







注:此爬虫项目及其数据仅作学术学习使用
Prepare
Python 版本
Python 3.6.5
依赖包
scrapy_redis
redis
mysql-python
kafka-python
hdfs
数据API接口
详见Github
Implement
数据依赖关系
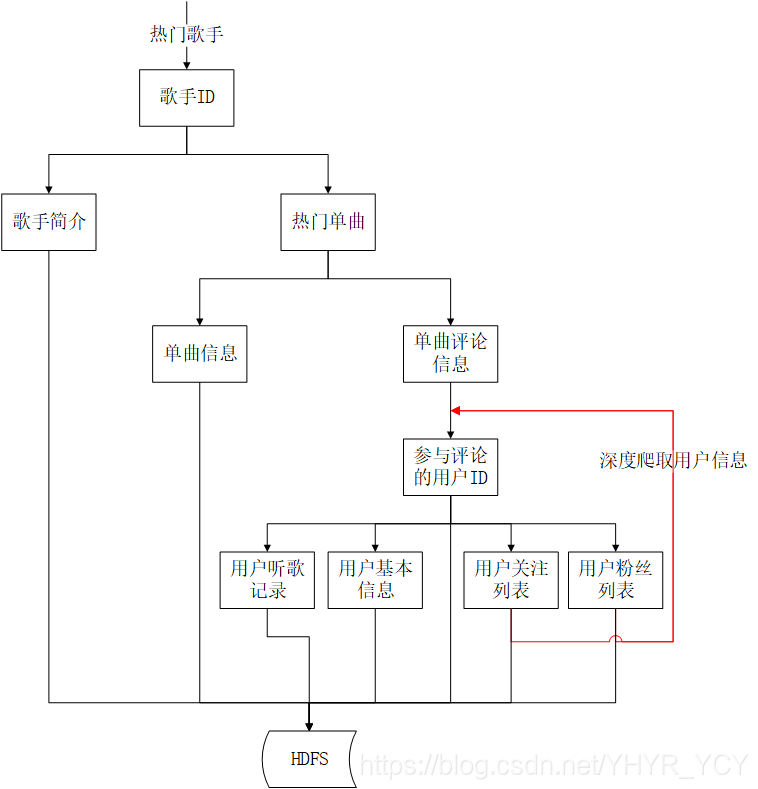
时序
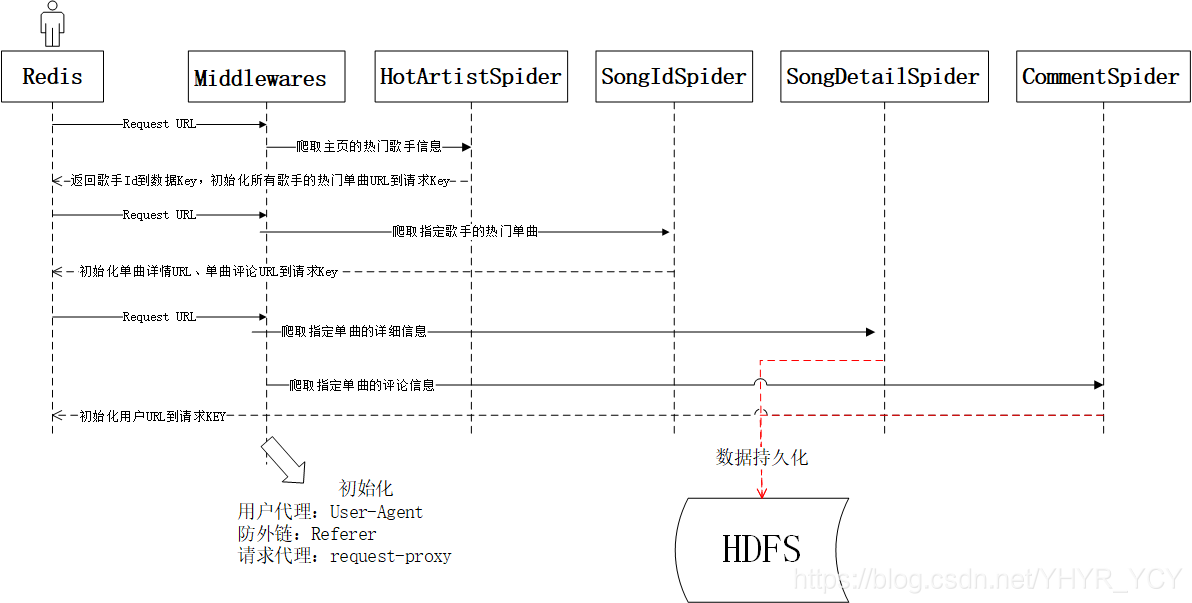
上图详细说明了整个爬虫工程的前一半的数据抽取逻辑;关于用户类数据的抽取在实现逻辑上与上图基本一致。在用户相关数据的爬取上,实现了在尽可能多的爬取用户数据的同时,有效规避重复爬取。实现逻辑如下:
在代码实现层面上,显示的指定用户相关数据的爬取逻辑。优先级为:用户基本信息 > 用户粉丝信息 = 用户关注信息 = 用户听歌记录。即就是只有在爬取到一个用户的基本信息以后,才初始化这个用户的附属信息的URL(例:粉丝列表、关注列表、听歌记录)。这样就可以保证只要爬取用户基本信息时不重复,则附属属性数据的爬取就不会重复。所以在Redis中单独维护一个用户UserId的数据集,每当爬取歌曲的评论数据、用户的粉丝或者关注者数据时,都会先校验当前用户是否在该数据集内;如果不在则初始化用户的基本信息URL到请求队列中,反之则认为该用户已经爬取过。
为了提升用户数据量,在收集歌曲评论中所涉及到的用户信息的同时,深度爬取每个用户所对应的关注和粉丝列表的信息。
数据存储
这里选择将爬取到的数据持久化到HDFS中,便于单机自测;如果想真正的基于多机器实现分布式爬取数据,建议将数据改写到Kafka中;因为HDFS的特性为一次写,多次读;且不支持在统一文件的任意offset进行写操作;因此对于HDFS文件的操作只有append,且不支持并发写操作。如果提升爬虫效率,建议将数据先写入Kafka,然后通过后台脚本通过多线程/多进程进行消费和持久化操作。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 9458
9458











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









