









zookeeper简介

ZooKeeper是一种分布式协调服务,用于管理大型主机。在分布式环境中协调和管理服务是一个复杂的过程。ZooKeeper通过其简单的架构和API解决了这个问题。 ZooKeeper允许开发人员专注于核心应用程序逻辑,而不必担心应用程序的分布式特性。
ZooKeeper框架最初是在“Yahoo!”上构建的,用于以简单而稳健的方式访问他们的应用程序。后来,Apache ZooKeeper成为Hadoop,HBase和其他分布式框架使用的有组织服务的标准。例如,Apache HBase使用ZooKeeper跟踪分布式数据的状态。

如上图所示,zookeeper就是registry[注册中心],每次我们写了某个功能,都要去注册中心注册,注册之后别人才能调用你写的功能,管理这些功能的就叫zookeeper!!举个例子,学校要通知一件事,难道要一个人一个人地通知吗???显然要先通知班主任,然后班主任那有个花名册,按照花名册去通知学生,那个花名册就可以理解为zookeeper!!是一个基于观察者模式设计的分布式服务管理框架,它负责存储和管理大家都关心的数据,
然后接受观察者的注册,一旦这些数据的状态发生变化,Zookeeper就将负责通知已经在Zookeeper上注册的那些观察者做出相应的反应,从而实现集群中类似Master/Slave管理模式。

安装配置
把windows中下好地zookeeper安装包传到linux的opt目录下。

然后如下图所示,解压到myzookeeper文件夹中。

如下图,进入zookeeper目录,然后进入conf,然后复制一份zoo.cfg,这么做只是为了有后悔药吃。

解读zoo.cfg

tickTime
通信心跳数,Zookeeper服务器心跳时间,单位毫秒
Zookeeper使用的基本时间, 服务器之间或客户端与服务器之间维持心跳的时间间隔,也就是每个 tickTime 时间就会发送一个心跳,时间单位为毫秒。它用于心跳机制,并且设置最小的session超时时间为两倍心跳时间.(session的最小超时时间是2*tickTime。)大白话就是看该zookeeper是否还活着。
initLimit
这个配置项是用来配置Zookeeper接收Follower客户端(这里所说的客户端不是用户链接Zookeeper服务器的客户端,而是Zookeeper服务器集群中连接到leader的Follower服务器,Follower在启动过程中,会从Leader同步所有最新数据,然后确定自己能够对外服务的起始状态。Leader允许F在 initLimit 时间内完成这个工作)初始化连接是最长能忍受多少个心跳的时间间隔数。当已经超过10个心跳的时间(也就是tickTime)长度后Zookeeper服务器还没有收到客户端返回的信息,那么表明这个客户端连接失败。总的时间长度就是10*2000=20秒。也就是说20秒内搭建好集群。
syncLimit:LF同步通信时限
集群中Leader与Follower之间的最大响应时间单位。
在运行过程中,Leader负责与ZK集群中所有机器进行通信,例如通过一些心跳检测机制,来检测机器的存活状态,
假如响应超过syncLimit * tickTime(假设syncLimit=5 ,请求和应答时间长度,最长不能超过多少个tickTime的时间长度,总的时间长度就是5*2000=10秒。),Leader认为Follwer死掉,从服务器列表中删除Follwer。在运行过程中,Leader负责与ZK集群中所有机器进行通信,例如通过一些心跳检测机制,来检测机器的存活状态。如果L发出心跳包在syncLimit之后,还没有从F那收到响应,那么就认为这个F已经不在线了。
dataDir:数据文件目录+数据持久化路径,保存内存数据库快照信息的位置,如果没有其他说明,更新的事务日志也保存到数据库。
clientPort:客户端连接端口。监听客户端连接的端口。
如上图,要想zookeeper启动,前提是要有java环境。

如上图启动zookeeper,并查看状态,我们可以发现状态是standalone,也就是单机版!

然后如上图启动客户端连接!!然后我们就进入了下面的客户端,我们可以看到有很多命令,而且这些命令跟linux的很像!!

zookeeper的命令
看下图,zookeeper系统中有一个根节点,根节点下有一个zookeeper结点,zookeeper节点下有一个quota结点,我们让zookeeper管理的服务就以结点的形式挂在一棵树上!

quit命令退出zookeeper客户端,但服务端还运行着。

如下图,开启zookeeper客户端,然后创建名为ygp的节点,并为它插入值,然后我们查看根目录下就有两个节点了,然后用get命令得到每个结点的值。

如下图用set更新数据。

所使用的数据模型风格很像文件系统的目录树结构,简单来说,有点类似windows中注册表的结构,
有名称,
有树节点,
有Key(键)/Value(值)对的关系,
可以看做一个树形结构的数据库,分布在不同的机器上做名称管理。
zookeeper结点详解
ZooKeeper数据模型的结构与Unix文件系统很类似,整体上可以看作是一棵树,每个节点称做一个ZNode
很显然zookeeper集群自身维护了一套数据结构。这个存储结构是一个树形结构,其上的每一个节点,我们称之为"znode",每一个znode默认能够存储1MB的数据,每个ZNode都可以通过其路径唯一标识
znode数据结构

节点类型

用create创建节点时,如果什么参数都不加,就默认创建永久结点,如果加个-s,则也是永久结点,但会自增序号,如下图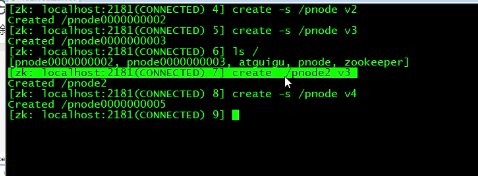
参数-e是临时结点,下次启动就没有了。















 3781
3781











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









