









从表示方式到代表解决方案
文章转自公众号老刘说NLP
我们从今天起,得换个写法,回归到实际场景业务,谈谈一些解决方案的话题。
最近琢磨的事情,就是现在很多文档场景,其实本质上都是做的数字化的过程,核心是从不可编辑到可编辑,比如常见的表格解析、文档转markdown、docx等。
今天,我们来看看一个比较有趣的话题,这其实是RAG中的一些图表的解析方案,讲讲数值图表的解析以及流程图的解析。
一些很有趣的思路,供大家一起参考。
一、先说数值图表的解析
而进一步的,其实,文档还是会有流程图、柱状图等数值图表,也有一些其他图片。
其中,对于柱状图等数值图,目前已经有了很多将柱状图转为底层json_dict的方案,比如onechart(https://arxiv.org/pdf/2404.09987)、unichart(https://arxiv.org/pdf/2305.14761)等。其核心是通过构造<数值图表, json_dict>的输入输出对,然后丢入多模态模型进行sft微调。
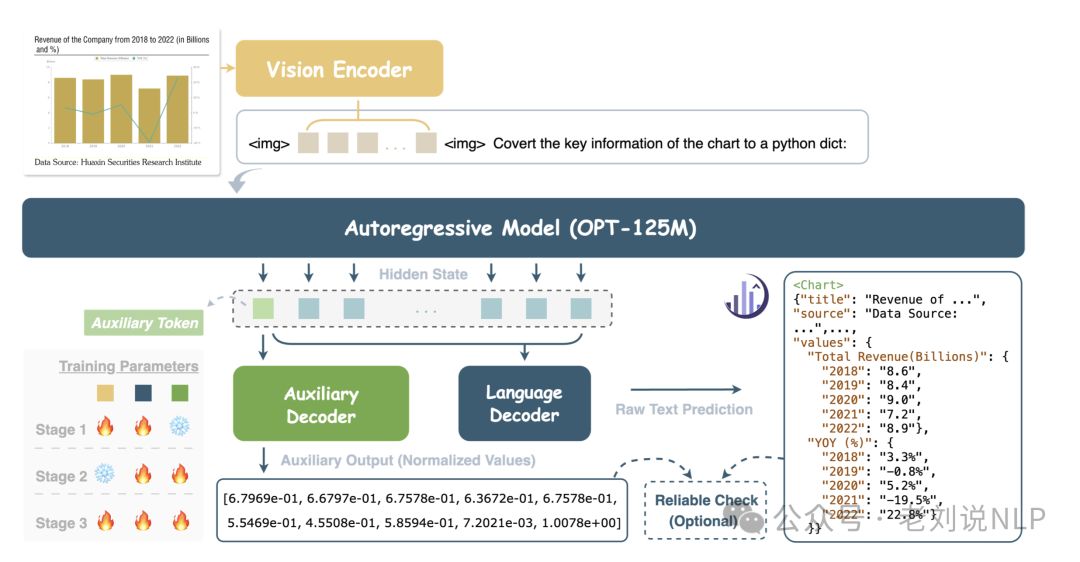
关键点是这个微调数据的生成,主要是靠反向渲染(通过生成json_dict数据(例如让chatgpt生成,或者自定义模版生成,数据的表示也很有趣,主要是使用json_dict来表示x轴、y轴以及对应的数值列表,以及对应的类型信息,比如饼图、折线图等),然后送入matplotlib、echarts或者pyecharts进行渲染。
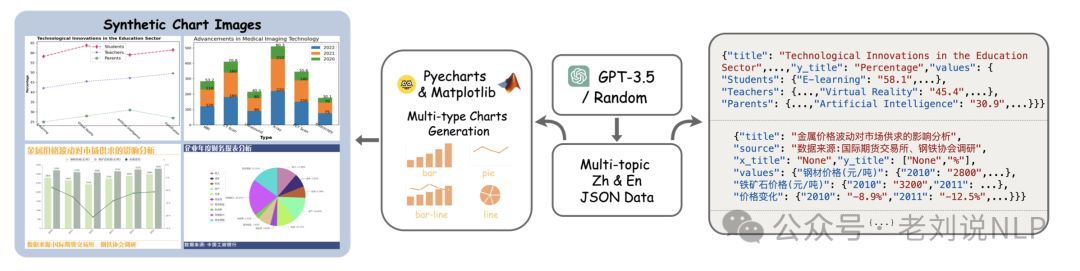
所以,这种思路,其实就是在拟合数据集,很容易因为数据的多样性不足,表现并不稳定,很容易出现幻觉。将这些数据转写之后,可以再进行分析,以及类型转换等。
二、再看流程图的解析
而对于流程图,流程图(FlowChart)是描述我们进行某一项活动所遵循顺序的一种图示方法,能通过图形符号形象的表示解决问题的步骤和程序。
调研了一圈,其实做的人并不多,总结起来,就是几个核心问题。
1、flowchart如何表示问题
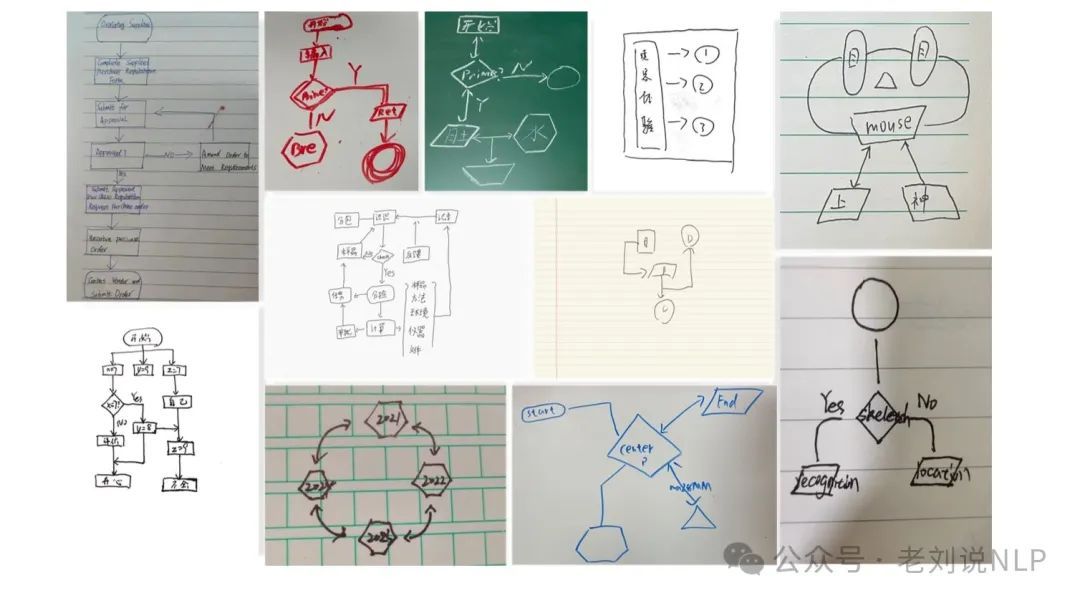
flowchart其实有很多种,如使用bing搜索,能找到很多不同的flowchart图像,如下:
如果要进行呈现,则有不同的表示语法。
例如,使用mermaid(https://mermaid.nodejs.cn/syntax/flowchart.html)表示流程图,例如如下语法可以表示订单处理流程。
flowchart LRA[下单] --> B{库存检查}
B – 有货 --> C[支付]
B – 无货 --> D[提示缺货]
C --> E{支付成功?}
E – 是 --> F[发货]
E – 否 --> G[支付失败]
G --> A
渲染之后为:

也可以使用UML(https://www.visual-paradigm.com/cn/guide/uml-unified-modeling-language/what-is-uml/,https://www.w3cschool.cn/uml_tutorial/uml_tutorial-kty628y9.html)表示流程图,UML是统一建模语言的简称,它是一种由一整套图表组成的标准化建模语言。

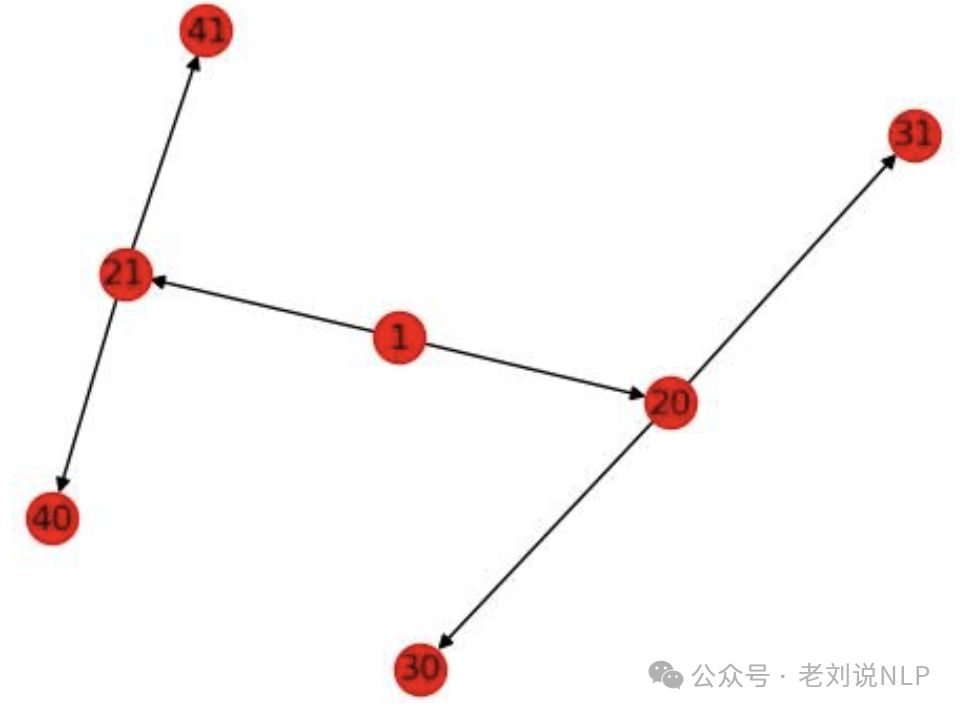
也可以使用networkx来表示,专门绘制图的,表示的是Graph的形式。
import networkx as nximport matplotlib.pyplot as plt
data_dict = {
1:[{ 'left':20, 'right':21}],
20:[{ 'left':30, 'right':31}],
21:[{ 'left':40, 'right':41}],
30:[],
31:[],
40:[],
41:[]
}
G = nx.DiGraph()
# step 1: add edges
for key in data_dict:
print(key)
for source in data_dict[key]:
if 'left' in source:
print( 'left [%d]' % ( source[ 'left']))
if source[ 'left'] in data_dict:
G.add_edge(key, source[ 'left'])
if 'right' in source:
print( 'right [%d]' % ( source[ 'right']))
if source[ 'right'] in data_dict:
G.add_edge(key, source[ 'right'])
# nx.draw_networkx(G)
# plt.show()
print(G.edges())
效果图如下:
当然,也可以使用知识图谱三元组的表示形式,<头节点,关系,尾节点>,每个流程图的环节,都可以用若干个三元组构成。
另一种,就是用视觉的方式进行表示,标注对应的boundingbox以及位置信息等。
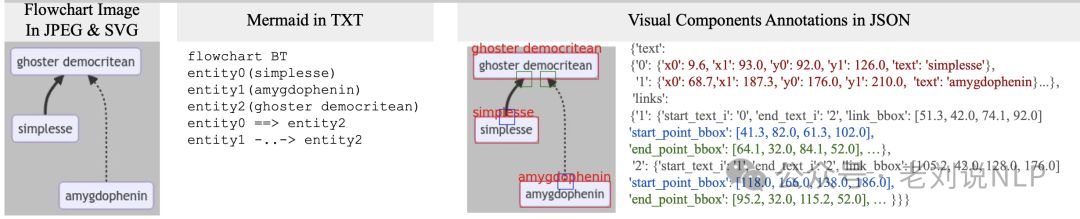
2、如何解析流程图
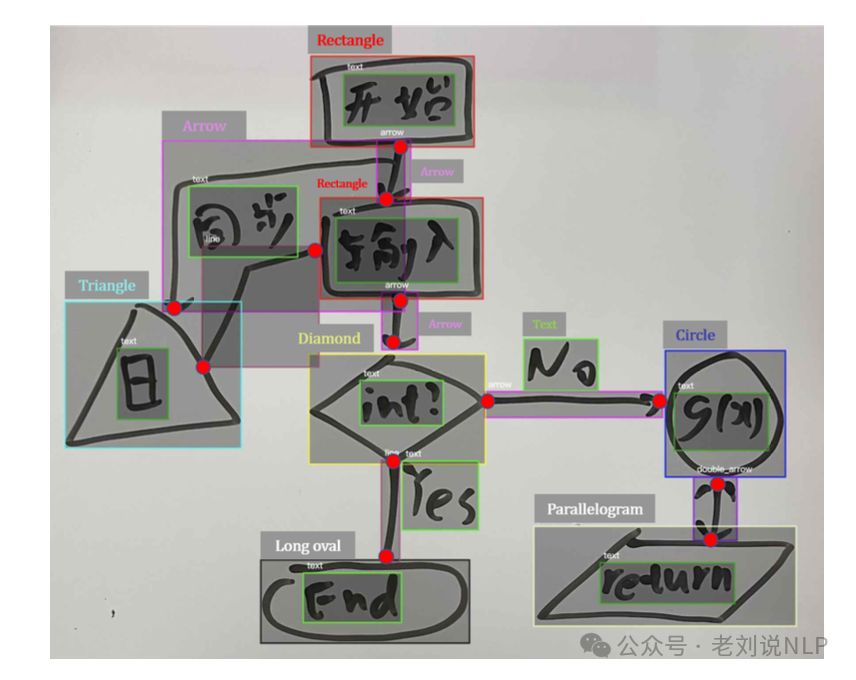
只要确定了流程图的表示方法,如何要对流程图进行解析,那么就只需要将转为对应的表示形式就行。其中的核心难点是流程图中节点的识别、线的识别以及ocr识别,前面的节点识别还好,用目标检测即可,ocr也好,也有现成的,主要是线的识别【当然,解析的程度还可以进一步分为内容、形状、颜色以及布局等,这些则是另外的实现策略了】。
所以,目前有两个主流方法。一个是多模态的方法,一个是传统深度学习CV处理的方案。
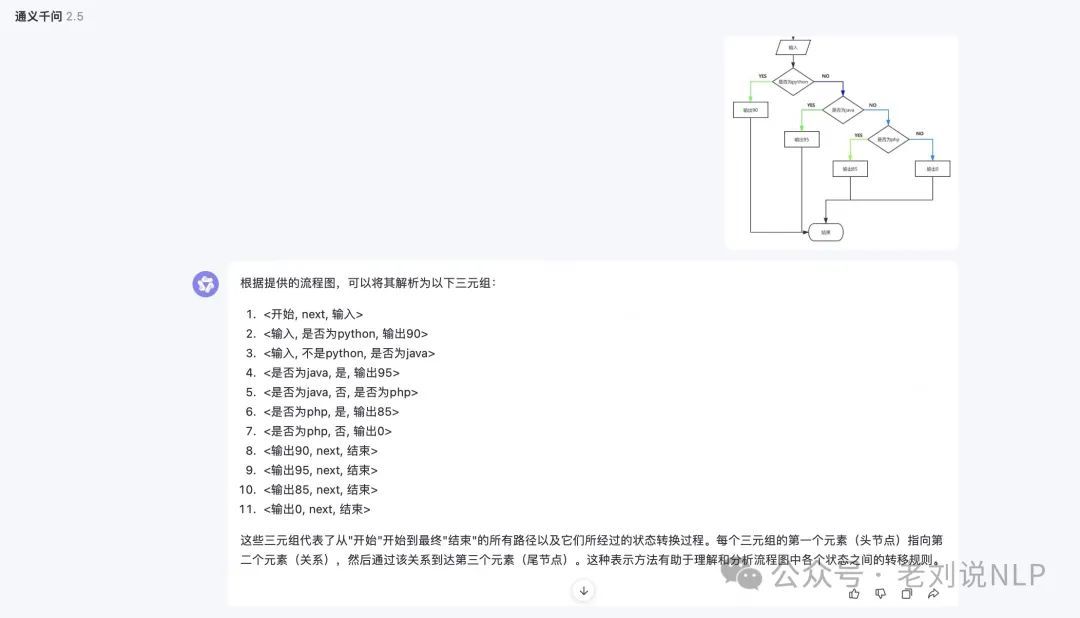
多模态方法上,和图表类解析一致,做成端到端的方案,如 《FlowLearn: Evaluating Large Vision-Language Models on Flowchart Understanding》(https://arxiv.org/pdf/2407.05183)

例如,在qwen-vl上,直接将其解析为三元组的表示,说明其实有理解能力的。
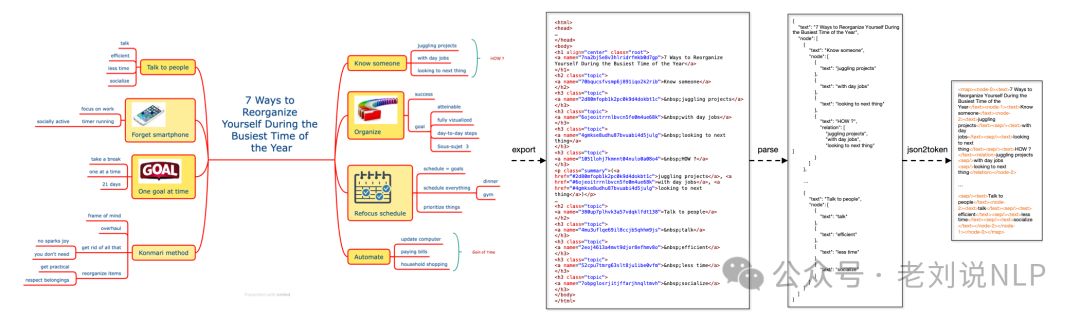
同理,流程图跟思维导图其实也很像,如《MindBench: A Comprehensive Benchmark for Mind Map Structure Recognition and Analysis》(https://arxiv.org/abs/2407.02842),使用markdown来表示流程图:
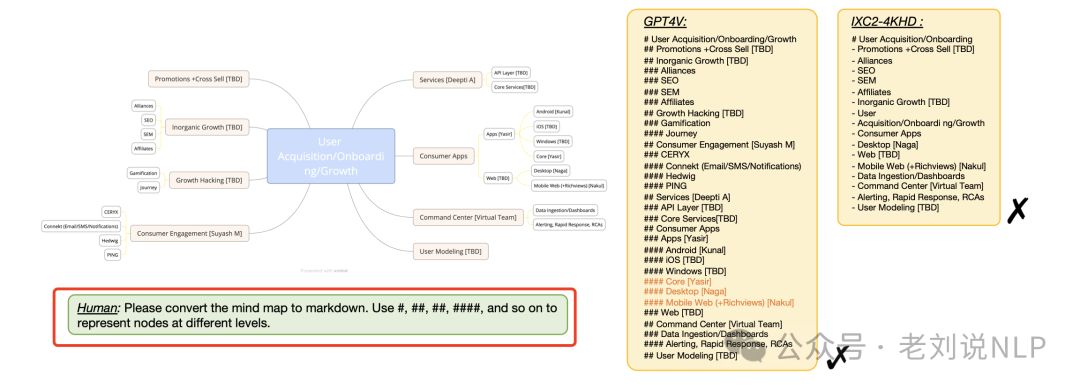
可以直接使用“ Please convert the mind map to markdown. Use #, ##, ##, ####, and so on to represent nodes at different levels.“的prompt来识别:
另一个是使用传统cv目标分割的方案去做,代表的方案是《Flowmind2Digital: The First Comprehensive Flowmind Recognition and Conversion Approach》(https://arxiv.org/abs/2401.03742),讲了讲如何将手绘的流程图和思维导图(统称为flowmind)自动转换为数字格式。
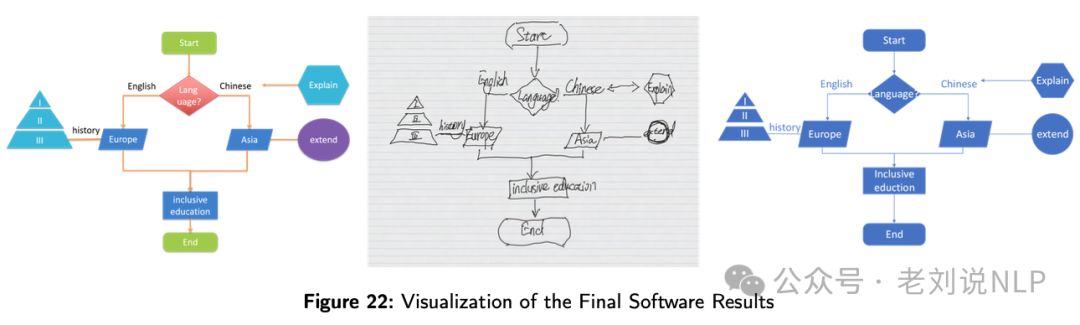
Flowmind2digital方法包括两个主要部分:对象和关键点检测,以及后处理。
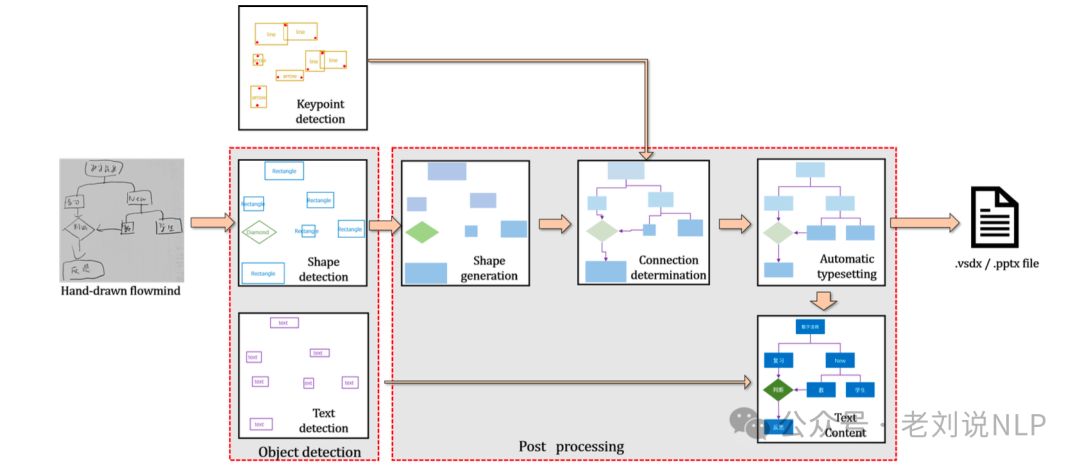
首先是对象和关键点检测,使用Mask-RCNN进行对象检测,能够同时检测形状、关键点和文本。Mask-RCNN的两阶段架构包括区域提议网络(RPN)和感兴趣区域网络(ROI),分别负责生成区域提议和分类、细化边界框位置。
其次后处理,包括形状生成、连接确定、文本内容提取和自动排版。
在形状生成阶段,使用python-pptx库与Microsoft PowerPoint交互,或使用win32com库与Visio交互,将检测到的关键点坐标转换为相应的形状。
在连接确定阶段,通过计算连接器和形状之间的欧几里得距离,确定连接器的连接点(这个比较关键)。
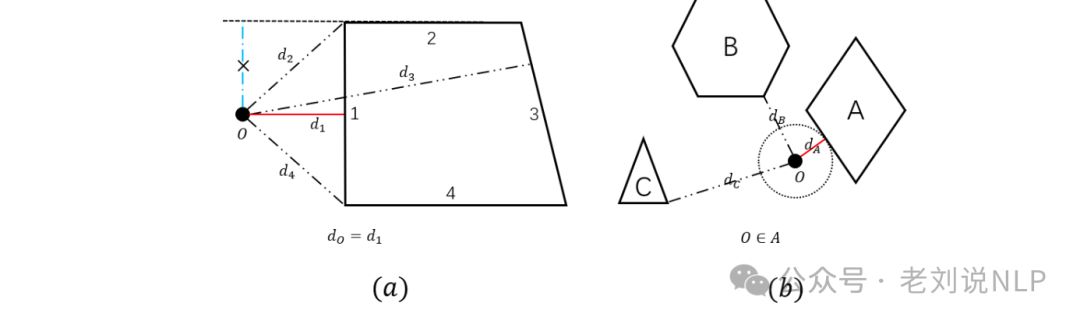
按照原文的叙述,假设检测到的形状在边界框中设定为标准化方向(具有水平基线),该过程首先计算每个形状上的候选点,参考PPT和Visio形状上的可连接锚点。其次,对于每个连接点关键点,它识别所有形状上最近的候选点。对于多边形,它计算关键点到每条边的垂直距离(如图13a所示的𝑑₁, 𝑑₂)。需要注意的是,如果垂直线的落脚点位于边的延长线上,则选择从关键点到边端点的最短距离作为最短距离(如图的𝑑₁₃, 𝑑₂₄)。对于非多边形,它根据PPT和Visio的连接规则在形状上确定𝑛个候选点,并指定关键点只能与这些点相连。例如,圆的候选点为上、下、左、右、左上、左下、右上和右下。最后,对于每个关键点,选择具有最近候选点的形状作为连接对象。
在文本内容提取阶段,使用OCR软件提取文本框内的具体内容,在自动排版阶段,采用基于Canopy和K-means算法的两阶段聚类模型,调整形状的大小和位置,生成最终的输出文件。
最后,这个工作还做了一个数据集和模型,对应的数据集、模型在:https://github.com/cai-jianfeng/flowmind2digital
总结
本文主要围绕文档中的图标解析这一工作作了介绍,分别介绍了先说数值图表的解析、流程图表解析两个任务的一些代表方案。
整个大的潮流,其实都是往多模态的方向做,但受限于图片分辨率、OCR效果以及多样性,所以,但多模态大模型已经有了初步这样的能力。
参考文献
1、https://arxiv.org/pdf/2404.09987
2、https://arxiv.org/abs/2401.03742
3、https://arxiv.org/pdf/2407.05183

















 308
308

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









