







01. Weaviate 介绍
Weaviate 是一个完全用 Go 语言构建的开源向量数据库,具备强大的数据存储与检索功能。为了满足不同用户和用例的需求,Weaviate 提供了多种部署方式:
- Weaviate 云:利用 Weaviate 官方的云服务,支持数据复制、零停机更新和无缝扩展,非常适合评估、开发和生产环境。
- Docker 部署:通过 Docker 容器进行 Weaviate 向量数据库的部署,适用于评估和开发场景。
- K8s 部署:在 Kubernetes 环境中部署 Weaviate 向量数据库,适合用于开发和生产场景。
- 嵌入式 Weaviate:基于本地文件的 Weaviate 向量数据库构建方式,适用于评估场景。但嵌入式 Weaviate 仅支持 Linux 和 macOS 系统,不支持 Windows。
Weaviate 与 Pinecone/TCVectorDB 一样,具有集合的概念。在 Weaviate 中,集合类似于传统关系型数据库中的表,负责管理特定类型的数据/数据对象。使用 Weaviate 的流程相当简单:
- 创建并部署 Weaviate 数据库(通过 Weaviate 云或 Docker 部署)。
- 安装 Python 客户端或 LangChain 集成包。
- 连接 Weaviate(可以是本地连接或云端连接)。
- 创建数据集/集合(可以通过代码或可视化管理界面创建)。在 Weaviate 中,集合名称必须以大写字母开头,并且只能包含字母、数字和下划线,这与 Python 的类名规范非常相似。
- 添加数据/向量。
- 执行相似性搜索或带过滤器的相似性搜索。
参考资料:
02. Weaviate 云服务
Weaviate 官方为所有注册登录的账号提供了无限量的 Weaviate 云服务(免费账号每个实例使用时间最大为 14 天,付费账户不限),通过邮箱注册登录 Weaviate 后,找到后台管理系统的 Clusters(集群) 即可快速创建 Weaviate 向量数据库实例。
- Weaviate 后台管理面板:https://console.weaviate.cloud/dashboard
- 模型列表页面:https://yibuapi.com/pricing
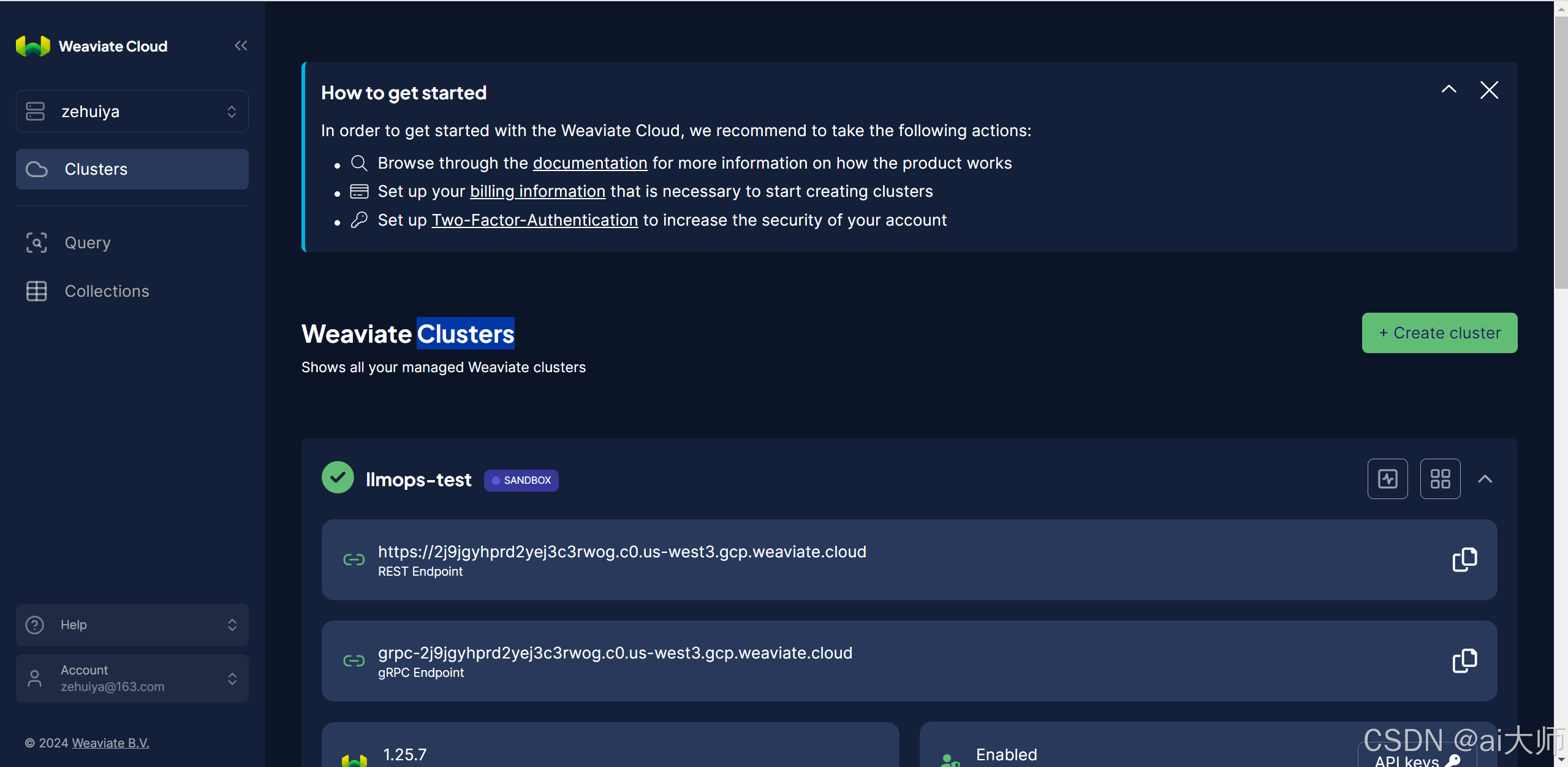
创建好 Weaviate 云服务器集群后,平台提供了 REST 和 gRPC 两种链接方式的地址与 API 秘钥,在客户端中即可快速连接到云服务。
03. Docker 部署 Weaviate 向量数据库
在 Docker 上部署 Weaviate 向量数据库非常简单,如果使用默认值,则不需要 docker-compose.yml 文件来运行镜像(适用于开发场景),安装好 Docker 之后,执行如下命令:
docker run -d --name weaviate-dev -p 8080:8080 -p 50051:50051 cr.weaviate.io/semitechnologies/weaviate:1.24.20
上述的命令就会快速创建一个叫 weaviate-dev 的容器并在后台运行,该容器暴露了两个端口,8080 和 50051,其中 8080 端口为 REST 接口连接端口、50051 为 gRPC 服务连接端口。
除此之外,使用 Docker 部署的 Weaviate 向量数据库服务,还有以下几个常见命令:
# 启动 weaviate 服务
docker start weaviate
# 关闭 weaviate 服务
docker stop weaviate
# 移除 weaviate 容器
docker rm weaviate-dev
# 查看当前 docker 容器所有镜像
docker images
# 移除 weaviate 镜像
docker rmi cr.weaviate.io/semitechnologies/weaviate
# 查看当前运行的 docker 服务
docker ps
# 查看所有 docker 容器(涵盖启动和未启动)
docker ps -a

















 6823
6823

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









