







最近在学习storm,将这段时间的收获总价一下,以后有新的理解再来修改,大家也可以参考一下,有错误欢迎指出,共同进步
其实不太会将理论,但是这个不讲理论对代码的理解有点困难,所以还是写了一些理论
网上copy来的图片,storm的现实模型
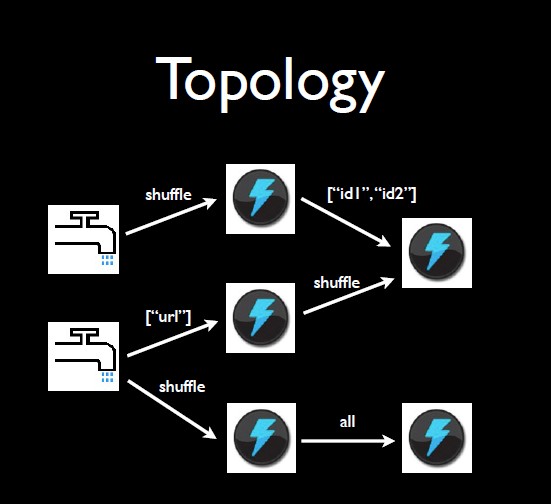
spout: 图中的水龙头,将数据发射出来
tuple: 图中水龙头发射出来的每一个小水滴
stream: tuple的集合,同一个stream的tuple有同样的stream
bolt: 水流的接受者,接受spout中发射的tuple,也可以发射tuple,发射出的tuple和之前的tuple在同一个stream中,也可以只接受不发射
topology:将spout,bolt整合起来的拓扑图,可以定义spout,bolt的并行度,以及spout以怎样的方式发送到bolt,图中spout先以shuffle的方式发送到bolt,然后bolt产生新的tuple以shuffle或者别的方式发送到下一个bolt
storm的基本模型工作模型


在storm中有两种节点:运行Nimbus的主节点和运行supervisor的工作节点,一个storm的集群是有一个主节点和多个工作节点组成的,主节点和工作节点都是无状态的(只有固定的工作流程,没有数据),所有的数据都保存在zookeeper中,下面会仔细的讲解。正是因为都是无状态的,所以在nimbus和supervisor故障时可以快速的恢复,此时只需要到zookeeper上面取到故障前的数据,则可以继续运行。
图中讲解了nimbus的主要功能:负责在集群中分发代码,对节点分配任务,并监视主机故障。nimbus会根据任务数,均匀的分配任务,每一个工作节点上面的任务数大致是一致的。nimbus通过zookeeper对supervisor和worker做心跳检测,如果supervisor故障则重新分配任务,如果worker故障则在别的supervisor中重启worker
supervisor的主要功能:每个工作节点运行Supervisor守护进程,负责监听工作节点上已经分配的主机作业,决定启动和停止Nimbus已经分配的工作进程。
supervisor会定时从zookeeper获取拓补信息topologies、任务分配信息assignments及各类心跳信息,以此为依据进行任务分配。
在supervisor同步时,会根据新的任务分配情况来启动新的worker或者关闭旧的worker并进行负载均衡。supervisor通过LocalState来获取worker的心跳检测,如果故障则先重启,重启失败则nimbus会通过zookeeper来获取消息,在别的supervisor中重启worker
worker的主要功能:具体处理Spout/Bolt逻辑的进程,根据提交的拓扑中conf.setNumWorkers(3);定义分配每个拓扑对应的worker数量,Storm会在每个Worker上均匀分配任务,worker会在zookeeper中获取到自己的任务并执行,一个Worker只能执行一个topology,但是可以执行其中的多个任务线程,一个worker有多个executor,一个task可以有多个executor去执行,默认为一个。默认一个task对应一个executor对应一个spout/bolt,都可以设置 设置并行度是设置的线程数
当nimbus死亡时
如果立即重启不会影响集群,因为nimbus是无状态的。
在nimbus死亡时,无法提交新的topology和分发任务,如果此时worker死亡,supervisor重启失败,那么worker就无法重启,也就是说如果nimbus死亡,worker也同时都死亡,那么集群将不可用,这是一个单点故障。
当supervisor死亡时
如果立即重启则不会影响集群,supervisor是无状态的。supervisor在zookeeper上面建立的是临时节点,当supervisor死亡时会自动断开连接,nimbus通过zookeeper获得消息,nimbus会将分配到该supervisor的任务(监控worker的任务)发送到别的工作节点。
当仅有Worker进程死亡时,其主机上的Supervisor会尝试重启Worker进程,如果连续重启都失败,当超过一定的失败次数之后,无法发送心跳信息到Nimbus,Nimbus会在其他主机上重启该Worke。
举个栗子:现在我们有4个worker 2个工作节点node,一般每一个node上面是有两个worker的,此时node1上面的Supervisor死亡,连接断开,此时node1上面的worker死亡,因为Supervisor已经死亡,无法重启worker,那么nimbus将会在别的工作节点(node2)重启worker,那么此时node1上面就只有一个worker,node2上面有3个,此时我们重启node1上面的Supervisor,那么Supervisor会自动去恢复worker,修复成功则node2上面的新的worker消失,每一个node上面依旧是两个worker。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









