






前言:
这是增量块汇报的第二篇文章,第一篇文章介绍了IBR在DN侧的相关逻辑。本篇准备介绍IBR在NN侧的相关逻辑。
也是带着如下问题去阅读源码:
- NN侧如何处理IBR请求?
- 如果增量块汇报处理失败,那么NN和DN会有什么行为?
IBR在NN侧主要是通过NameNodeRpcServer中的blockReceivedAndDeleted处理。
@Override // DatanodeProtocol
public void blockReceivedAndDeleted(final DatanodeRegistration nodeReg,
String poolId, StorageReceivedDeletedBlocks[] receivedAndDeletedBlocks)
throws IOException {
checkNNStartup();
verifyRequest(nodeReg);
metrics.incrBlockReceivedAndDeletedOps();
if(blockStateChangeLog.isDebugEnabled()) {
blockStateChangeLog.debug("*BLOCK* NameNode.blockReceivedAndDeleted: "
+"from "+nodeReg+" "+receivedAndDeletedBlocks.length
+" blocks.");
}
final BlockManager bm = namesystem.getBlockManager();
for (final StorageReceivedDeletedBlocks r : receivedAndDeletedBlocks) {
bm.enqueueBlockOp(new Runnable() {
@Override
public void run() {
try {
namesystem.processIncrementalBlockReport(nodeReg, r);
} catch (Exception ex) {
// usually because the node is unregistered/dead. next heartbeat
// will correct the problem
blockStateChangeLog.error(
"*BLOCK* NameNode.blockReceivedAndDeleted: "
+ "failed from " + nodeReg + ": " + ex.getMessage());
}
}
});
}
}NN接收到IBR rpc后,会针对汇报上来的每个StorageReceivedDeletedBlocks进行处理。这里我们分两路进行分析。
- enqueueBlockOp
- new Runnable{}里面的run方法。
首先看第一路:enqueueBlockOp。
主要逻辑就是把处理IBR的逻辑封装成Runnable对象然后入队:
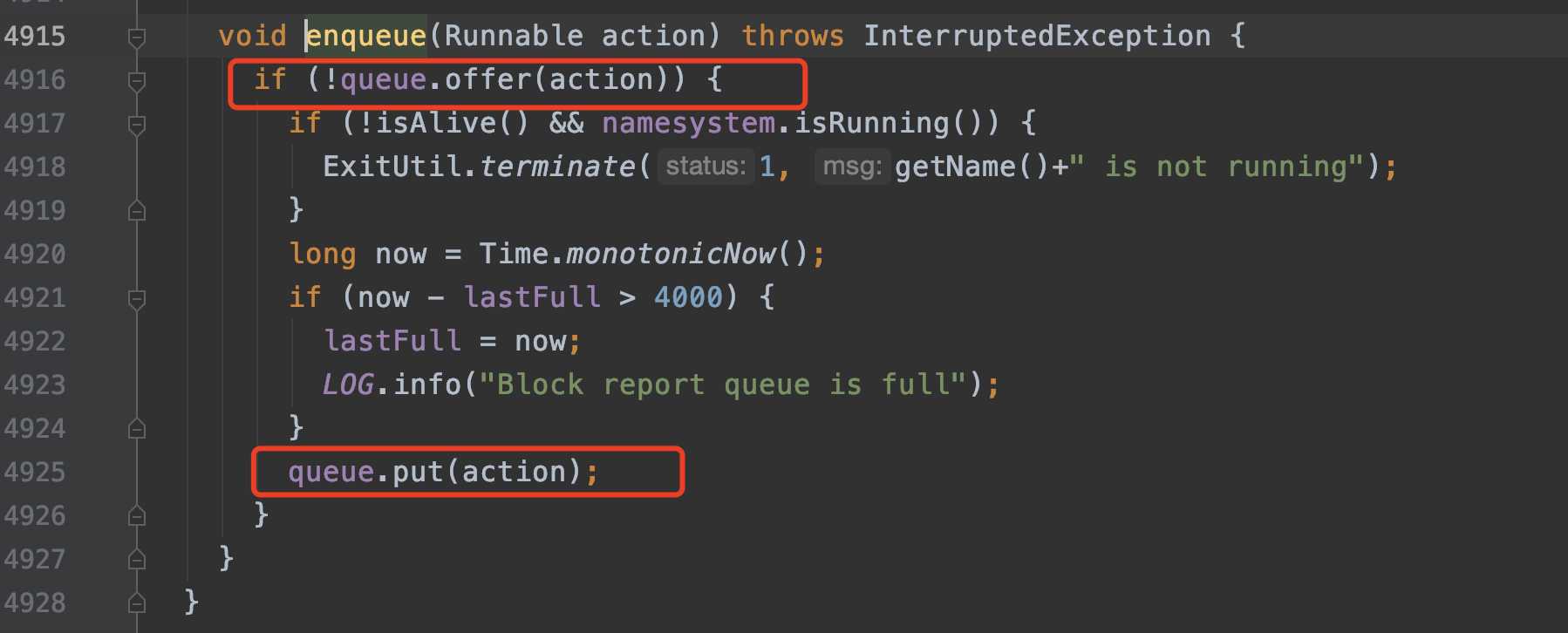
这个queue定义在BlockReportProcessingThread:

那既然有入队操作,一定会有take操作或者poll操作。经过查找,发现是在org.apache.hadoop.hdfs.server.blockmanagement.BlockManager.BlockReportProcessingThread#processQueue方法中。代码如下:
private void processQueue() {
while (namesystem.isRunning()) {
NameNodeMetrics metrics = NameNode.getNameNodeMetrics();
try {
Runnable action = queue.take();
// batch as many operations in the write lock until the queue
// runs dry, or the max lock hold is reached.
int processed = 0;
namesystem.writeLock();
metrics.setBlockOpsQueued(queue.size() + 1);
try {
long start = Time.monotonicNow();
do {
processed++;
action.run();
if (Time.monotonicNow() - start > MAX_LOCK_HOLD_MS) {
break;
}
action = queue.poll();
} while (action != null);
} finally {
namesystem.writeUnlock("blockReportProcessQueue");
metrics.addBlockOpsBatched(processed - 1);
}
} catch (InterruptedException e) {
// ignore unless thread was specifically interrupted.
if (Thread.interrupted()) {
break;
}
}
}
queue.clear();
}此方法主要是从queue中取出Runnable对象,然后执行run方法,也就是我们一会儿要看的第二条路。
processQueue这个方法是在BlockReportProcessingThread线程的run方法中调用的。在Namenode启动时会start这个线程。
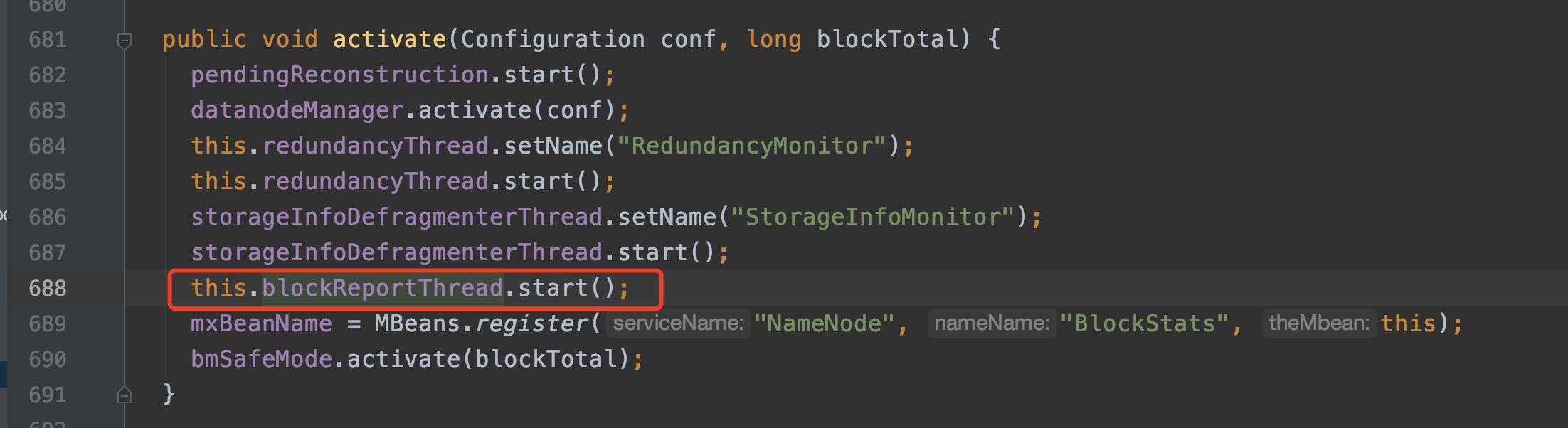
接下来看第二条路:Runnable的run方法的逻辑。
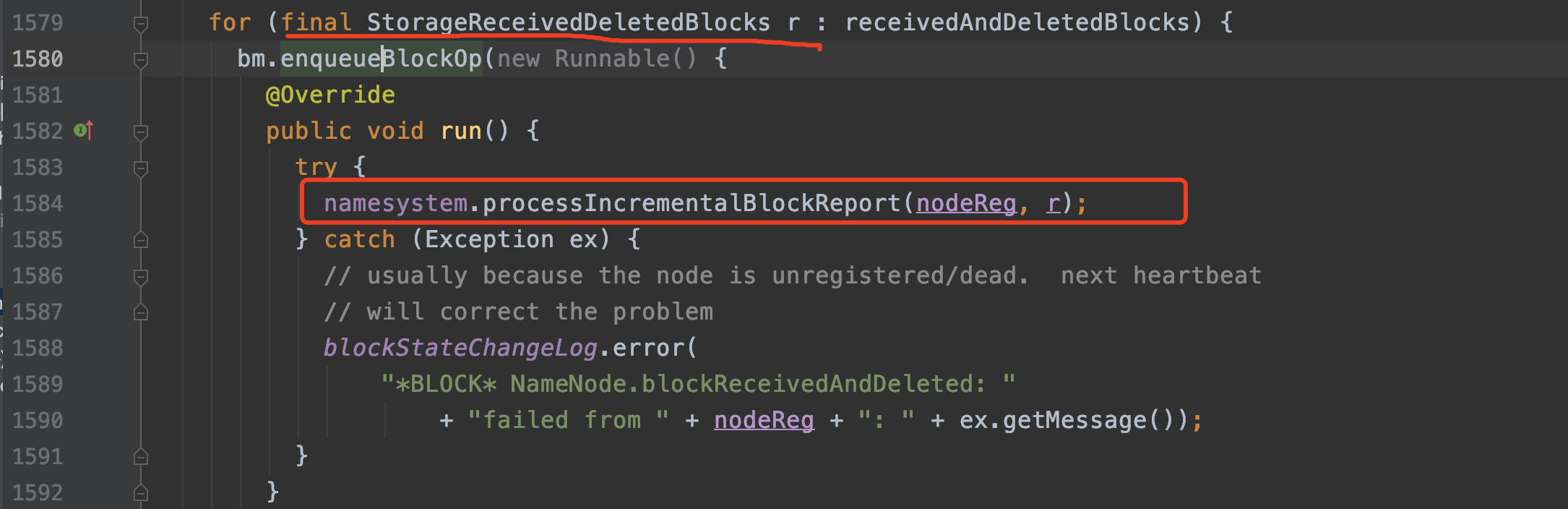
run方法里调用了org.apache.hadoop.hdfs.server.namenode.FSNamesystem#processIncrementalBlockReport方法。
一步一步往下调用,最后会调用到BlockManager#processIncrementalBlockReport方法。
此方法会根据发送过来的增量块汇报的块状态(例如DELETED_BLOCK、RECEIVED_BLOCK等)进行相应的处理逻辑,主要是更新NN侧有关数据块与DN映射的map,以及更改数据块复制队列、删除队列。这里以DELETED_BLOCK为例进行分析。
private void processIncrementalBlockReport(final DatanodeDescriptor node,
final StorageReceivedDeletedBlocks srdb) throws IOException {
DatanodeStorageInfo storageInfo =
node.getStorageInfo(srdb.getStorage().getStorageID());
if (storageInfo == null) {
// The DataNode is reporting an unknown storage. Usually the NN learns
// about new storages from heartbeats but during NN restart we may
// receive a block report or incremental report before the heartbeat.
// We must handle this for protocol compatibility. This issue was
// uncovered by HDFS-6094.
storageInfo = node.updateStorage(srdb.getStorage());
}
int received = 0;
int deleted = 0;
int receiving = 0;
for (ReceivedDeletedBlockInfo rdbi : srdb.getBlocks()) {
switch (rdbi.getStatus()) {
case DELETED_BLOCK:
removeStoredBlock(storageInfo, rdbi.getBlock(), node);
deleted++;
break;
case RECEIVED_BLOCK:
addBlock(storageInfo, rdbi.getBlock(), rdbi.getDelHints());
received++;
break;
case RECEIVING_BLOCK:
receiving++;
processAndHandleReportedBlock(storageInfo, rdbi.getBlock(),
ReplicaState.RBW, null);
break;
default:
String msg =
"Unknown block status code reported by " + node +
": " + rdbi;
blockLog.warn(msg);
assert false : msg; // if assertions are enabled, throw.
break;
}
blockLog.debug("BLOCK* block {}: {} is received from {}",
rdbi.getStatus(), rdbi.getBlock(), node);
}
blockLog.debug("*BLOCK* NameNode.processIncrementalBlockReport: from "
+ "{} receiving: {}, received: {}, deleted: {}", node, receiving,
received, deleted);
}进到case DELETED_BLOCK分支,不考虑EC的话,最终会调用org.apache.hadoop.hdfs.server.blockmanagement.BlockManager#removeStoredBlock方法。看一下这个方法的逻辑:
/**
* Modify (block-->datanode) map. Possibly generate replication tasks, if the
* removed block is still valid.
*/
public void removeStoredBlock(BlockInfo storedBlock, DatanodeDescriptor node) {
blockLog.debug("BLOCK* removeStoredBlock: {} from {}", storedBlock, node);
assert (namesystem.hasWriteLock());
{
// 从blocksMap中移除块->元数据,块->datanode映射的信息。
if (storedBlock == null || !blocksMap.removeNode(storedBlock, node)) {
blockLog.debug("BLOCK* removeStoredBlock: {} has already been" +
" removed from node {}", storedBlock, node);
return;
}
CachedBlock cblock = namesystem.getCacheManager().getCachedBlocks()
.get(new CachedBlock(storedBlock.getBlockId(), (short) 0, false));
if (cblock != null) {
boolean removed = false;
removed |= node.getPendingCached().remove(cblock);
removed |= node.getCached().remove(cblock);
removed |= node.getPendingUncached().remove(cblock);
if (removed) {
blockLog.debug("BLOCK* removeStoredBlock: {} removed from caching "
+ "related lists on node {}", storedBlock, node);
}
}
//
// It's possible that the block was removed because of a datanode
// failure. If the block is still valid, check if replication is
// necessary. In that case, put block on a possibly-will-
// be-replicated list.
//
if (!storedBlock.isDeleted()) {
bmSafeMode.decrementSafeBlockCount(storedBlock);
// 进入这个if的原因是datanode侧出现了错误,比如有块盘坏了,
// 那么就会向NN发送这块盘的块DELETED_BLOCK的IBR。
// 但是,我们这些块并不是我们要删除的,所以会加入到复制队列中等待补充副本。
updateNeededReconstructions(storedBlock, -1, 0);
}
// 从excessRedundancyMap这个map中删除对应的block
excessRedundancyMap.remove(node, storedBlock);
//从corruptReplicas这个map中删除对应的block
corruptReplicas.removeFromCorruptReplicasMap(storedBlock, node);
}
}通过上面的分析,我们能够回答第一个问题:NN侧是如何处理IBR的?
下面来分析第二个问题,如果IBR处理异常,那么NN和DN分别有什么行为呢?
首先看NN,NN侧的blockReceivedAndDeleted返回值是void的,也就意味着增量块汇报是不会给DN发送命令指令的,同时blockReceivedAndDeleted方法是可能会抛出IOException异常的。
接着看DN侧:
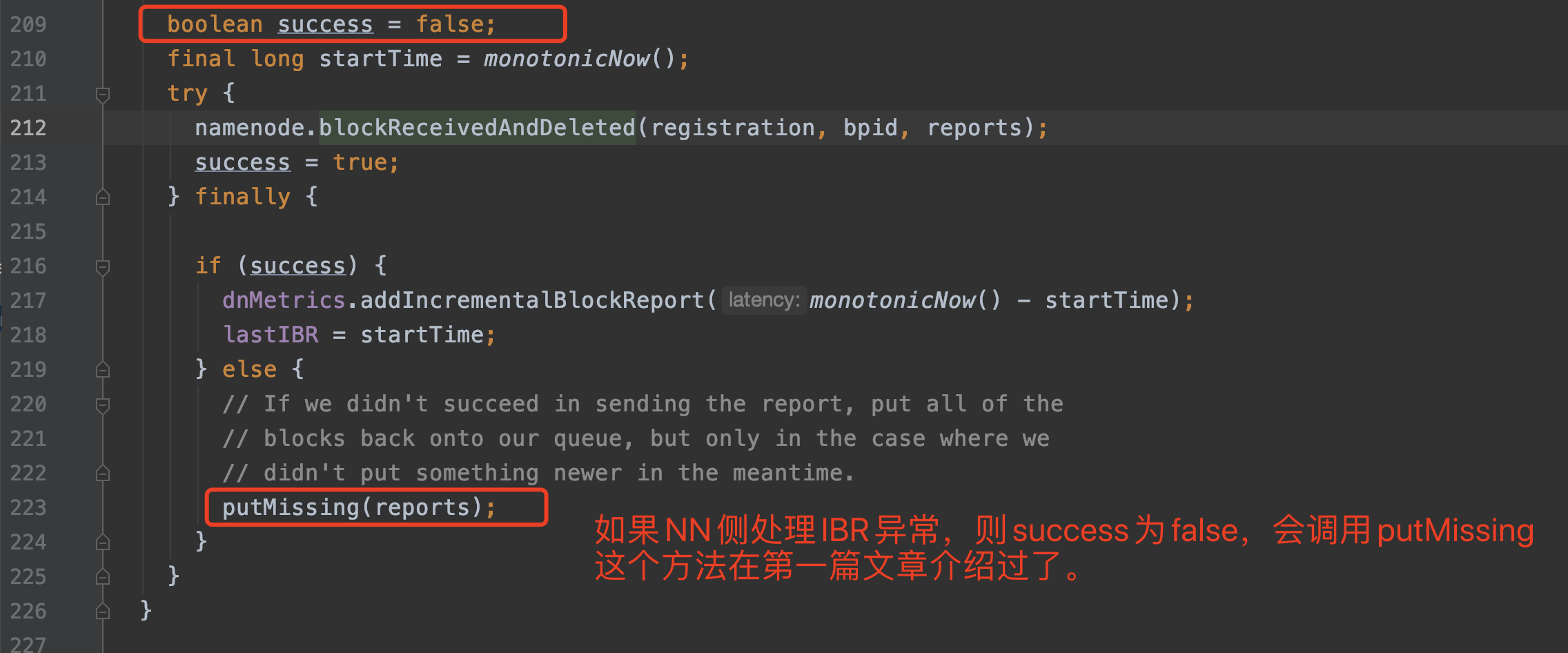
OK,本文结束。
















 2541
2541

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











