







文章目录
T-SQL 数据查询语言
1. 计算列
//从emp表查询所有信息
select * from emp;
//查询emp表的员工名字ename和工资sal
select ename, sal from emp;
//计算出每位员工的年薪(as可省略)
select ename, sal*12 as "年薪" from emp;
//输出的行数是emp表的行数,每行只有一个字段5
select 5 from emp;
//查询emp表的ename、年薪、月薪、job
selcet ename, sal*12 as "年薪", sal "月薪", job from emp;
2. distinct
distinct不允许重复的
//查询emp表里的部门标号deptno(14行记录,并不是3行记录)
select deptno from emp;
//14行记录,每行只有一个字段1000
select 1000 from emp;
//distinct deptno会过滤掉重复的deptno
select distinct deptno from emp;
//奖金comm里有空值,distinct也可以过滤掉重复的null
select distinct comm from emp;
//整体过滤,即它们的组合没有重复,单独有重复
select distinct comm, deptno from emp;
//报错,逻辑上有冲突
select deptno, distinct comm from emp;
3. between
//查找工资在1500到3000之间(闭区间)的所有员工的信息
select * from emp; //顺序:先执行from,再看输出哪个字段
select * from emp
where sal>=1500 and sal<=3000 //等价于
select * from emp
where sal between 1500 and 3000
---------------------
//查找工资在小于1500或大于3000的所有员工的信息
select * from emp
where sal<1500 or sal>3000 //等价于
select * from emp
where sal not between 1500 and 3000
4. in
in属于若干个孤立的值
//把工资是1500、3000、5000的员工信息输出
select *
from emp
where sal in (1500, 3000, 5000)
//等价于
select *
from emp
where sal=1500 or sal=3000 or sal=5000
---------
//把sal不是1500、3000、5000的输出
select *
from emp
where sal not in (1500, 3000, 5000)
等价于-------
select *
from emp
where sal<>1500 and sal<>3000 and sal<>5000
//不等于:!=或<>
//对or取反是and,对and取反是or
5. top
top最前面的若干个记录
//输出emp表的全部信息
select * from emp;
//前两行记录输出
select top 2 * from emp;
//前15%的数据输出
select top 15 percent * from emp;
应用:
//把1500到3000之间工资最高的前4个输出
select top 4 *
from emp //从emp中选
where sal between 1500 and 3000 //过滤,保存工资在1500~3000的员工
order by sal desc //过滤后的数据进行排序,desc降序排序,不写默认升序
//再把前4个输出
6. null
null没有值,0表示一个确定的值
//输出奖金非空的员工的信息
select * from emp;
//原因:null不能参与<>、!=、=运算
select * from emp where comm <> null; //输出为空,报错
select * from emp where comm != null; //输出为空,报错
//null可以参与is、not is
select * from emp where comm is null; //输出奖金为空的员工的信息
select * from emp where comm is not null; //输出奖金不空的员工的信息
insert into t1 values(null, null, null); //任何类型的数据都允许为null
应用:输出每个员工的姓名、年薪(包含了奖金)comm是一年的奖金,comm里有数据为null
select ename, sal*12+comm "年薪" from emp;
//任何数字于null参与数学运算,结果永远为null
select ename, sal*12+isnull(comm,0) "年薪" from emp;
//isnull(comm, 0)如果comm是null,就返回0
7. order by
order by以某个字段排序
select * from emp order by sal; //默认升序排序
select * from emp order by deptno, sal; //先按部门deptno排,再按sal排
select * from emp order by deptno desc, sal; //先按deptno降序排,再按sal升序排,desc对sal不影响
select * from emp order by deptno, sal desc; //不影响deptno,先按deptno升序排,再按sal降序排
8. 模糊查询
格式:select 字段的集合 from 表名 where 某个字段的名字 like 匹配的条件
匹配的条件通常含有通配符:
%:任意0个或多个字符
_:任意单个字符
[a-f]:只能是a、b、c、d、e、f中的任意一个字符
[a,f]:a或f
[^a-c]不是a,也不是b,也不是c的任意单个字符
注意:匹配的条件必须用单引号括起来
select * from emp where ename like '%A%' //ename只要含字母A就输出
select * from emp where ename like 'A%' //ename只要首字母是A就输出
select * from emp where ename like '%A' //ename只要尾字母是A就输出
----------
select * from emp where ename like '_A%' //只要第二个字母是A的就输出
----------
select * from emp where ename like '_[A-F]%' //第二个字符是A~F的输出
select * from emp where ename like '_[^A-F]%' //第二个字符不是A~F的记录输出
----------
找name里有%的信息,\为转义字符
select * from student where name like '%\%%' escape '\'
找name里有_的信息
select * from student where name like '%\_%' escape '\'
9. 聚合函数
聚合函数:多行记录返回至一个值,通常用于统计分组的信息
函数的分类:
单行函数:每一行返回一个值
多行函数:多行返回一个值,聚合函数是多行函数
聚合函数的分类:
max()
min()
avg() 平均值
count() 求个数
count(字段名)返回字段值非空的记录的个数,重复的记录也被当作有效的
select lower(ename) from emp; //最终返回14行,lower()是单行函数
select max(sal) from emp; //最终返回1行,max()是多行函数
--------------
select count(*) from emp; //返回emp表所有记录的个数
select count(deptno) from emp; //返回值14,说明deptno重复的记录也被当作有效的
select count(distinct deptno) from emp; //返回值3
select count(comm) from emp; //返回值是4,说明comm为null的记录不会被当作有效的
注意的问题:
select max(sal), min(sal), count(*) from emp;这样写可以
select max(sal) "最高工资", min(sal) "最低工资", count(*) "员工人数" from emp;
select max(sal), lower(sal) from emp;报错,单行函数和多行函数不能共用
10. group by
group by字段的集合
功能:把表中的记录按照字段分成不同的组
查询每个部门的平均工资
select deptno, avg(sal) as "部门的平均工资"
from emp
group by deptno //按部门标号分组,值就变成了10一组、20一组、30一组
使用了group by后,select中只能写分组后(3组)的整体信息,不能写组内信息
select deptno, ename //不能加ename
from emp
group by deptno
group by a, b, c的用法:先按a分组,如果a相同,再按b分组,如果b相同,再按c分组,最终统计的是最小分组的信息
输出每个部门deptno的不同职业job的平均工资、部门人数、部门总工资、部门最低工资(按部门编号排序)
select deptno, job, avg(sal) "平均工资", count(*) "部门人数", sum(sal) "部门总工资", min(sal) "部门的最低工资"
from emp
group by deptno, job //大组deptno,小组job
order by deptno //按deptno排序
//只要是聚合函数都可以使用
select可以填deptno、job、聚合函数,不能填*、ename
avg(sal)、count(*)、sum(sal)、min(sal)统计的是最小分组的信息
11. having
having:对分组之后的信息进行过滤
使用having时,通常先使用group by
having子句出现的字段必须是分组后的组的整体信息
- 查询部门平均工资大于
1500的部门的部门编号、部门的平均工资
select deptno, avg(sal) as "平均工资"
from emp
group by deptno
having avg(sal) > 2000
- 把姓名不包含
A的所有员工按部门编号分组,并输出部门平均工资大于2000的部门的部门编号、部门的平均工资
having不能对姓名进行过滤,而且姓名要在分组之前过滤(因为分好组后,就没法查姓名了)
select deptno, avg(sal) "平均工资"
from emp
where ename not like '%A%'
group by deptno
having avg(sal) > 2000
- 把工资大于
2000,并输出部门平均工资大于3000的部门的部门编号、部门的平均工资
select deptno, avg(sal) "平均工资"
from emp
where sal > 2000
group by deptno
having avg(sal) > 3000
where对原始的记录过滤,having对分组之后的记录过滤
where必须写在having前
所有select的参数的顺序是不允许变化的,否则编译后出错
12. 连接查询
定义:将两个表或者两个以上的表以一定的连接条件连接起来,从中检索出满足条件的数据
emp表(14/8):empno员工编号、ename员工姓名、job工作、mgr、hiredate雇佣日期、sal工资、comm奖金、deptno部门编号、
dept表(5/3):deptno部门编号、dname部门名称、loc地址
salgrade表:grade等级、losal、hisal
内连接
1. select ... from A, B
select * from emp, dept
emp表14行8列,dept表5行3列,生成的表:70行11列(笛卡尔积)
前14行:dept第1行 + emp的14行 拼接
15行~28行:dept的第2行 + emp的14行 拼接
29行~42行:dept的第3行+ emp的14行 拼接
2. select ... from A, B where ...
对A、B产生的笛卡尔积用where条件过滤
//输出员工编号为7369的所有信息
select *
from emp, dept
where empno = 7369
//输出为5行11列,empno这一行+dept的五行 拼接
3. select ... from A join B on ...
select * //输出70行11列
from emp "E"
join dept "D"
on 1=1 //on连接条件
select "E".ename "员工姓名", "D".dname "部门名称" //输出70行2列
from emp "E"
join dept "D"
on 1=1 //on连接条件
---------------------------
select deptno //报错:两个表里都有deptno,改为"E".deptno或"D".deptno
from emp "E"
join dept "D"
on 1=1 //on连接条件
输出每个员工的姓名、部门名称:
select "E".ename "员工姓名", "D".dname "部门名称"
from emp "E"
join dept "D"
on "E".deptno = "D".deptno
//join连接:70行11列(笛卡尔积),on连接条件:14行2列
//只有E和D里的deptno相等时,才能连接
4. select ... from A, B where ...与select ... from A join B on ...的比较
select *
from emp, dept
where emp, deptno = dept.deptno
//等价于(14行11列),推荐使用jion on
select *
from emp
join dept
on emp.deptno = dept.deptno
把工资大于2000的员工的姓名和部门的名称输出
select "E".ename, "D".dname
from emp "E", dept "D" //此时产生的是70行2列,开始用where过略
where "E".sal > 2000 and "E".deptno = "D".deptno
------------
select "E".ename, "D".dname
from emp "E"
join dept "D"
on "E".deptno = "D".deptno //连接完是14行2列
where "E".sal > 2000
把工资大于2000的员工姓名 和 部门的名称输出 和 工资等级
select "E".ename, "D".dname, "S".grade
from emp "E"
join dept "D"
on "E".deptno = "D".deptno
join salgrade "S" //两个join后,没有连接条件时,14*5*5行=350行,14列
on "E".sal >= "S".losal, "E".sal <= "S".hisal
where "E".sal > 2000
同时使用:on指定连接条件,where对连接之后临时表的数据进行过滤
//输出的行数一定是emp表行数的倍数
select * from emp, dept
where dept.deptno = 10 //过滤条件
等价于-------
select *
from emp
join dept
on 1 = 1
where dept.deptno = 10
5. select from where join on group by order top having 的混合使用
习题:
emp表:empno员工编号、ename员工姓名、job工作、mgr领导的编号、hiredate雇佣日期、sal工资、comm奖金、deptno部门编号、
dept表:deptno部门编号、dname部门名称、loc地址
SALGRADE表:GRADE等级、LOSAL、HISAL
- 求出每个员工的姓名、部门编号、薪水、薪水的等级
select "E".ename, "E".deptno, "E".sal, "S".grade
from emp "E"
join salgrade "S"
on "E".sal >= "S".losal and "E".sal <= "S".hisal
//连接表:emp和salgrade
- 查找每个部门的编号、该部门的平均工资、平均工资等级
select deptno, avg(sal) as "avg_sal"
from emp
group by deptno
//按部门编号分组(3组),此时已经有了临时表:deptno|avg
----------
//将临时表"T"与salgrade连接
select "T".deptno, "T".avg(sal) "部门平均工资", "S".grade "工资等级"
from (
select deptno, avg(sal) as "avg_sal"
from emp
group by deptno
) "T"
join salgrade "S"
on "T".avg_sal between "S".losal and "S" hisal
等价于---------
select "T".deptno, "T".avg(sal) "部门平均工资", "S".grade "工资等级"
from salgrade "S"
join (
select deptno, avg(sal) as "avg_sal"
from emp
group by deptno
)"T"
on "T".avg_sal between "S".losal and "S" hisal
- 查找每个部门的编号、该部门的平均工资、平均工资等级、部门名称
select "T".deptno, "T".avg(sal) "部门平均工资", "S".grade "工资等级", "D".dname "部门名称"
from (
select deptno, avg(sal) as "avg_sal"
from emp
group by deptno
) "T"
join salgrade "S"
on "T".avg_sal between "S".losal and "S" hisal
join dept "D"
on "T".deptno = "D".deptno
- 求出emp表中所有领导的信息
select * from emp
where empno in (select mgr from emp)
//所有领导的编号:select mgr from emp,所有员工的编号empno
----------
求出emp表中所有非领导的信息
select * from emp
where empno not in (select mgr from emp)
- 求出平均薪水最高的 部门编号 和 部门的平均工资
select top 1 depno, avg(sal) "avg_sal"
from emp
group by deptno
order by avg(sal) desc
- 把工资最低的人排除掉,剩下的人中工资最低的前3个人
的姓名、工资、部门编号、部门名称、工资等级
工资最低的人:select min(sal) from emp,要把它给过滤掉
select *
from emp "E"
where sal > (select min(sal) from emp)
//过滤最低工资的人,把这个表当作临时表
----------
slelect top 3 "T".ename, "T".sal, "T".deptno, "D".dname, "S".grade
from(
select *
from emp "E"
where sal > (select min(sal) from emp)
) "T"
join dept "D"
on "T".deptno = "D".deptno
join salgrade "S"
on "T".sal between "S".losal and "S".hisal
order by "T".sal
6. 内连接总复习
1. emp(14行8列)、dept(5行3列)、salgrade三个表
2. select * from emp, dept //70行11列
等价于:select * from dept, emp
等价于:select *
from dept
join emp
on 1 = 1
3. select * from emp, dept where 1=1 //70行11列,where中写过滤条件
select * from emp, dept where empno = 7369 //5行
select * from emp, dept where emp.empno = 10 //5行的倍数
select * from emp, dept where dept,deptno = 10 //14行
4. select * from emp, dept
where dept.deptno = 10
等价于-------------
select *
from emp
join dept
on 1 = 1 //连接条件
where dept.deptno = 10 //过滤条件
5. 查询的顺序:
select top .....
from A
join B
on ....
join C
on ....
where ....
group by ....
having ....
order by ....
外连接
左外连接:用左表的每一行分别和右表所有行进行连接,如果没有匹配行,这行的左边为左表内容,右边全部为null
select * from "E"
left join dept "D"
on E.deptno = D.deptno
实际意义:返回一个事物及其该事物的相关信息,如果该事物没有相关信息,则输出null
例子:productStrocks货物库存表,orderform订单表,pID产品编号
select productStocks.*, orderform.*
from productStocks
left join orderform
on productStocks.pID = orderform.pID
实际意义:返回仓库中现存货物的信息及该货物的订单信息,如果该货物没有订单信息,该货物的订单信息处输出为null
———
有学生表(学号,姓名、所在系)和选课表(学号,课程号,成绩),查询没选课的学生和所在系
select 姓名,所在系
from 学生表 a
left join 选课表 b
on a.学号=b.学号
where a.学号 is null
分析:要学生表的全部,即选课表为左外链接,a里的学号不可能是NULL
完全连接和交叉连接
完全连接
select * from productStocks
full join orderform
on productStocks.pID = orderform.pID
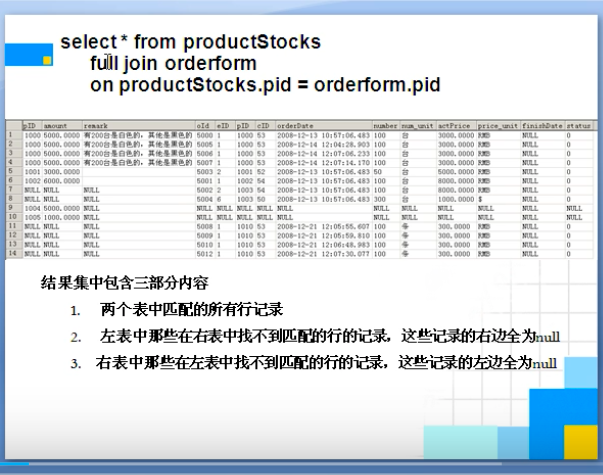
交叉连接:产生的是一个笛卡尔积
select * from temp cross join dept
等价于
select * from temp, dept
自链接
定义:一张表自己和自己连接起来查询数据
例子:不用聚合函数,求薪水最高的员工信息
使用聚合函数:
select * from emp
where sal = (select max(sal) from emp)
不用:
select "E1".empno
from emp "E1"
join emp "E2"
where "E1".sal < "E2".sal
//意味着左边最大的工资,在右边找不到匹配
//(因为要求必须比右边工资小)
//查出来的empno一定不包含工资最大的那个人,用distinct把员工编号empno去重
//把查出来的都排除掉,就得到了最高工资:
select * from emp
where empno not in(
select "E1".empno
from emp "E1"
join emp "E2"
where "E1".sal < "E2".sal
}
联合连接
定义:表和表直接的数据以纵向的方式连接在一起。(以前讲的连接都是以横向方式连接)
例子:输出每个员工的姓名、工资、上司的姓名
用第一张表的上司编号和第二张表的员工编号连接
select "E1".ename, "E1".sal, "E2".ename "上司的姓名"
from emp "E1"
join emp "E2"
on "E1".mgr = "E2".empno //用第一张表的上司编号和第二张表的员工编号连接
如果上司为空,需要员工的姓名和工资,上司姓名为已是最大老板,就要用联合连接
select "E1".ename, "E1".sal, "E2".ename "上司的姓名"
from emp "E1"
join emp "E2"
on "E1".mgr = "E2".empno
union
select ename, sal, '已是最大老板' from emp where mgr is null
把两个表的数据连到一起
要引导学生思考,把结论得出来
每天进步一点,你很快就可以超过别人了
如果你写的东西,你自己都不想看,那别人又怎么会愿意看呢?















 5794
5794











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









