







根据前人的成果进行了学习 https://www.cnblogs.com/ahu-lichang/p/7161613.html#commentform
1、算法介绍
其实k最近邻算法算是聚类算法中最浅显易懂的一种了,考虑你有一堆二维数据,你想很简单的把它分开,像下图这样分成四类

你当然可以选择肉眼辨别,拿个铅笔给它们分开,但是如果这些数据多到你一天都看不完呢?又或者在你辛苦了一天分类完毕后,突然发现你其实应该分成三类而不是四类的,得,重来吧。
虽然人工分类在我们看起来挺弱智的,但实际上k最近邻算法的核心思想就跟我们日常分类差不多。我们会自然而然的把“扎堆”的点分成一类,术语可以讲,按照欧氏距离来分类,当我们考虑把这种想法用程序实现的时候,那就变成了k最近邻算法了。
2、算法步骤
大概有以下几点
1. 先按照你想分的类别数,随机找几个点作为每一类的中心点
2. 根据你采用的距离计算方式(欧氏距离、曼哈顿距离等),将所有点按照最近邻的方式归到这几个中心点的类别中去
3. 分类完毕后,根据每一类的所有点,来重新计算一个新的中心点来替代上一次使用的中心点
4. 重复2,3,直到中心点不再变化,称之为收敛的时候,就完成了分类
3、具体代码
下面按照2中的算法步骤,采用python进行编程
1. 首先是生成k个随机中心点,此次取4
def randCent(dataSet,k): ndim = array(dataSet).shape[1] # 初始化中心点数组 centsArray = zeros((k,ndim)) # 这一步的操作是将初始随机中心点的每个维度的值限定在数据点的维度值域之间,二维的话就是说中心点不会处在 # 数据点组成的“域”之外 for i in range(ndim): minIDim = min(array(dataSet)[:,i]) maxIDim = max(array(dataSet)[:,i]) rangeIDim = maxIDim-minIDim centsArray[:,i] = (minIDim + rangeIDim * random.rand(k, 1)).reshape(centsArray[:, i].shape) return centsArray(我这里由于个人对python及numpy包的运用不熟练,导致。。。很多操作可能看起来很麻烦,经过这次之后要去系统性的学习一下相关知识)
2. 这里将步骤中的2,3,4合并为一个函数实现
采用欧氏距离作为判别标准,根据数据点与中心点的欧氏距离大小进行分类
计算欧氏距离的函数
def distEclud(vecA,vecB): return sqrt(sum(power(vecA-vecB,2)))然后是主要的函数
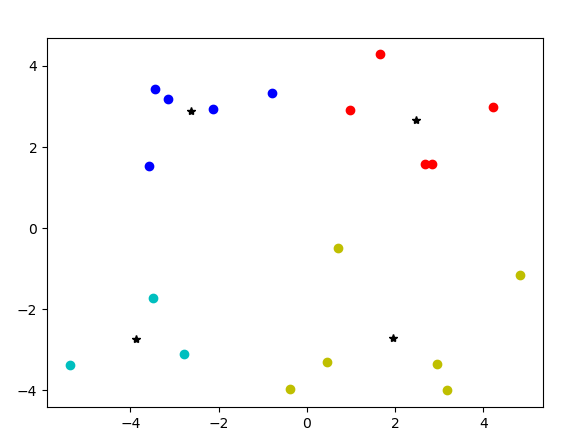
3. 测试代码def kMeans(dataSet,k): # 数据总量 num = dataSet.shape[0] # 建立一个数组存储每个点的类别和与对应中心点的欧氏距离 clusterAssignmentArray = zeros((num,2)) centsArray = randCent(dataSet,k) clusterChanged = True while clusterChanged: clusterChanged = False for i in range(num): minIndex = -1 minDist = inf for j in range(k): diEclud = distEclud(dataSet[i],centsArray[j]) if diEclud<minDist: minDist = diEclud minIndex = j if clusterAssignmentArray[i][0]!=minIndex: clusterAssignmentArray[i] = minIndex,minDist clusterChanged = True # 根据新的分类结果中每一类的数据点,重新计算每一类的中心点 for centIndex in range(k): # 根据minIndex取出每一类的数据点进行计算 ptrInClust = [] for j in range(num): if clusterAssignmentArray[j][0]==centIndex: ptrInClust.append(dataSet[j]) centsArray[centIndex, :] = mean(ptrInClust, axis=0) return centsArray,clusterAssignmentArrayif __name__ == "__main__": k = 4 datMat = mat(loadDataSet('1.txt')) myCentroids, clustAssing = kMeans(datMat, k) x = [] y = [] x.append(((myCentroids[:, 0]).tolist())) y.append((myCentroids[:, 1]).tolist()) # plt.plot(x[0], y[0], 'b*') plt.plot(((myCentroids[:, 0]).tolist()), (myCentroids[:, 1]).tolist(), 'k*') colourList = ['bo', 'ro', 'yo', 'co','ko'] for i in range(k): centX = [] centY = [] for j in range(19): if clustAssing[j].tolist()[0] == i: centX.append(datMat[j].tolist()[0][0]) centY.append(datMat[j].tolist()[0][1]) plt.plot(centX, centY, colourList[i]) plt.show()
最后,可以看到已经完成了分类,其中黑星代表中心点。当然,如果你多跑几次,会发现。。。每次的结果未必一样,这也是一个坑
4. 完整代码
https://github.com/ShenYuhan/ml-python/blob/master/knn_eclud.py
5. 数据,空格分割
1.658985 4.285136 -3.453687 3.424321 4.838138 -1.151539 -5.379713 -3.362104 0.972564 2.924086 -3.567919 1.531611 0.450614 -3.302219 -3.487105 -1.724432 2.668759 1.594842 -3.156485 3.191137 3.165506 -3.999838 -2.786837 -3.099354 4.208187 2.984927 -2.123337 2.943366 0.704199 -0.479481 -0.392370 -3.963704 2.831667 1.574018 -0.790153 3.343144 2.943496 -3.357075















 354
354

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









