







Oprofile Introduction
内容概要
* oprofile 介绍
* .oprofile 安装及 Linux 内核编译
* oprofile 使用
* oprofile 实例演示及性能分析
* gprof 介绍
* Kprof 分析
* gcov 简介
一、 oprofile 介绍
oprofile 是 Linux 平台上,类似 INTEL VTune 的一个功能强大的性能分析工具。 其支持两种采样 (sampling) 方式:基于事件的采样 (event based) 和基于时间的采样 (time based) 。
基于事件的采样是 oprofile 只记录特定事件(比如 L2 cache miss )的发生次数,当达到用户设定的定值时 oprofile 就记录一下(采一个样)。这种方式需要 CPU 内部有性能计数器 (performace counter) 。现代 CPU 内部一般都有性能计数器;
基于时间的采样是 oprofile 借助 OS 时钟中断的机制,每个时钟中断 oprofile 都会记录一次 ( 采一次样)。引入的目的在于,提供对没有性能计数器 CPU 的支持。其精度相对于基于事件的采样要低。因为要借助 Os 时钟中断的支持,对禁用中断的代码 oprofile 不能对其进行分析。
oprofile 在 Linux 上分两部分,一个是内核模块 (oprofile.ko) ,一个为用户空间的守护进程 (oprofiled) 。前者负责访问性能计数器或者注册基于时间采样的函数 ( 使用 register_timer_hook 注册之,使时钟中断处理程序最后执行 profile_tick 时可以访问之 ) ,并采样置于内核的缓冲区内。后者在后台运行,负责从内核空间收集数据,写入文件。
二、 oprofile 安装及 Linux 内核编译
I. Oprofile 安装
Oprofile 包含在 Linux 2.6 版本的内核中,是用于 Linux 的若干种评测和性能监控工具中的一种。 也可从官方网站下载源码进行编译安装;具体安装步骤:
1. ./configure --with-kernel-support
注:在编译过程中,这一步出现的问题是:
( 1 )缺少 libiberty.h 头文件 ; ( 2 )缺少 popt ;
libiberty.h 头文件在 binutils-devel package 中,需要下载这个包进行安装;也可通过新立德 进行安装。可以用 sudo apt-get install binutil-dev 进行包安装。 Popt 存在 libpopt-devel package 中,同样需要进行下载安装; sudo apt-get install libpopt-dev;
2. make
3. make install
oprofile 安装完成后会生成以下工具集:
/usr/bin/oprofiled 守护进程
/usr/bin/opcontrol 控制前端,负责控制与用户交互,用得最多
/usr/bin/opannotate 根据搜集到的数据,在源码或者汇编层面上注释并呈现给用户
/usr/bin/opreport 生成二进制镜像或符号的概览
/usr/bin/ophelp 列出 oprofile 支持的事件
/usr/bin/opgprof 生成 gprof 格式的剖析数据
opstack : 产生调用图 profile ,但要求 x86/2.6 的平台,并且 linux2.6 安装了 call-graph patch
oparchive : 将所有的原始数据文件收集打包,可以到另一台机器上进行分析。
op_import : 将采样的数据库文件从另一种 abi 转化成本地格式。
运行 oprofile 需要 root 权限,因为它要加载 profile 模块,启动 oprofiled 后台程序等。所以在运行之前, 就需要切换到 root 。
II. Linux 内核编译
由于 oprofile 是可对内核进行评测和性能监控的工具,所以需要有内核支持。但是在 ubuntu 下面并没有内核源码,所以需要下载本机对应版本的内核源码,进行编译安装;
编译新内核的步骤如下:
( 1 )将下载的内核放在 /usr/src 目录下;进行解压: tar -jxvf linux-source-2.6.27.tar.bz2;
(2 )接下来对内核进行配置: make menuconfig(or make xconfig), 我选择使用此命令;
在进行配置过程中 ,General Setup 中的 Local version - append to kernel release 是可以自己 定制自己喜欢的内核名字 ; Load an Alternate Configuration File 此选项可以引用系统中的配置文件; Save an Alternate Configuration File 是将重新配置的 .config 文件进行保存。 在配置之前,可以用以下命令进行清除。 Make clean :可以把以前编译的文件进行清除;
Make mrproper : 可以清除以前的配置文件;建议新手不用;最好对以前的 .config 文件进行配置。
.config 文件是内核源码中自带的 ./usr/src/linux-source-2.6.27/arch/x86/configs 下
面的 config 文件再根据 menuconfig 中的选项进行裁减后获得的最终的 config 文件。
(3) make 进行内核编译,编译完成后会在 /boot 目录下生成几个重要的文件; vmlinuz-2.6.27 、 System.map 等;其中 config 文件生成在 /linux-source-2.6.27 目录下,需要拷贝到 /boot 目录下面。
( 4 ) make modules_install 安装配置中选定的模块。
( 5 ) make install
( 6 )检查是否生成 initrd 镜像文件,在 ubuntu 下并没有生成,需要在 /boot 下面使用命令:
mkinitramfs -o initrd.img.2.6.27.18 生成镜像文件。
( 7 )在 /boot/grub 下面编辑 menu.lst 文件,按照格式将新内核信息进行添加;只有在此处对新内核 添加,系统启动后才会被引导进入新内核。如果配置符合系统要求,按照这个顺序就可以编译一个新内核了。
三、 oprofile 使用
oprofile 要在 root 权限下使用:
a. 初始化
opcontrol --init
该命令会加载 oprofile.ko 模块, mount oprofilefs 成功后会在 /dev/oprofile/ 目录下导出些文件和目录如: cpu_type, dump, enable, pointer_size, stats.
b. 配置
1. 首先,配置 OProfile 是否应该监视内核。这是在启动 OProfile 前需要的配置选项。
以及对计数事件和样本计数的设置,计数的 CPU 模式(用户态、核心态)是系统默认项;
如果 oprofile 监视评测内核自身:
opcontrol –vmlinux=/src/urc/linux-source-2.6.27/vmlinux
如果 oprofile 不用监视评测内核:
opcontrol --no-vmlinux .
在此体系结构 Family10h 中默认的配置为:
opcontrol –event=CPU_CLK_UNHALTED:100000
如果配置守护进程写入文件的方式,用以下命令:
opcontrol --separate=<choice>
<choice> 可以是以下之一:
none — 不要分离档案(默认)
library — 为库生成每个应用程序的档案
kernel — 为内核和内核模块生成每个应用程序的档案
all — 为库生成每个应用程序的档案,为内核和内核模块生成每个应用程序的档案
注意问题:
( 1 ) oprofile 可以在此进行事件设置;
通过 opcontrol --list-events 命令可以查看此结构中支持的事件;
通过 opcontrol --event=L2_CACHE_MISS:500 --event=L1_DTLB_MISS_AND_L2_DTLB_HIT:500
--event=......... 命令来进行事件的设置;
此命令 --event 参数必须依次给出,无论有多少个,不可分行,切记!
通过 opcontrol –status 命令可以查看自己已经配置的事件;
( 2 )对于每一次测试过程中,如果需要进行事件的重新设置,就必须重启 daemon, 它是
一个守护进程。也就是说,收集数据完成后,要用 --shutdown 命令来停止 daemon, 而不是 -- stop( 此命令只是停止 profiling) ,这样再次进行— start 命令就可以使用新的事件设置;
( 3 )一次评测结束后,旧的 profiling data 还是存在的,用— reset 或者— save 命令来清理或者保存数据;
c. 启动
opcontrol --start
d. 运行待分析之程序
gcc -o wls wls.c ;生成 wls.o 文件; ./wls
e. 取出数据
opcontrol –dump
数据被写进 /var/lib/oprofile/samples /oprofiled.log
f. 停止评测
opcontrol --stop
g. 使用 opreport 分析结果
opreport -l ./wls
根据设置的事件进行评测,将评测的结果一一显示出来。
h. 使用 opannotate 分析结果
如果对源码进行分析,可以通过 opannotate 工具实现
编译: gcc -g wls.c -o wls
分析: opannotate --source ./wls
总结一下:
-
opcontrol –init 加载模块, mout /dev/oprofile 创建必需的文件和目录
-
opcontrol --no-vmlinux 或者 opcontrol --vmlinux=/boot/vmlinux-`uname -r` 决定是否对 kernel 进行 profiling
-
opcontrol --reset 清楚当前会话中的数据
-
opcontrol --start 开始 profiling
-
./wls 运行应用程序, oprofile 会对它进行 profiling
-
opcontrol --dump 把收集到的数据写入文件
-
opcontrol --stop 停止 profiling
-
opcotrol -h 关闭守护进程 oprofiled
-
opcontrol --shutdown 停止 oprofiled
-
opcontrol --deinit 卸载模块
常用的是 3→7 这几个过程,得到性能数据之后,可以使用 opreport, opstack, opgprof, opannotate几个工具进行分析,我常用的是 opreport, opannotate 进行分析。
四、实例演示
下面以 AMR 的解码源码为例,来分析代码的性能。
首先,要对即将分析的代码进行编译:
(1) 编译源代码的库文件:
在目录 /home/wls/ 应用软件 /AMREngineC_OKI_source/AMRDecEngine 下执行 make 命令; 生成文件: libAMRDecEngine.a 此文件为归档库文件。
( 2 )编译源代码的主文件:
在目录 /home/wls/ 应用软件 /AMREngineC_OKI_source/TestAMRDec/Win32 下执行 make 命令; 生成文件: TestAMR 此文件为可执行文件。
将 TestAMR 复制到上层目录: cp TestAMR ..
执行命令: ./TestAMR AMRDec.par 生成 TestAMRDec.wav
其次,执行 oprofile 的命令并进行相应设置:
root@wls-desktop:~/TestAMRDec# opcontrol --init
root@wls-desktop:~/TestAMRDec# opcontrol --no-vmlinux
root@wls-desktop:~/TestAMRDec# opcontrol --event= CPU_CLK_UNHALTED:5000
--event=DATA_CACHE_MISSES:1000 --event=INSTRUCTION_CACHE_MISSES:1000
--event=MEMORY_REQUESTS:1000
root@wls-desktop:~/TestAMRDec# opcontrol --status
Daemon running: pid 14979
Event 0: CPU_CLK_UNHALTED:5000:0:1:1
Event 1: DATA_CACHE_MISSES:1000:0:1:1
Event 2: INSTRUCTION_CACHE_MISSES:1000:0:1:1
Event 3: MEMORY_REQUESTS:1000:131:1:1
Separate options: none
vmlinux file: none
Image filter: none
Call-graph depth: 0
root@wls-desktop:~/TestAMRDec# opcontrol –start
Using 2.6+ OProfile kernel interface.
Reading module info.
Using log file /var/lib/oprofile/samples/oprofiled.log
Daemon started.
Profiler running.
root@wls-desktop:~/TestAMRDec# ./TestAMR AMRDec.par
===================================================
Audio Length [msec] : 10020
Audio Frames [frame] : 501
Audio Packets [packet] : 501
Decoded Bytes [byte] : 7014
Average Bitrate [kbps] : 5.600
Decoding Time [msec] : 40 (250.500 Times)
===================================================
root@wls-desktop:~/TestAMRDec# opcontrol --dump
root@wls-desktop:~/TestAMRDec# opcontrol --stop
Stopping profiling.
root@wls-desktop:~/TestAMRDec# opreport -l ./TestAMR
数据分析结果如下:
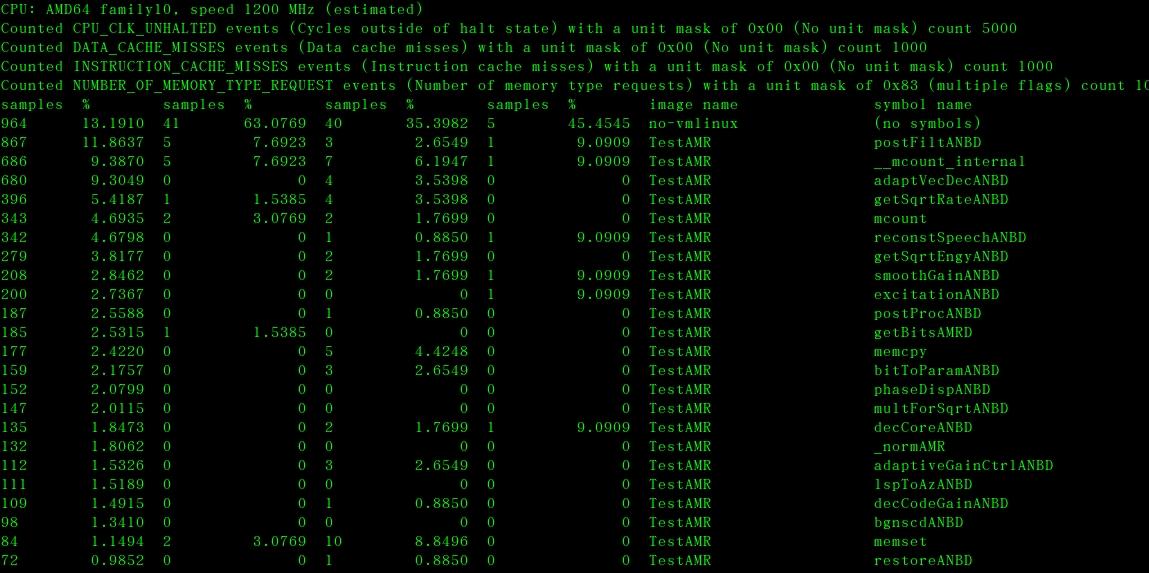
如果设置如下:
root@wls-desktop:~/TestAMRDec# opcontrol –vmlinux=/src/urc/
linux-source-2.6.27/vmlinux
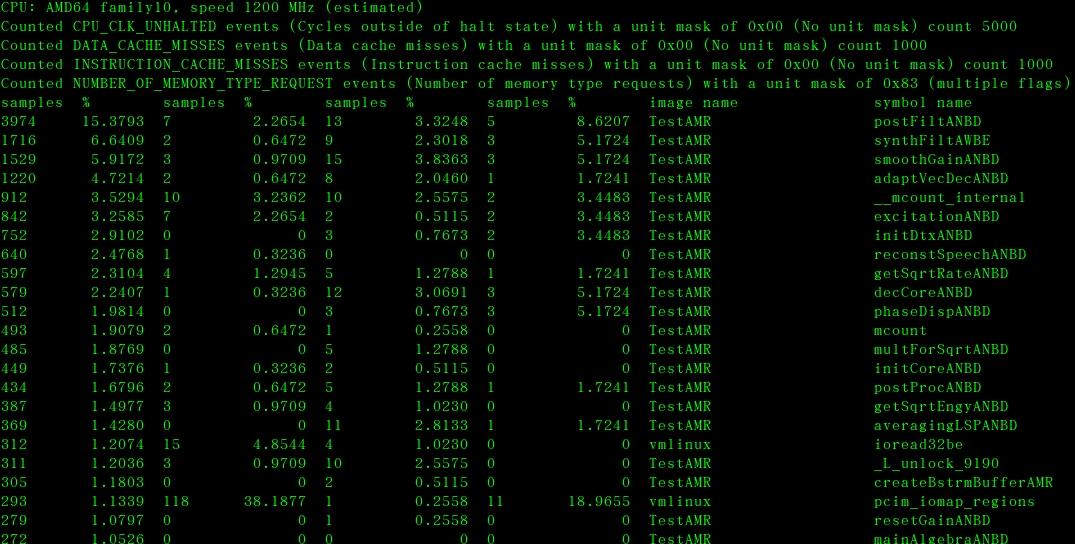
root@wls-desktop:~/TestAMRDec# opcontrol --shutdown
Stopping profiling.
Killing daemon.
root@wls-desktop:~/TestAMRDec# opcontrol --deinit
Daemon not running
Unloading oprofile module
现将 oprofile 用到的各种性能参数在此予以解释:
通过 op_help 或者 opcontrol –list-events 显示出 oprofle
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 593
593











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









