数据的规模以及对性能稳定性的需求。对于数据量较小的任务,可能更倾向于选择简单模型或通过指令调整来优化小型模型。而对于数据量充足且任务较为复杂的场景,选择复杂模型并通过微调来进一步提升性能可能更为合适。
数据集构建时应注重样本的多样性和代表性,以确保模型能够学习到全面的特征。同时,合理的数据增强和清洗工作也是提高数据集质量、减少结果变化性的有效手段。
持续监测和评估模型性能非常重要,通过跟踪模型在不同数据集上的表现,可以及时发现并解决性能波动的问题,确保模型在实际部署中的稳定性和可靠性。
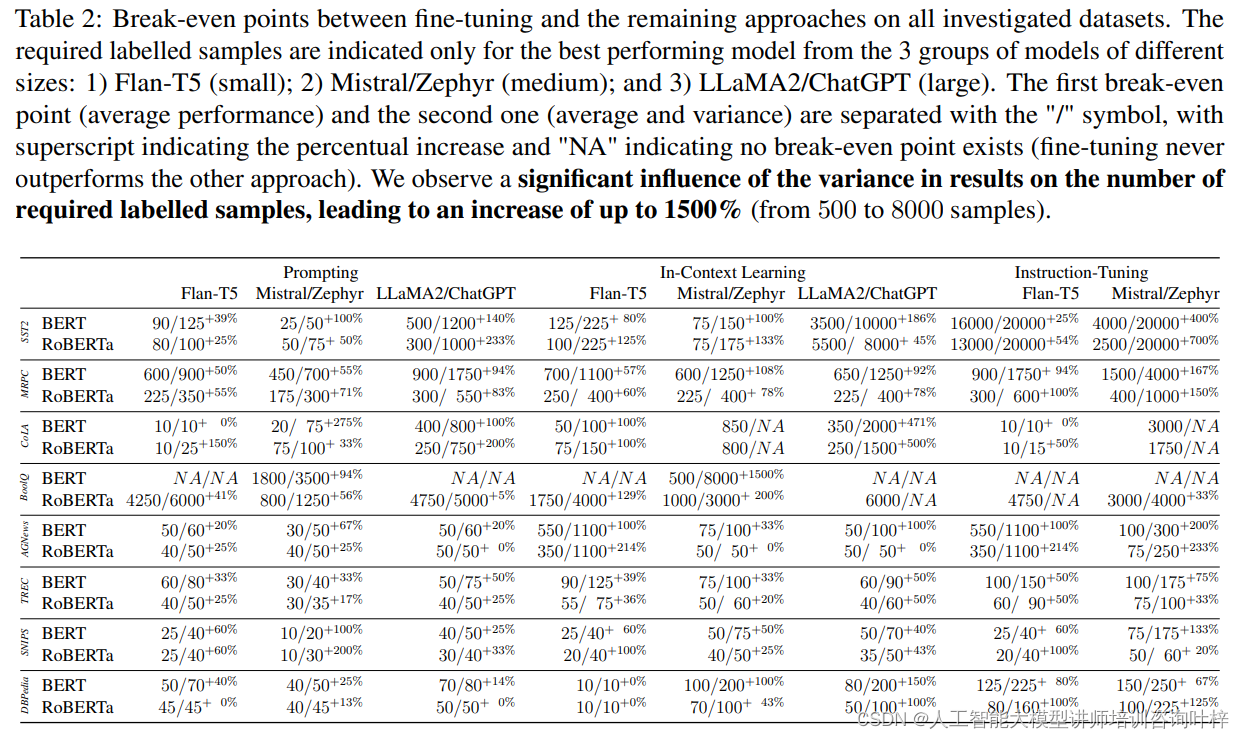
总结建议:
在进行模型选择和数据集构建时,需要综合考虑数据集的规模、模型的复杂性以及结果变化的特点。对于资源有限或快速原型设计的场景,通用模型是一个不错的选择。它们不需要大量的标记数据,就能在多种任务上展现出不错的性能。如果任务对性能有更高的要求,或者数据集具有特定的特性,那么投资于特定领域模型的开发将是一个更明智的决策。这些模型虽然需要更多的标注工作,但它们能够更精准地适应任务需求,从而在性能上超越通用模型。
数据集规模的选择应基于任务的复杂性和可用资源。在任务较为简单或者数据集较小的情况下,即使是较小的特定领域模型也可能无法充分发挥其潜力。此时,可以通过指令调整等技术来优化模型,以实现更好的性能。相反,在数据集规模较大或者任务较为复杂时,微调较大的特定领域模型可能会带来更显著的性能提升。
结果变化的考量也不容忽视。在选择模型和评估性能时,应充分考虑结果的稳定性。通过多次实验和交叉验证,可以更准确地评估模型的性能,并减少过拟合或随机波动带来的影响。
在数据集构建方面,建议采取多元化和代表性强的样本选择策略。这有助于提高模型的泛化能力,并减少对特定数据特征的过度依赖。同时,合理的数据增强和清洗工作也能够提高数据集的质量,从而提升模型的性能。
在模型开发过程中持续监测和评估模型的性能变化。这不仅包括对模型准确性的评估,还应包括对模型稳定性和鲁棒性的考量。通过这种方式,可以及时发现并解决模型在训练或应用过程中可能出现的问题。
选择合适模型和调整数据集规模的决策应基于对任务需求、数据特性和资源可用性的综合考量。通过精心设计实验和持续评估模型性能,可以确保在特定任务上实现最优的模型性能。本研究的局限性在于它主要关注了二元分类任务,并且使用的模型数量有限,对普遍适用性有一定限制。尽管如此,通过精心设计的实验和持续的性能监测,可以为自然语言处理领域的研究者和实践者提供有价值的见解。















 898
898

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









