






在线工具推荐: 三维数字孪生场景工具 - GLTF/GLB在线编辑器 - Three.js AI自动纹理化开发 - YOLO 虚幻合成数据生成器 - 3D模型在线转换 - 3D模型预览图生成服务
1、什么是3D渲染?

3D渲染是指通过计算机图形学技术将三维模型转化为二维图像的过程。这个过程涉及到对光照、材质、相机视角等因素的模拟,以产生最终呈现出逼真三维场景的图像。
2、3D渲染的方式
在计算机上可以执行两种类型的 3D 渲染。您可以进行 CPU(中央处理器)渲染或 GPU(图形处理单元)渲染。正如您可能已经猜到的那样,这两者之间的主要区别在于 PC 的哪个部分用于渲染。

CPU 渲染优势
● 可以处理更复杂的任务
与 GPU 性能相比,CPU 可以处理更复杂的任务。GPU 旨在处理专注于单个操作的大量数据。这意味着当所有内核都在同一操作上工作时,GPU 会利用其所有潜力。
但是,在处理多个不同的任务时,GPU 很难将它们同步在一起。这是 CPU 的优势所在,在处理大型复杂 3D 场景时非常重要。
● 更多内存
即使是当今最好的 GPU 也拥有高达 12GB 的内存。但是,即使您将多个 GPU 添加到设备,它们的内存也不会堆叠。如果你对GPU的要求太高,很容易导致你的整个系统崩溃,你最终会失去你的工作。
另一方面,计算机系统内存可以从 8 GB 到 64 GB。即使您能够对 CPU 施加太大的压力,最坏的结果是性能下降。
● 精确的性能
CPU 成为 3D 渲染标准的最大原因很简单,它的整体质量远高于 GPU。如果您希望渲染精确且输出质量达到最高标准,那么 CPU 渲染是最佳选择。
GPU 渲染优势
● 速度
正如我们之前提到的,在速度方面,GPU 优于 CPU。这是因为 GPU 具有更多的核心处理器。GPU 渲染速度大约快五倍,如果您正在寻找速度,这是一个显而易见的选择。
● 一体化解决方案
与 CPU 渲染不同,GPU 不需要您购买最昂贵的计算机来完成高质量的工作。GPU 允许您使用单个 3D 软件处理所有具有挑战性的渲染区域,例如光泽反射和景深。简而言之,GPU 允许您以较低的成本创建高质量的渲染。
● GPU进步非常快
尽管CPU目前是卫冕冠军,但这种情况可能很快就会改变。GPU 每年都在变得越来越好,新技术解决其当前的局限性只是时间问题。
3、影响 3D 渲染性能的因素
使用计算机从预定义的数字模型生成数字图像的过程受许多因素的影响,通常需要大量资源,如时间、处理能力和能源。影响渲染时间的不同因素,从硬件到分辨率、设置和渲染引擎、3D 软件中的特殊渲染性能,具体因素有:模型复杂性、纹理和材质、光照和阴影、 分辨率、渲染技术和算法、硬件规格、渲染引擎优化、并行处理能力、显存管理、驱动程序和软件更新。
通过综合考虑这些因素,优化模型、使用适当的硬件、选择合适的渲染设置以及采用高效的渲染算法,可以提高3D渲染的性能。
4、如何提高3D渲染效率
了解了影响3D渲染性能的具体原因后,要提升3D渲染效率,可以考虑以下一些建议:
硬件升级:
- 升级显卡:选择性能更强大的显卡,支持最新的图形技术。
- 增加内存:更大容量的内存可以减少渲染过程中的数据交换,提高效率。
- 快速存储:使用SSD等高速存储设备,加快纹理和模型加载速度。
优化场景和模型:
- 减少多边形数量:简化场景中的模型,减少多边形数量可以提高渲染速度。
- 使用LOD(层次细节):在不同距离使用不同细节级别的模型,提高性能。
- 移除不可见物体:及时剔除或优化渲染不可见的物体,减轻渲染负担。
软件设置和调优:
- 调整渲染设置:根据项目需求和硬件性能,合理调整渲染设置,平衡画质和性能。
- 利用并行处理:充分利用多核处理器,启用渲染引擎的并行处理功能。
- 使用GPU渲染:确保3D渲染软件配置正确,充分利用图形处理单元的计算能力。
缓存和预处理:
- 利用缓存:合理使用渲染缓存,避免重复计算相同的纹理或光照信息。
- 预处理纹理:提前生成并优化纹理,减少运行时计算。
渲染技术优化:
- 使用低分辨率预览:在调试和编辑阶段使用低分辨率预览,加快交互响应。
- 利用GPU加速:使用支持GPU加速的渲染技术,提高实时渲染性能。
从上面可以看出,想要提高3D渲染的效率好像不是那么简单或者不是那么经济?有没有一种既简单又经济的方式呢?
5、提升3D渲染效率的简单又经济的方式
模型合批(Batching)是一种优化技术,用于在计算机图形渲染中提高性能和效率。它通过将多个模型的渲染操作合并为一次来减少渲染调用的数量,从而提高渲染性能。
GLTF 编辑器 支持模型材质合批以此来提高模型的渲染性能。
下面讲解如何进行模型合拼操作,首先将模型拖入编辑器中,如图所示:
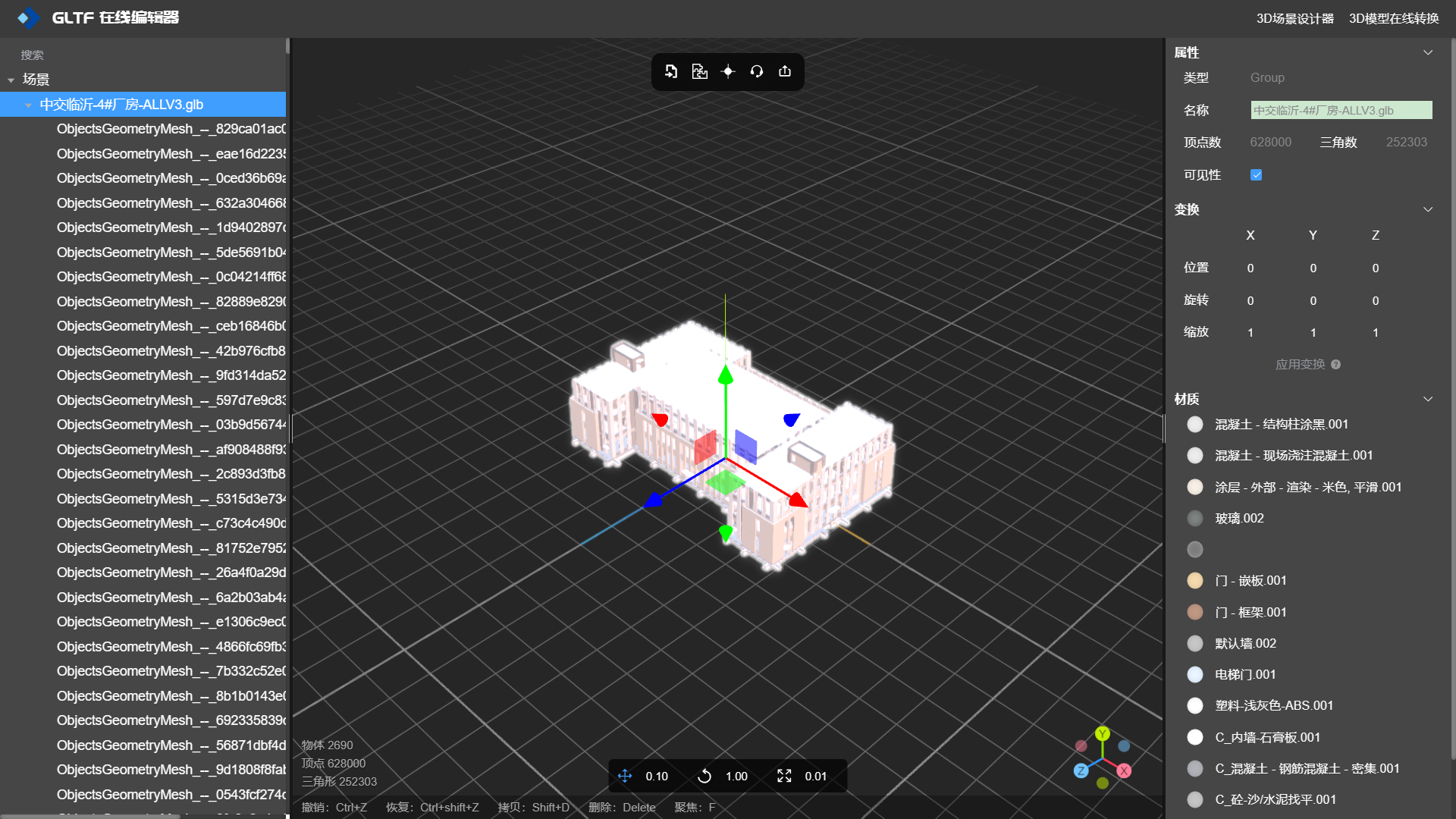
材质合并前
从图中的左侧面板中可以看到该模型中有很多相同材质。
查看模型FPS信息,如图所示:

模型合批前,FPS是13,渲染效果不太流畅
下一步,材质合批:只需要点击GLTF 编辑器工具栏上第二个按钮【合并相同材质的Mesh】,编辑器就会自动将模型中相同的材质进行合并,合并完成后将修改后的模型导出到本地GLB文件。
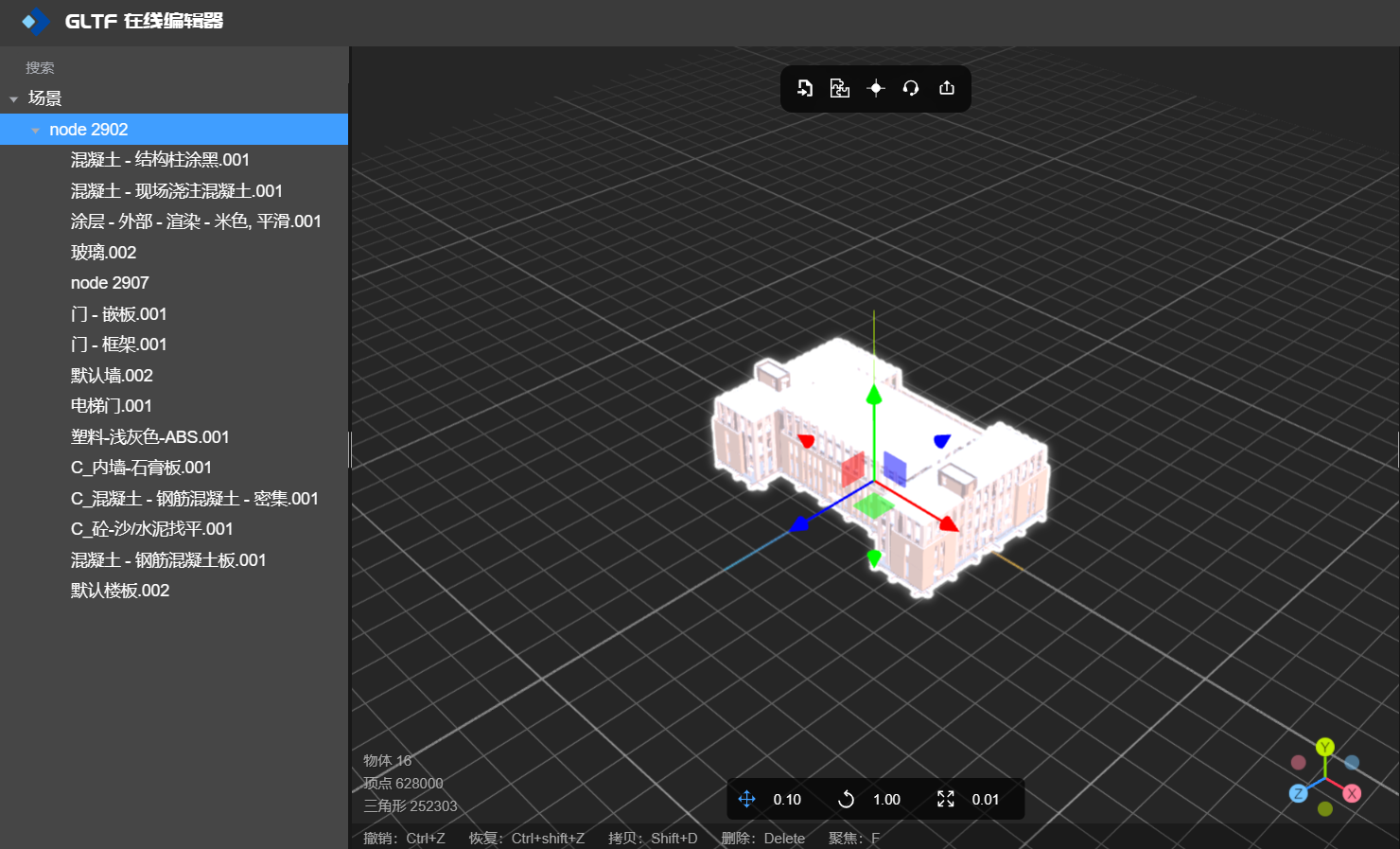
材质合并后
下面材质合并前后的FPS对比:

模型合批后,FPS是47,有着明显的提升

















 1245
1245

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









