







一、从"猫"解析词向量与向量数据库的技术关联
1. 概念演进路径
猫科生物 → 词向量表征 → 向量数据库体系
通过这个直观案例,我们将揭示自然语言处理中特征向量化的核心原理与向量数据库的实践价值。
2. 生物特征识别启示
养猫爱好者或熟悉猫咪的人,能够快速识别不同品种的猫科动物。这种认知能力源于人类大脑自动进行的多维度特征解析:
- 形态特征:体态轮廓(暹罗猫的流线型 vs 布偶猫的蓬松感)
- 面部结构:耳部形状(折耳猫的折叠耳 vs 缅因猫的尖耳)
- 毛发特征:毛长与纹理(波斯猫的长绒毛 vs 美国短毛猫的短密毛)
- 斑纹样式:色块分布(三花猫的拼色 vs 狸花猫的条纹)
接下来我们通过对猫咪不同维度的提取以及组合来看一下实际效果
▍资料推荐
2.1 品种维度
2.2 体型维度
如果我们使用一个水平轴来表示 体型大小 这个特征,这些不同品种的猫将落在不同的坐标点上,这样就可以通过体型的大小区分出一些品种,如下: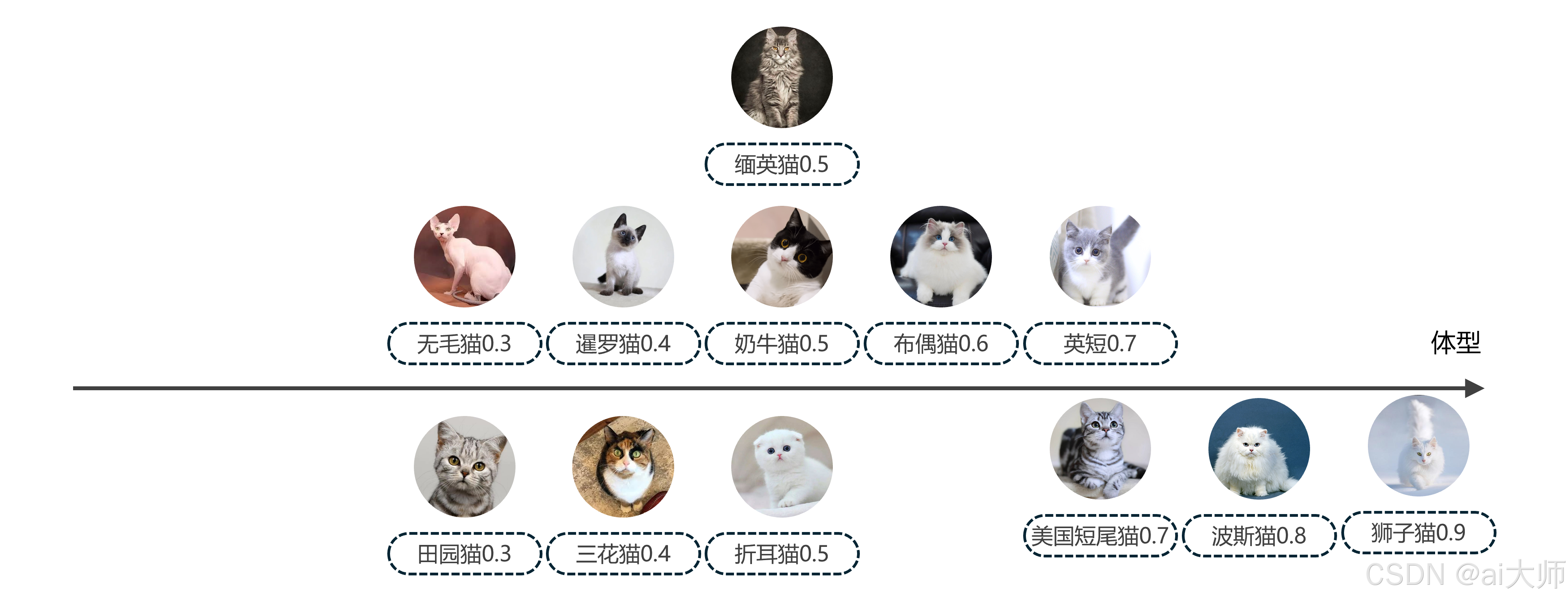
2.3 毛发维度
如果仅仅靠体型一个特征,依旧会有很多品种的猫特征相近,比如 缅英猫、奶牛猫 和 折耳猫 就非常接近,所以我们继续添加多一个特征,比如毛发的长短,继续建立一个毛发的垂直轴,这样子就可以区分出更多品种。
2.4 腿的长短维度
现在每个品种的猫就可以表示为一个二维的坐标点,但是哪怕有两个特征,仍然会有一些品种无法区分。
所以我们需要从更多的角度来观察,例如 腿的长短,这个时候在建立一个 腿的长短 的 z轴,又有更多的品种被区分出来,现在每个品种的猫就可以表示为一个三维的坐标点,如下: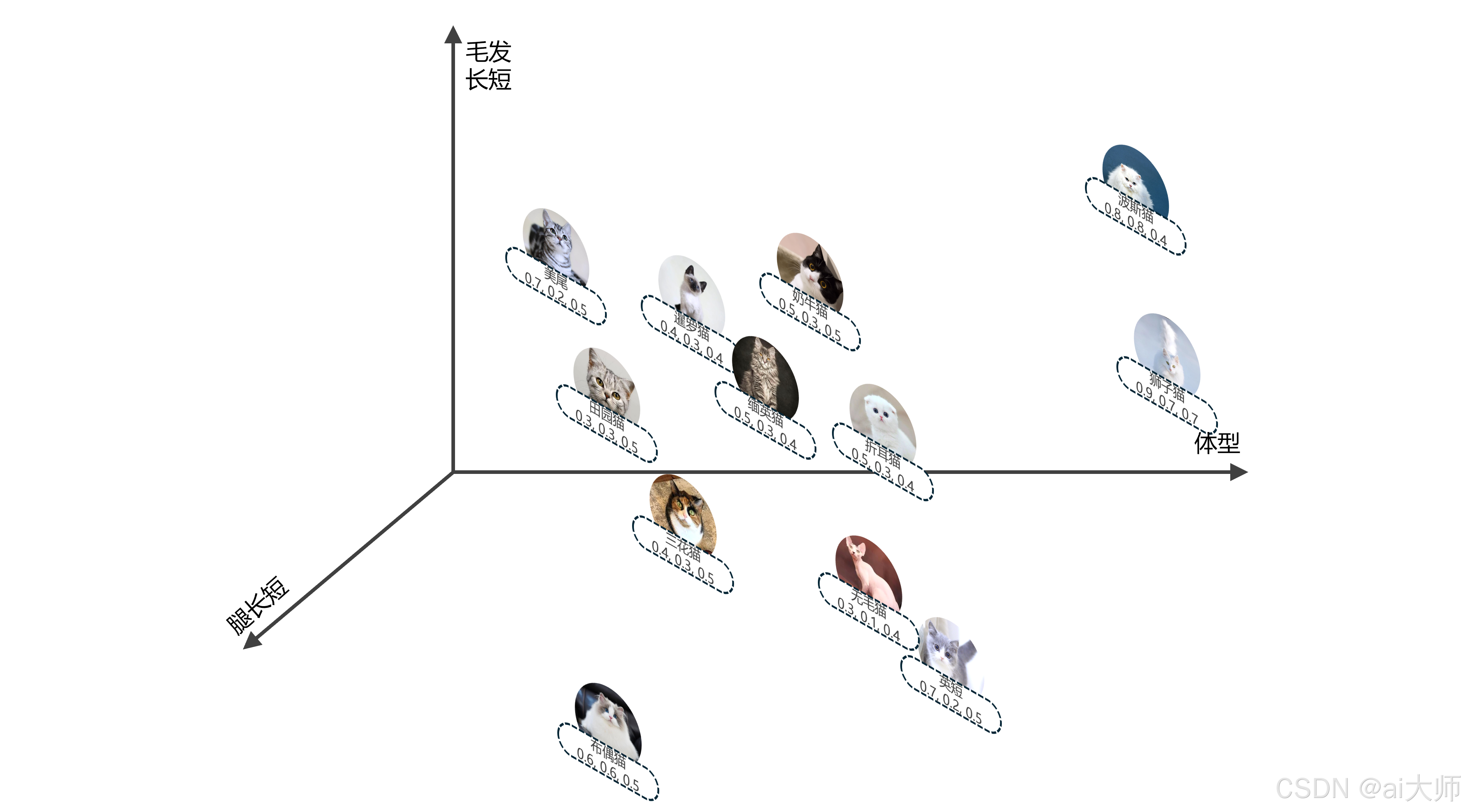
2.4 其他可能的维度及数值转换
如果这个时候还想引入更多的特征进行区分,比如:眼睛大小、尾巴长短、毛发颜色、声音大小、耳朵形状 等等,虽然在坐标图上没法展示出来,但是我们却可以很轻松地将这些特征使用数值的方式展示出来,例如下方:
1. 暹罗猫: (0.4, 0.3, 0.4, 0.5, 0.3, 0.4, 0.5, ...)
2. 英国短毛猫: (0.7, 0.2, 0.5, 0.5, 0.5, 0.5, 0.5, ...)
3. 缅甸猫: (0.5, 0.3, 0.4, 0.5, 0.3, 0.4, 0.5, ...)
4. 波斯猫: (0.8, 0.8, 0.4, 0.8, 0.7, 0.4, 0.6, ...)
5. 布偶猫: (0.7, 0.6, 0.5, 0.8, 0.5, 0.4, 0.5, ...)
6. 无毛猫: (0.6, 0.1, 0.4, 0.5, 0.3, 0.4, 0.5, ...)
7. 中华田园猫: (0.5, 0.3, 0.5, 0.5, 0.5, 0.4, 0.5, ...)
8. 折耳猫: (0.6, 0.3, 0.4, 0.5, 0.3, 0.4, 0.7, ...)
9. 三花猫: (0.5, 0.3, 0.5, 0.5, 0.5, 0.5, 0.5, ...)
10. 美国短毛猫: (0.7, 0.2, 0.5, 0.5, 0.5, 0.5, 0.5, ...)
11. 狮子猫: (0.9, 0.7, 0.7, 0.8, 0.7, 0.8, 0.5, ...)
12. 奶牛猫: (0.6, 0.3, 0.5, 0.5, 0.5, 0.4, 0.5, ...)
2.5 总结
当记录的特征足够大,维度足够大,区分的程度也会越高,当看到一只猫,只需要将它转换成对应的 多维坐标数据/向量,就可以很轻松地找到这只猫的分类归属,而且不仅仅是猫,几乎所有的事物都可以使用这一套方式进行表达。
所以一个字、一个词、一句话、一篇文本、甚至一张图片都可以用这样一个 多维坐标数据,亦或者说 向量 记录对应的特征,而将 文本 转换为记录特征的 向量 就可以被称为词向量。
▍资料推荐
3. 技术映射关系
上述生物特征识别机制,与NLP领域中的词向量技术存在深度关联:
- 特征向量化:将词语映射为高维向量(如
Word2Vec、BERT模型) - 语义空间构建:通过向量距离衡量语义相关性
- 向量数据库:实现海量向量的高效存储与最近邻搜索
这种特征工程思维,正是现代语义搜索、智能推荐等AI系统的底层支撑技术。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









