







零基础也能懂!手把手教你计算大模型部署资源与输出速度
本文用最通俗易懂的方式,帮你搞懂大模型部署需要多少显存、生成速度怎么计算。看完就能自己估算部署需求!
一、如何计算大模型的「饭量」(GPU显存需求)
1.1 推理需要多少显存?
就像手机APP需要内存才能运行,大模型需要显存才能工作。显存需求主要看三个部分:
🎒 模型大小(占大头)
- 计算公式:模型参数数量 × 精度(单位:字节)
- 精度对照表:
精度类型 字节数 常见场景 FP32(全精度) 4字节 专业训练 FP16/bf16 2字节 常用推理 INT8 1字节 手机端推理 INT4 0.5字节 超轻量推理
举个栗子🌰:
32B参数模型用FP16精度
32,000,000,000参数 × 2字节 = 64,000,000,000字节 ≈ 64GB显存
资料推荐
📦 KV缓存(加速法宝)
- 作用:记住之前生成的内容,避免重复计算
- 计算公式:
2 × 批次大小 × 序列长度 × 层数 × 隐藏层大小 × 精度
参数哪里找:模型说明文档里都有标注,一般在 Huggingface 或者 Ollama 上都可以看到关于模型参数量的说明,比如下图
🧠 激活内存(思考空间)
- 作用:存储思考过程的中间结果
- 计算公式:
批次大小 × 序列长度 × 隐藏大小 × (34 + 5×序列长度×注意力头数 ÷ 隐藏大小)
批次大小、序列长度 、层数、隐藏大小、精度这些参数听起来比较绕口,如果没有预训练的经验理解起来比较困难,不过只要记住,这些参数也会参与到推理显存的计算,并且这里的大部分参数都可以在模型的信息/说明文档中找到。
例如下方是 QwQ-32B 模型对应的相关信息:

💡 快速估算技巧
总显存 ≈ 模型大小 × 1.2(留20%余量)
1.2 训练需要多少显存?
训练就像做菜需要更多锅碗瓢盆,显存需求是推理的4-6倍!
| 组件 | 说明 | 每参数占用 |
|---|---|---|
| 模型参数 | 菜谱本身 | 4字节 |
| 优化器状态 | 调料用量 | 8字节 |
| 梯度 | 调整方向 | 4字节 |
| 激活值 | 烹饪步骤 | 8字节 |
快速公式:训练显存 ≈ 推理显存 × 5
1.3 补充
附加的组件导致每个模型的参数需要大约 12~20 字节的额外 GPU 内存,简化公式如下:
训练总内存 ≈ 模型大小 +(12~20字节) * 可训练参数数量
≈ 模型大小 +(3~ 5) (4字节 模型参数)
≈ 模型大小 +(3~ 5) 模型大小
≈(4~6倍) 模型大小
≈(4~ 6倍)* 推理内存
至此我们就可以大概估算出部署一个 LLM 大概需要多少显存才能正常运行,当然实际因为各种部署的优化(例如使用vLLM),实际的数值可能会适当减少或者增加,如果觉得计算过程不好记忆,也可以参考下文中的工具进行在线计算。
二、生成速度怎么算?(Token生成速度)
2.1 关键术语表
| 术语 | 解释 | 类比 |
|---|---|---|
| TTFT(首Token延迟) | 第一个字出现的时间 | 烧水时间 |
| TPOT(后续Token速度) | 后面每个字的生成速度 | 煮饺子速度 |
| TPS(每秒生成数) | 整体输出速度 | 出餐速度 |
资料推荐
2.2 速度计算公式
理论速度 = GPU算力 × 利用率 ÷ 计算量
计算步骤:
- 查显卡算力(常见显卡算力表见附录)
- 算模型计算量:
计算量 = 2 × 模型参数 × 输入Token数 - 代入公式:
生成时间 = 计算量 ÷ (显卡数量 × 单卡算力 × 利用率) - GPU利用率计算:

举个栗子🌰:
用10张A100(312 TFLOPS)运行32B模型,GPU利用率为 46.2% ,输入1000Token
计算量 = 2 × 32B × 1000 = 64,000,000,000,000次运算
时间 = 64E12 ÷ (10 × 312E12 × 0.5) ≈ 0.041秒/Token
公式如下:
2.4 加速小技巧
- KV缓存:像备忘录一样记录已生成内容
- 量化压缩:降低精度换取速度(效果好比手机省电模式)
- 分批处理:同时处理多个请求
三、实战工具推荐
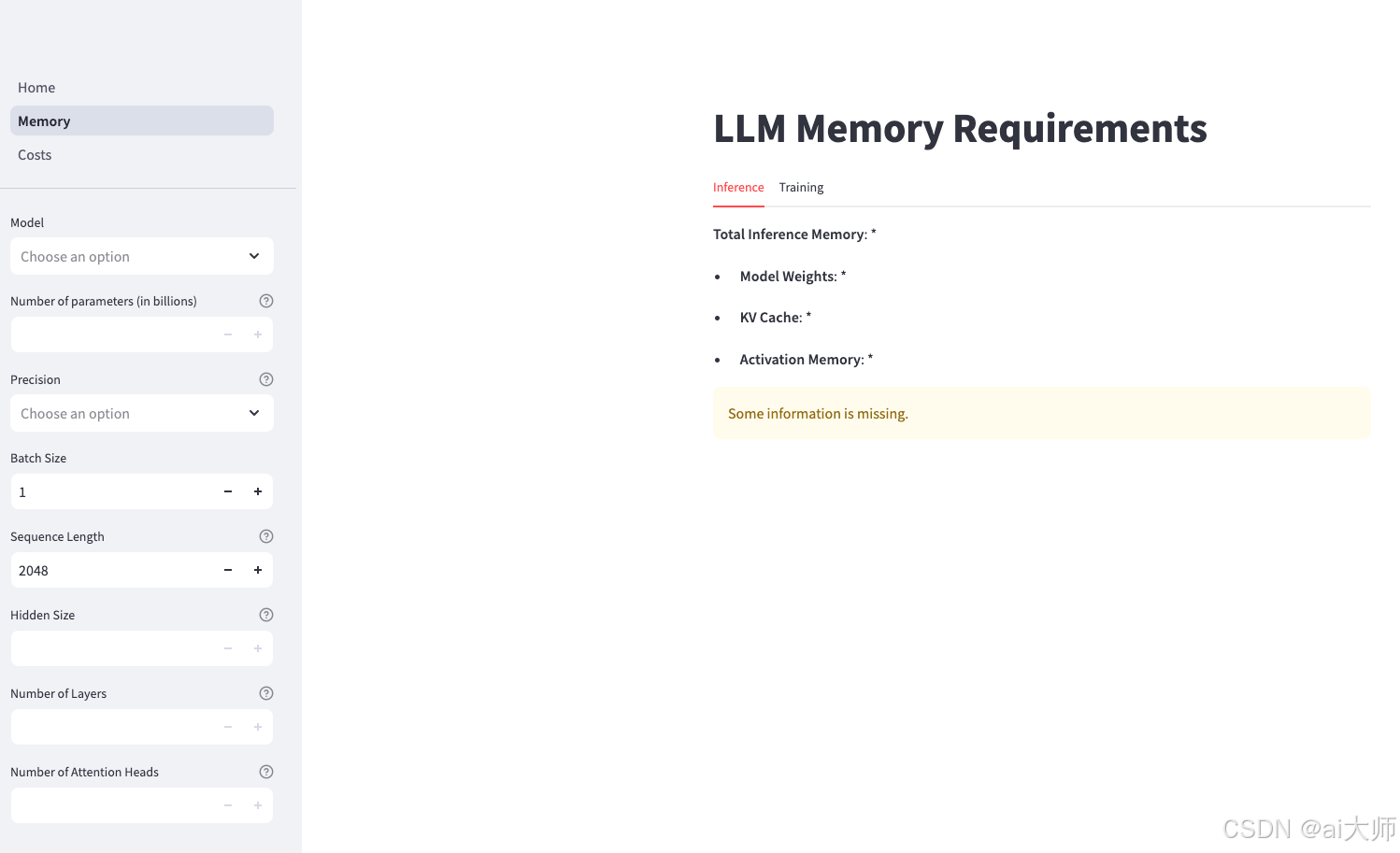
- 在线计算器:LLM Memory Calculator
- 显存优化工具:vLLM、HuggingFace PEFT
- 速度测试工具:LM Evaluation Harness
资料推荐
附录:常见显卡性能表
| 型号 | 算力 | 显存 | 带宽 | 功耗 |
|---|---|---|---|---|
| 昆仑芯 R200 | FP32: 32 TOPS FP16: 128 TOPS INT8: 256 TOPS | 16GB | 512GB/S | 150W |
| H800 | FP32: 67 TFLOPS FP16: 1979 TFLOPS INT8: 3958 TOPS | 80GB HBM3 | 2TB/S | 300-350W |
| V100 | FP32: 15.7 TFLOPS FP16: 125 TFLOPS INT8: 250 TOPS | 16GB HBM2 | 900GB/s | 300W |
| A100 | FP32: 19.5 TFLOPS FP16: 312 TFLOPS INT8: 624 TOPS | 40GB HBM2 | 1.6TB/S | 400W |
| A10 | FP32: 31.25 TFLOPS FP16: 125/250 TFLOPS INT8: 250/500 TOPS | 24GB GDDR6 | 600GB/s | 150W |
| TPU V4 | INT8: 275 TOPS | 32GB | 6.4TB/S | 262W |
| TPU V3 | INT8: 123 TOPS | 32GB | 6.4TB/S | 262W |
| TPU V2 | INT8: 32 TOPS | 32GB | 6.4TB/S | 262W |
| P4 | FP32: 5.5 TFLOPS FP16: 22.1 TFLOPS INT8: 22.1 TOPS | 8GB GDDR5 | 192GB/S | 75W |
| T4 | FP32: 8.1 TFLOPS FP16: 65 TFLOPS INT8: 130 TOPS | 16GB GDDR5 | 320GB/s | 70W |
小提示:实际部署时记得留20%-30%显存余量,就像手机不能把内存用满一样哦!

















 752
752

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









