







视觉-语言模型(VLMs)在理解和生成涉及视觉与文本的任务上取得了显著进展,它们在理解和生成结合视觉与文本信息的任务中扮演着重要角色。然而,这些模型的性能往往受限于其视觉编码器的能力。例如,现有的一些模型可能对某些图像特征视而不见,或者在处理图像时产生视觉幻觉,这些局限严重制约了VLMs在复杂场景中的应用。
BRAVE方法正是为了解决这些问题而诞生的。它通过结合多个具有不同视觉偏好的视觉编码器,拓宽了模型对视觉信息的编码能力。与传统的单一编码器方法相比,BRAVE能够捕获更加丰富和多样化的视觉特征,从而显著提升了模型在图像描述和视觉问答等任务上的性能。BRAVE通过使用参数高效的微调技术,减少了模型训练时所需的参数数量,同时保持了紧凑的模型表示,这不仅提高了模型的效率,也增强了模型对不同类型输入的泛化能力。通过这种方式,BRAVE为构建更加健壮和高效的视觉-语言模型提供了新的可能性。
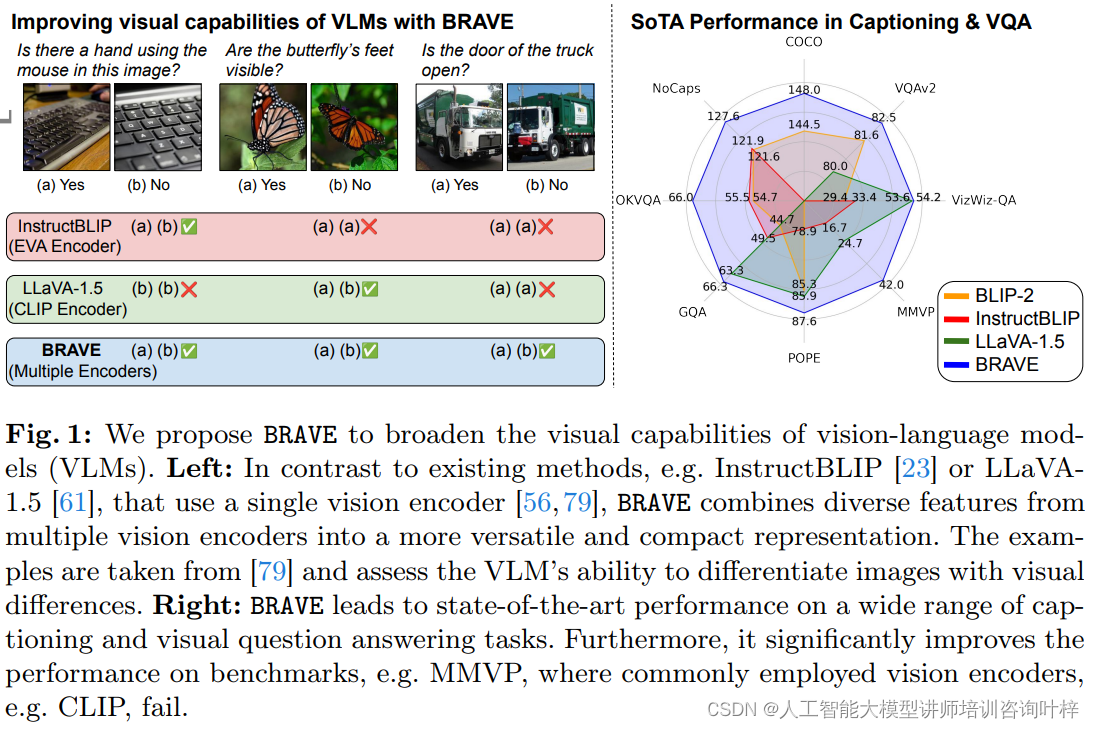
不同视觉编码器对视觉-语言任务性能的影响
先来看看视觉-语言模型(VLM)的基本架构。在VLM中,一个冻结的视觉编码器与一个冻结的语言模型通过一个带有可训练参数的桥接网络连接。这个桥接网络通常采用特定的模块(例如Q-Former),它能够将视觉特征重新采样到固定长度的输出,然后将其输入到语言模型中。
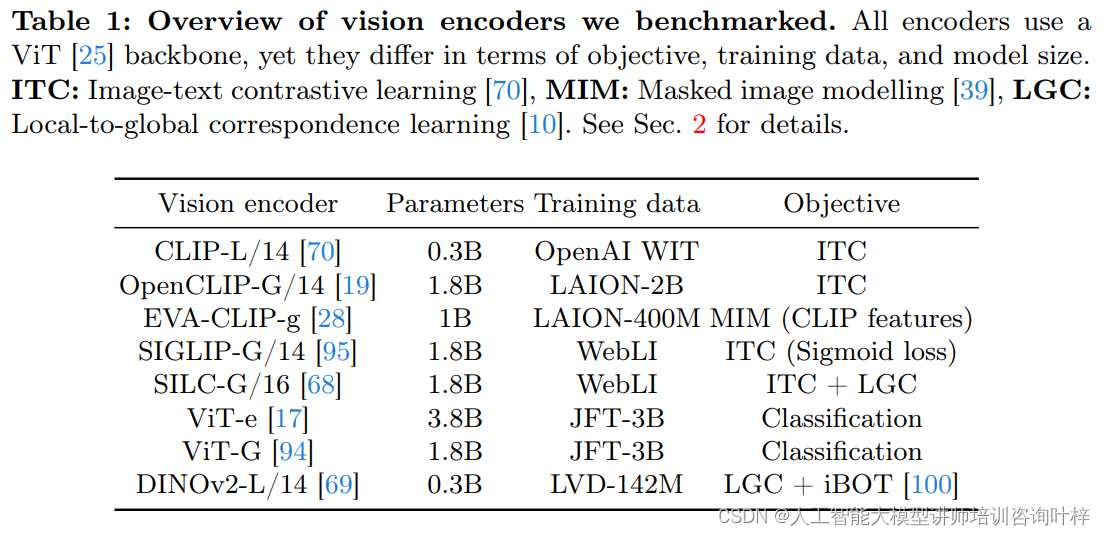
具有不同偏好的视觉编码器,例如CLIP、OpenCLIP、EVA-CLIP等。这些编码器虽然都使用基于Vision Transformer(ViT)的骨干网络,但在训练数据、训练目标和模型大小方面存在差异。这些差异导致每个编码器具有不同的视觉偏好,可能捕获场景的不同方面。
对于预训练数据和目标对VLM性能的影响研究者们使用WebLI数据集对Q-Former进行预训练,并使用WebLI中的alt-text作为目标进行训练。在标准的图像描述和VQA任务上评估了得到的VLMs。他们使用了COCO图像描述基准,并在Karpathy训练集上进行了微调。对于VQA任务,他们遵循标准实践,并在VQAv2和OKVQA的数据集上进行了微调。
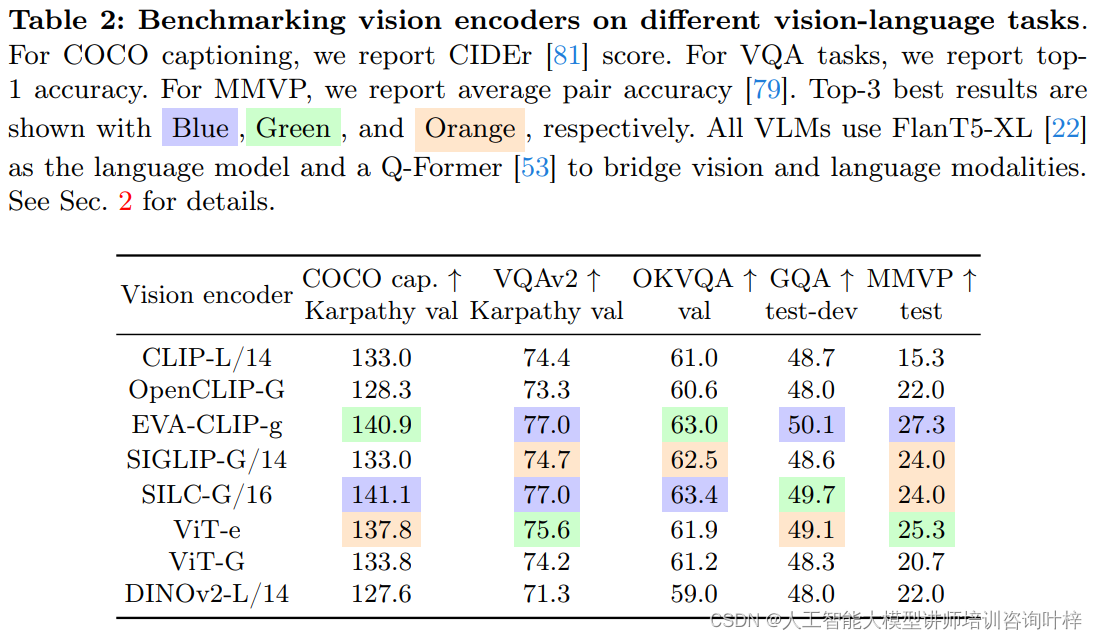
在不同视觉编码器下的VLMs性能如下:
- 不同编码器的偏好可以导致相似的性能水平,表明没有单一编码器在所有任务中始终保持最佳性能。
- 在MMVP基准测试中,大多数编码器的性能都低于随机猜测的准确率,表明这对所有编码器来说仍然是一个挑战。
- 在需要组合推理和开放世界知识的任务上,VLMs的性能有所下降,性能差距也随之缩小。
- 通过增加视觉编码器的大小可以提高性能,这在ViT-e的性能提升中得到了体现。
- 预训练数据的分布对VLM性能有重要影响,例如OpenCLIP-G/14模型虽然比CLIP-L/14模型大,但在大多数评估的VQA和图像描述任务中表现不佳,这表明训练目标和数据集对VLM性能都有重要影响。
如何通过BRAVE方法有效地结合多个视觉编码器,以增强视觉-语言模型(VLMs)的性能和鲁棒性
尽管现有的VLMs在多种视觉-语言任务上取得了进展,但它们仍然受限于单一视觉编码器的能力。为了解决这个问题,BRAVE提出了一种新颖的方法,通过结合多个具有不同视觉偏好的视觉编码器,来拓宽模型的视觉编码能力。这种方法的动机是,不同的编码器可以捕获图像的不同方面,通过整合这些编码器,模型能够获得更全面的图像理解。
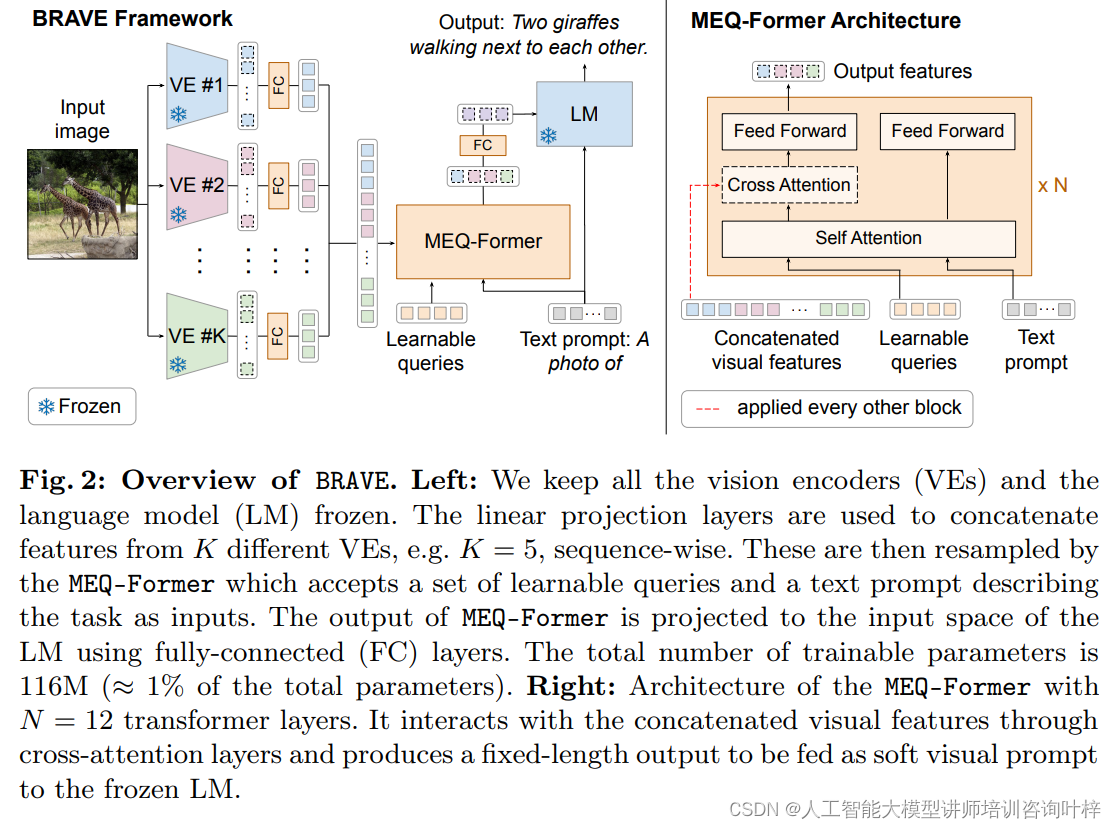
在BRAVE架构中,图2展示了一个创新的系统设计,旨在通过结合多个视觉编码器(VEs)和语言模型(LM)来增强视觉-语言模型的能力。在左侧的描述中,我们看到所有的视觉编码器和语言模型在预训练后都被冻结,即它们的参数不再更新。这是为了保持模型的稳定性,并减少进一步训练所需的计算资源。通过使用线性投影层,系统能够将来自K个不同VEs的特征序列化并串联起来,例如K=5,系统同时考虑五个编码器的输出。
紧接着,MEQ-Former(多编码器查询变换器)发挥了关键作用。它接受一组可学习的查询和描述任务的文本提示作为输入,并通过交叉注意力机制对串联的特征进行有效重采样,生成固定长度的输出。这一步骤至关重要,因为它能够整合多样化的视觉信息,并将其转化为对语言模型有用的形式。
在右侧的描述中,MEQ-Former的详细架构被展示出来,它包含N=12个变换器层。这些层与串联的视觉特征进行交云注意力交互,产生一个固定长度的输出,这个输出随后被用作软视觉提示,输入到冻结的语言模型中。这种设计不仅提高了模型处理视觉信息的能力,而且还保持了参数的高效性,因为BRAVE的可训练参数总数仅为116M,大约是模型总参数量的1%。
BRAVE的核心是多编码器查询变换器(MEQ-Former),这是一个轻量级的变换器模块,它能够接受来自不同视觉编码器的特征,并将其整合成一个固定长度的视觉表示。MEQ-Former通过交叉注意力机制与输入的文本提示以及可学习的查询向量相互作用,有效地重采样和整合视觉特征。
在预训练阶段,研究者们只训练MEQ-Former的参数,而保持所有视觉编码器和语言模型冻结。这种策略显著减少了预训练所需的可训练参数数量。在微调阶段,MEQ-Former可以根据下游任务的需要进行微调,以进一步提高模型的性能。BRAVE不仅可以应用于现有的视觉编码器,还可以轻松地整合新的编码器,以适应不断变化的视觉-语言任务需求。BRAVE的设计允许它在未来的研究中进一步扩展,例如结合更多模态的信息或处理多帧输入。
实验
研究者们使用了包括COCO图像描述和多个VQA数据集在内的标准基准测试,以及针对视觉幻觉和长尾视觉概念的鲁棒性测试。

在性能评估部分,研究者们展示了BRAVE在图像描述和VQA任务上的结果。他们将BRAVE与其他最先进的方法进行了比较,包括单一视觉编码器的方法和一些集成方法。结果表明,BRAVE在多个任务上都取得了显著的性能提升,证明了其在视觉-语言任务上的优越性。

为了测试BRAVE的鲁棒性,研究者们在POPE和MMVP等具有挑战性的数据集上进行了评估。这些数据集旨在测试模型对于视觉幻觉和难以区分的图像对的处理能力。BRAVE在这些测试中表现出了良好的鲁棒性,即使在面对困难的样本时也能保持较高的准确率。
在消融研究中,研究者们通过一系列的实验来分析不同组件对BRAVE性能的贡献。他们探讨了不同视觉编码器的组合、MEQ-Former的不同变体、以及预训练数据集大小对模型性能的影响。这些实验结果帮助研究者们理解了BRAVE的关键优势,并为进一步优化提供了方向。
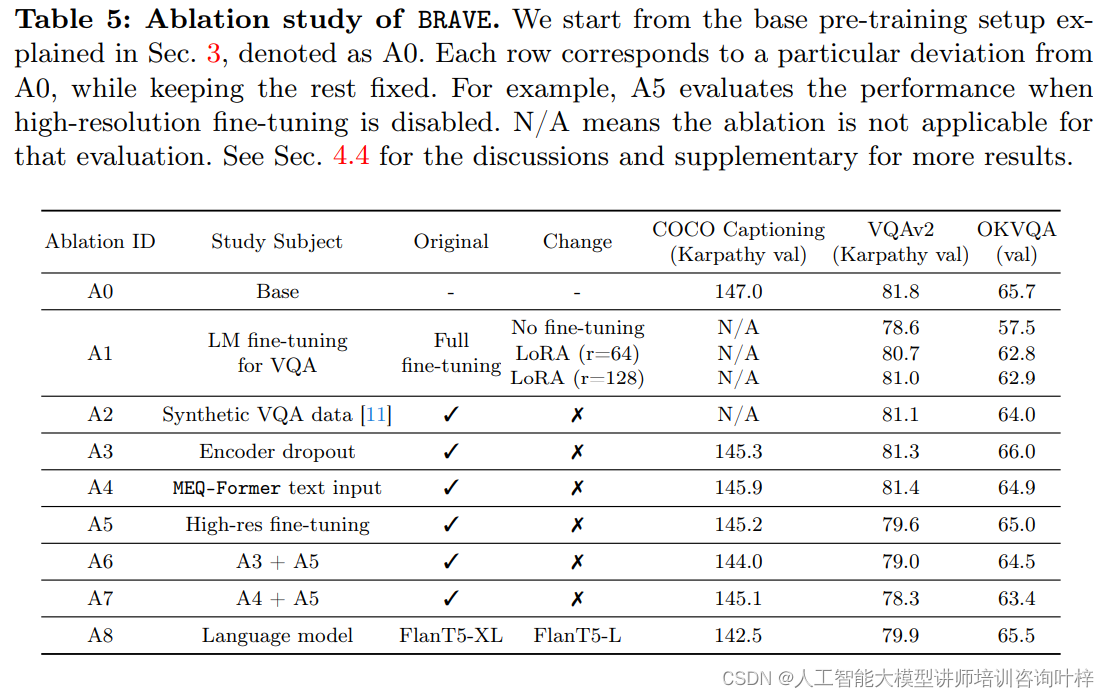
基于BRAVE的实验结果,讨论其在视觉-语言任务中的潜力和应用前景,同时提出未来可能的研究方向,如自适应机制、提高样本效率、扩展视觉编码器的种类等。
通过一系列实验和性能评估,验证了BRAVE在参数效率和模型扩展性方面的优势。BRAVE不仅在COCO图像描述和多个VQA数据集上取得了优于现有最先进方法的结果,还在面对视觉幻觉和长尾视觉概念时展现出了卓越的鲁棒性。
BRAVE的提出,为视觉-语言模型的研究和应用开辟了新的可能性。它不仅提高了模型的性能,还通过减少训练参数和提高泛化能力,为解决实际问题提供了更为实用的工具。随着人工智能技术的不断进步,期待BRAVE能够在更广泛的领域中发挥作用,推动视觉-语言研究的进一步发展。
论文链接:https://arxiv.org/abs/2404.07204
项目地址:https://brave-vlms.epfl.ch/















 268
268

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









