







本文主要就笔者在实际工作中遇到的一些在统计分析领域的编程风格和代码技巧做一汇总;由于是想到哪就写到哪,所以文档前后并没有什么太强的逻辑性和关联性,就当做是一次随笔吧。(将会持续更新,把自己遇到的好的写法在此处做已记录和分析,大家若是有好点,尽可留言告知,相互学习,共同进步 ^v^)
笔者在数据分析主要是用到了Python(2.7)以及两个主要的依赖:Numpy 和 Pandas,有关这两个依赖的基础用法,可自行百度,这里不做赘述。推荐一本数据分析入门级的书:《利用Python进行数据分析》,有兴趣的同学可以去看看。废话不多说,直入正题。
基于字典构造DataFrame
eg:有如下字典
import pandas as pd
dic = {'name': ['jack', 'lucy'], 'sex': ['male', 'female'], 'age': [10, 9]}想转成DataFrame,很容易:
frame = pd.DataFrame(dic)
print(frame)结果如下:
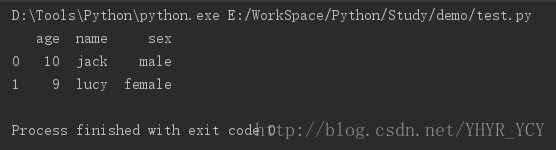
但是如果字典的结构为:
dic = {'name': 'jack', 'sex': 'male', 'age': 10}这直接用上述方法转化为DataFrame就会报错。如下所示:
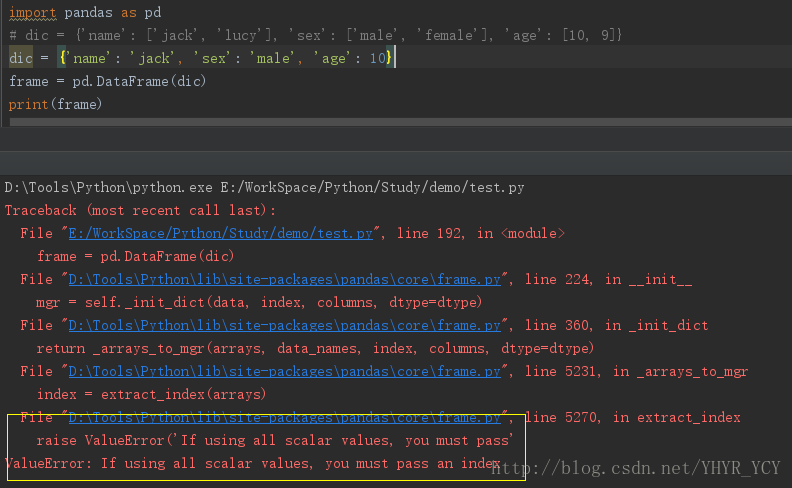
要规避这种错误,可以采用如下方式:
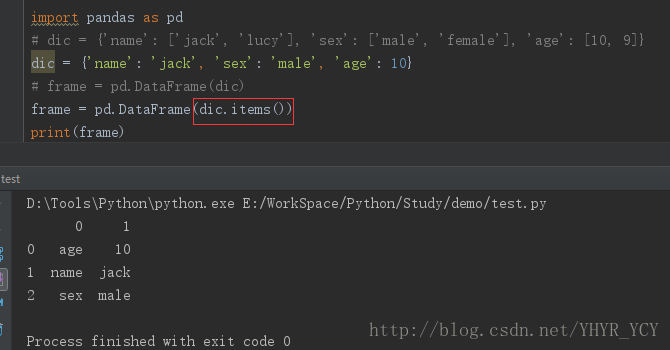
但是不难发现,这种转化结构和前者相比有点不太一样,加入我们想要的效果就如上图所示,那没什么问题,可加入index和column属性来分别设置行属性值和列属性值;倘若我们想要的效果是如最开始那种,已字典的key作为每一列的列名的话,可选用如下方法:
1,将字典转化成字典列表 dicList = [{'name': 'jack', 'sex': 'male', 'age': 10}]
2,采用pd.DataFrame.from_records(dicList)来构造
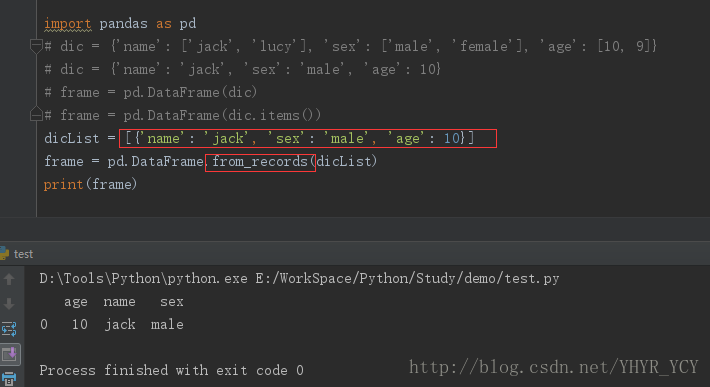
在实际的项目开发中,存在如下的一种需求:字典的key和value均期望成为DataFrame的列值,而非将字典的key转化为columns名,对于该需求:可采用如下方式:
# 性别-代号 映射
dic = {'male': '1', 'female': '2'}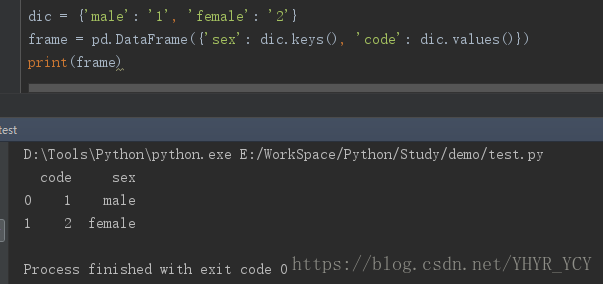
基于DataFrame的数据筛选
获取列中的值
eg: dataframe中存在一列相同的值,但该列的index未必有序,此时若想获取其中一个值,有如下两种方法:
方案一:将该列转化为list,然后获取第一个值即可 value = list(frame[columns_name])[0]
方案二:value = frame[columns_name].values[0]
注:方案一在数据量过大的时候存在性能问题,推荐使用方案二
列筛选
dataframe[columns_name] # 返回值类型:Series, 仅支持单列筛选
dataframe.loc[:, [columns_name]] # 返回值类型:DataFrame, 支持同时筛选多列行筛选
类比列筛选,行筛选也可以根据返回值类型划分为两大类:返回DataFrame类型和返回Series类型
DataFrame类型 (均支持多行筛选)
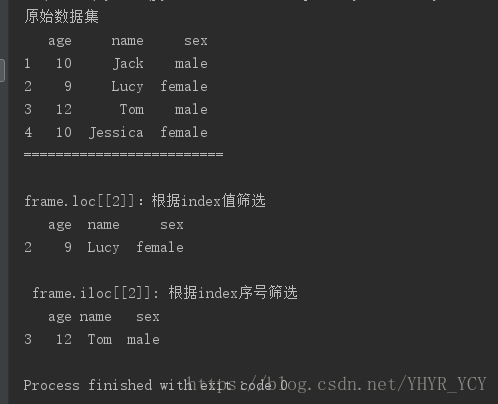
1)按照Index的具体值筛选:dataframe.loc[[index]],如果指定值不存在,则会报错
2) 按照index的序号值筛选:dataframe.iloc[[index]],不care当前index的具体值是多少(index的起始下标为零)
Series类型 (均不支持多行筛选)
1)按照index的具体值筛选:dataframe.loc[index]
2)按照index的序号值筛选:dataframe.iloc[index]
条件筛选
列条件筛选
例如:有如下数据集:frame:
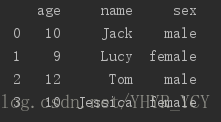
如果只想获得所有的name和age属性,可以很容易通过loc函数实现;
df = frame.loc[:, ['name', 'age']]场景一:单一条件筛选 frame.loc[condition, :] 等价于 frame.loc[condition]
eg:找到所有年龄小与等于10的人信息,可表示为:
condition = frame['age'] <= 10
df = frame.loc[condition, :]或
# 个人习惯用这种方式,减少代码量 ^o^
df = frame.loc[frame['age] <= 10, :]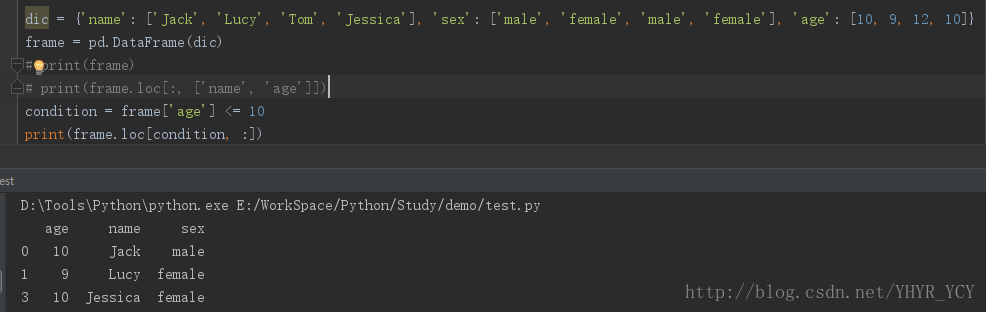
场景二:范围筛选
eg:找到名叫Tom或者Lucy或者Jessica的所有信息
df = frame.loc[frame['name'].isin(['Lucy', 'Tom', 'Jessica']), :]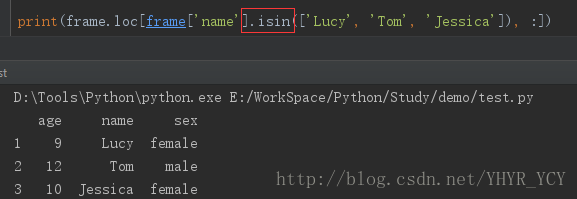
场景三:多条件筛选 frame[(condition1) & (condition2), :] 等价于 frame[(condition1) & (condition2)]
eg:找到年龄等于10且性别为女的所有人的详细信息
df = frame.loc[frame['age'].isin([10]) & frame['sex'].isin(['female']), :]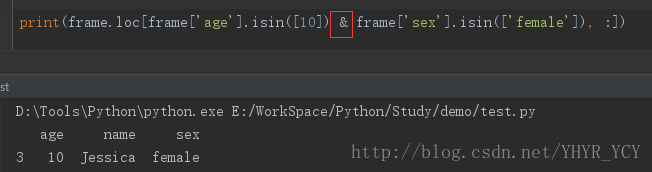
注意:多列筛选时,每个条件只能用isin做判断,不能直接用等于、小/大于等于做判断。
场景四:条件取反
eg:找出除Jack和Tom以外的所有人的详细 信息
df = frame.loc[~frame['name'].isin(['Jack', 'Tom']), :]DataFrame增添列时报SettingWithCopyWarning
当在项目代码中按如下方式
df['newCol'] = value为已知的dataframe增添一列值时,有时会遇到如下警告:
SettingWithCopyWarning: A value is trying to be set on a copy of a slice from a DataFrame.
可采用insert方法代替直接复制的方式(可自定义插入列的位置),在满足需求的同时,消除warning。
DataFrame.insert(列序值, 列名, 待插入的值)DataFrame 行添加
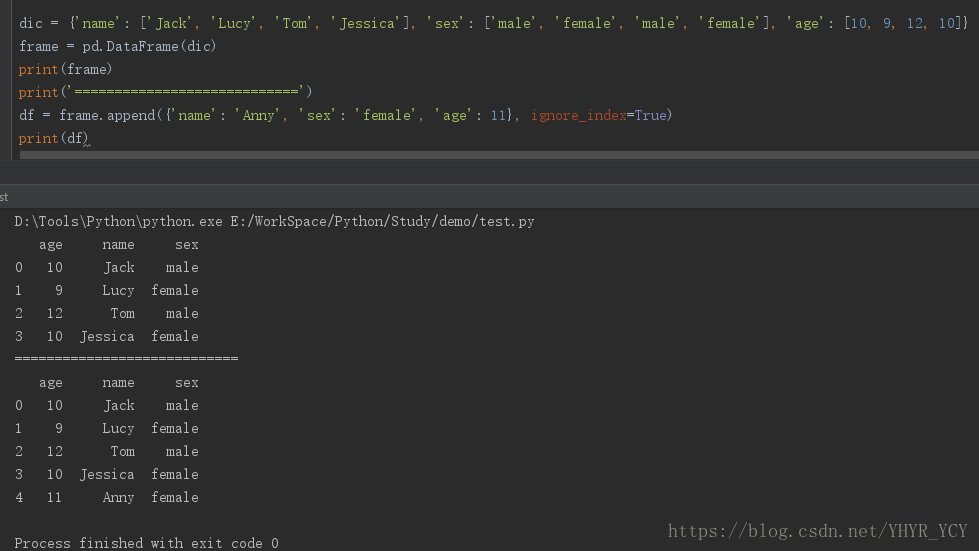
在已有的dataframe中增添一行数据:df = frame.append(dic, ignore_index=True)
eg:新增一个用户信息:
DataFrame排序
场景一:按照某一列排序(数值类型默认按照升序,字符串类型默认按照首字符的排列顺序)
eg:按照年龄由小到大排序
# ascending=1 代表升序(默认), =0代表降序
frame.sort_values(['age'], ascending=1)场景二:按照自定义顺序排序
eg:将上述数据按照【Tom,Jessica, Jack, Lucy】的顺序进行排序
sortList = ['Tom', 'Jessica', 'Jack', 'Lucy']
frame['name'] = frame['name'].astype('category')
frame['name'].cat.set_categories(sortList, inplace=True)
frame.sort_values('name', inplace=True)
frame['name'] = frame['name'].astype('object')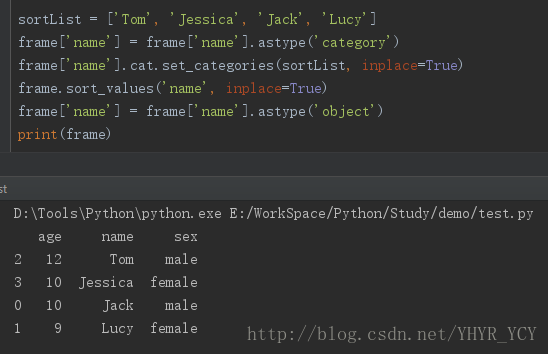
这里引入了一个新的东西:pandas中的另外一个数据类型:Categorical
个人理解:该数据类型主要有两中应用场景(官方文档上说有三种,个人感觉第三种在实际工作中用到的并不多,也未多涉猎,故在此省略):第一,可以数据的内存占有率,官方Doc上有个对比,同等数据量的object对象和category对象相比,后者的大小明显小于前者;再次直接截下官网Doc中的样例加以说明:
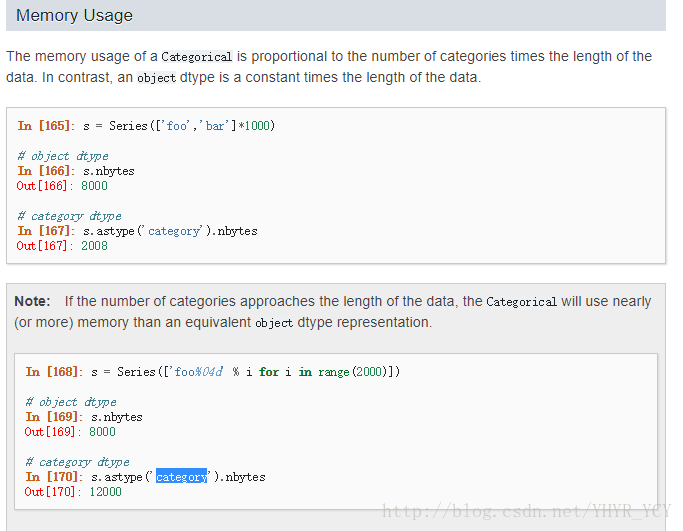
因为笔者在实际工作中对该场景的应用不是很多,所在在此未做过多涉猎,就在这简单提及一下,有兴趣的可以参考:官方Doc
在这里重点说一下第二个应用场景,即就是列表排序;可以将传统的Object类型的DataFrame列转化为category类型,即可采用:reorder_categories方法或者set_categories方法进行排序。两者之间的区别:
reorder_categories:要求指定排序列表的个数必须和待排序的DataFrame列中元素个数相等;即内容必须相同,但顺序不同;
set_categories:排序列表的个数可以不等同于DataFrame列中的元素个数;当排序列表的元素个数大于DataFrame列中的元素时,排序后去交集;反之,排序后DataF会有Nan值。
DataFrame合并(concat)
场景一:纵向合并
有如下数据集
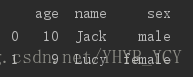
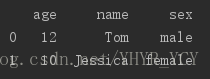
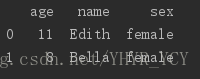
若把这三个表纵向合并为一个表:
df = pd.concat([dataSet1, dataSet2, dataSet3])场景二:横向合并(merge)
例如有如下数据集
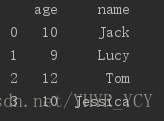
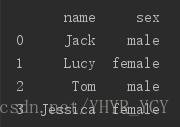

这三个数据集都有一个共有字段:name,如果想把这三个数据集做横向合并(merge),原生的pandas是没有提供类似concat这种接口可供直接使用的;所以就得我们自己手动实现该功能:
最容易想到的办法:循环遍历数据集列表,然后做merge。
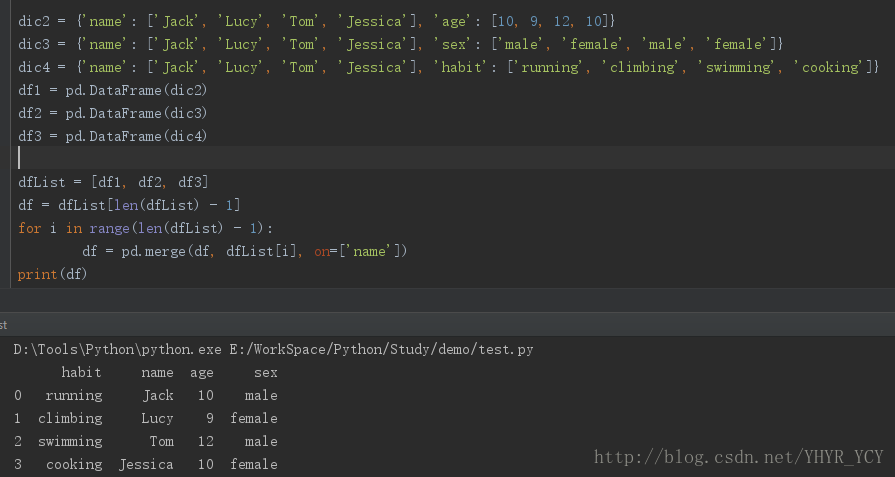
或者先通过concat,然后转置。
在这里,推荐一下比较简洁的写法:采用函数式编程中的reduce函数实现:
df = reduce(lambda x, y: pd.merge(x, y, on=['name']), [df1, df2, df3])
是不是感觉看起来很直观,很简洁 ^o^
基于函数式编程中的map函数来消除基于for循环遍历List
map函数是一种映射思想,既可以基于map函数来映射list中的每一个值,从而实现遍历的效果。
例如:对数组中每个元素的平方
dataList = [1, 2, 3, 4, 5]
map(lambda x: x * x, dataList)map函数的返回值即就是一个list
两个List的奇偶合并
该逻辑的实现方案有很多,在此推荐一种笔者比较钟意的方案:
list1 = [1, 3, 5, 7, 9]
list2 = [2, 4, 6, 8, 10]
mergeList = [None] * (len(list1) + len(list2))
mergeList[::2] = list1
mergeList[1::2] = list2注:【::2】表示以数组中第一个位置作为起始位置,间隔跨度为2;【1::2】表示以数组中第二个位置作为起始位置,间隔跨度为2














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









