







前言
“花圃记录学习日常”。刚开始走上Python之路,以下都是入门基础内容的一些要点笔记。
一、PyCharm调试
断点一个断点标记了一个代码行,当Pycharm运行到该行代码时会将程序暂时挂起。注意断点会将对应的代码行标记为红色,取消断点的操作也很简单,在同样位置再次单击即可。
debug窗口几个图标分别代表的意思
1.show execution point (F10)显示当前所有断点
2.step over(F8) 单步调试,若函数A内存在子函数a时,不会进入子函数a内执行单步调试,而是把子函数a当作一个整体,一步执行
3.step into(F7) 单步调试,若函数A内存在子函数a时,会进入子函数a内执行单步调试。
4.step into my code(Alt + Shift +F7) 执行下一行但忽略libraries(导入库的语句)
5.force step into(Alt + Shift +F7) 执行下一行忽略lib和构造对象等
6.step out(Shift+F8)当目前执行在子函数a中时,选择该调试操作可以直接跳出子函数a,而不用继续执行子函数a中的剩余代码。并返回上一层函数。
二、文件操作(IO技术)
1.文本文件与二进制文件
可以简单地进行区分,可以用记事本打开的就叫做文本文件,否则像word、图片、音频都是二进制文件,那么文本文件是以“字符”为单位进行存储的,也就是我们看的懂,默认的也是unicode(65536),而二进制文件是以“字节”为单位进行存储的。
2.文件相关操作的模块
IO模块
OS模块
……
创建文件对象open()函数
基本语法格式:open(文件名[,打开方式])。为了减少文件路径“\”的输入可以在文件名前头加 r ,打开方式有以下几种:
r 读模式
w 写模式 没有文件就去创建 有文件擦掉内容重写
a 追加模式 没有文件创建 有文件就在原始的内容后面去追加内容
b 二进制模式
“+”读写模式
b很特殊,如果我的打开方式没有增加b那么我会以“字符”为单位去处理文件,增加了b就会以“字节”方式去处理。
文本文件的写入:
(1)基本文件的写入操作 创建文件对象,写入数据,关闭文件对象【注意一定要通过close的方法去关闭文件,因为我们的程序是通过解释器去执行的,解释器通过操作系统OS去操作硬盘,那么不执行关闭操作,OS会一直将资源文件作为打开的状态】
(2)穿插–常见编码介绍
ASCII码 (美国提出最早的一种给字符编码的方式,是单字节的表示方式,只用到了7位,可以表示128个字符)----ISO8859-1(可以用8位,表示256个字符,兼容ASCII,又称Latin)----GB2312----GBK----GB18030,这条线是兼容的,而且前面两者是属于一个字节表示英文,后面属于两个字节以上表示汉字。
ASCII码 (美国提出最早的一种给字符编码的方式,是单字节的表示方式,只用到了7位,可以表示128个字符)----ISO8859-1(可以用8位,表示256个字符,兼容ASCII,又称Latin)----UTF-8(变长编码,1-4个字节表示字符)
Unicode(定长编码,2个字节表示字符,包括英文,与之前的ASCII,ISO的表示是不同的)
-UTF-8与GB2312----GBK----GB18030是不兼容的,也就是说我们出现乱码的原因就在于编码和解码用的不是一套兼容的体系。
中文乱码问题:windows系统默认的编码是GBK,也就是说我的解释器去让OS操作系统操作文件是打开输入都执行的是GBK的编码,而python默认的是Unicode编码,注意Linux擦欧总系统默认的是UTF-8编码
write():把字符串写入文件中
writelines():把字符串列表写入文件中,要换行的话要自己添加换行符,
(3)close()关闭流要点
打开文件,文件实际上在硬盘上。在之前我们说我们打开之后要在最后关闭我们打开的资源,那么问题就来了,如果程序过程中出现异常了,在open后close之前,出现异常进行不下去关闭不了怎么办,这个时候就要用到我们之前说到的try与except与finally的异常处理结构。
【我们要清楚文件写入到关闭的流程,首先python会为你创建一个文件对象,那么我们要写的内容实际上先到这个对象中,可以这么理解,此时此可还没有写道我们硬盘的文件之上,中见还要经过一个缓冲区,也就是内容先到缓冲区之上,那么这个时候使用flush()函数就会把缓冲区的内容冲进我们的硬盘文件,如果不调用flush而是直接close,仍然会自动调用flush进而在去关闭。】
(4)with语句(又被称作上下文管理器)
可以自动地管理上下文资源
格式:
with open ()as f:
f的操作
文本文件的读取:
read([size]),从文件中读取的size个字符,将结果返回,没有size参数默认读取整个文件
readline()读取一行内容作为结果返回
readlines()每一行作为一个字符串存入列表中,返回列表
示例:
<test_file1.txt>
HuaPu在学
HuaPu1在学
HuaPu2在学
with open("test_file1.txt","r") as f:
lines=f.readlines()
lines=[line.rstrip()+"\t第{}行\n".format(index) for index,line in enumerate(lines)]
pass
with open("test_file1.txt","w") as f:
f.writelines(lines)
pass
输出结果:
<test_file1.txt>
HuaPu在学 第0行
HuaPu1在学 第1行
HuaPu2在学 第2行
【注意】enumerate()函数是创建一个enumerate对象,将列表对应索引和对应内容创建成一个个元组,存储成一个列表。
二进制文件的读写:
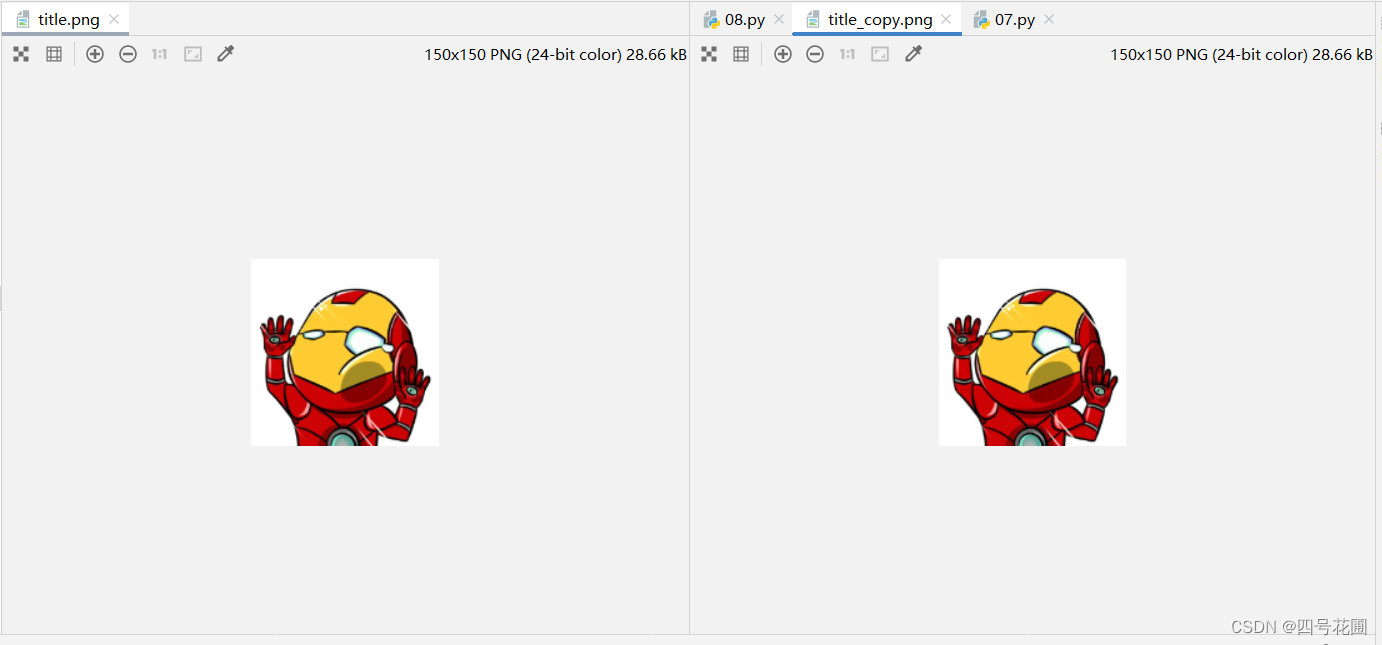
示例(图片copy):
with open("title.png","rb") as f:
with open("title_copy.png","wb") as w:
for line in f.readlines():
w.write(line)
pass
pass
pass
print("copy_done!")
输出结果:
copy_done!
文件对象的常用属性与方法:
之前说的文件的属性(文本、二进制)与方法(read、readline、readlines、write、writelines)不再赘述,介绍没有说明的方法。
seek(offset[,whence]),offset代表的偏移量,whence表示文件指针从哪一个位置开始,默认是0,从文件开头,也可以设置为指针当前位置1,或是文件结尾的位置。
tell()返回文件指针的当前位置
truncate([size])不论指针在什么位置,只保留指针前size个字节的内容吗其余全部删除,如果没有传入size就按照指针当前位置到文件末尾内容全部删除。
with open("test_file1.txt","r") as f:
print("指针的位置:{}".format(f.tell()))
print("读取第一行内容:{}".format(f.readline()))
print("指针当前的位置:{}".format(f.tell()))
print("读取第二行内容:{}".format(f.readline()))
f.seek(0)
print("指针当前的位置:{}".format(f.tell()))
pass
输出结果:
指针的位置:0
读取第一行内容:HuaPu在学 第0行
指针当前的位置:17
读取第二行内容:HuaPu1在学 第1行
指针当前的位置:0
使用pickle序列化:
对象本质上是一个个存储数据的内存块,那么如果我们希望把对象们写入硬盘中存储,就涉及到了”对象的额序列化和反序列化“,这就类似说序列化的将我的对象写入硬盘,反序列化的读取我存进去的对象,但注意写进去是一个对象,读出来内容是一样的,但并不是一个对象。
import pickle
a1="HuaPu在学"
a2=234
a3=[1,2,3,4]
with open("test_file1.dat","wb") as f :
pickle.dump(a1,f)
pickle.dump(a2,f)
pickle.dump(a3,f)
pass
with open("test_file1.dat","rb") as f :
b1 = pickle.load(f)
b2 = pickle.load(f)
b3 = pickle.load(f)
pass
print(b1)
print(b2)
print(b3)
print(id(a1)==id(b1))
输出结果:
HuaPu在学
234
[1, 2, 3, 4]
False
csv文件的操作:
csv文件是一种二维表格的极简方式,是逗号分隔符文本格式,用于数据的交换,Excel文件和数据库数据的导入和导出。
python提供标准库的模块csv,模块提供读取与写入csv文件的对象。``
【注意csv文件中,所有值都是字符串,没有其他类型,不能嵌入图像图表,不能指定单元格的宽高,不能合并单元格,没有多个工作表】
import csv
with open("Some_Info.csv","r") as f:
a_csv=csv.reader(f)
for i in a_csv:
print(i)
pass
pass
with open("Some_Info_1.csv","w") as f:
b_csv=csv.writer(f)
b_csv.writerow(["ID","Name","Age","Salary"])
c_csv=[[10004,"HuaPu4",21,60000],[10005,"HuaPu5",22,80000],[10006,"HuaPu6",23,70000]]
b_csv.writerows(c_csv)
pass
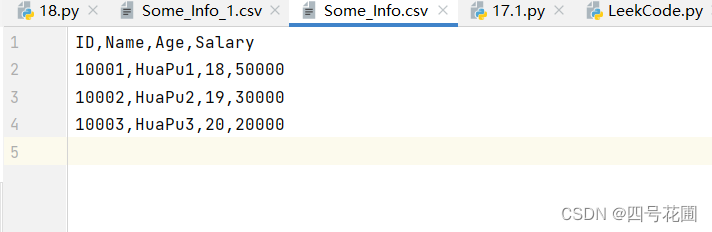
['ID', 'Name', 'Age', 'Salary']
['10001', 'HuaPu1', '18', '50000']
['10002', 'HuaPu2', '19', '30000']
['10003', 'HuaPu3', '20', '20000']
os模块与os.path模块:
os模块可以直接调用系统文件和命令。
import os
# os.system("notepad.exe")
# os.system("ping www.baidu.com")
# os.system("cmd")
os.startfile(r"C:\Program Files\Sublime Text\sublime_text.exe")
结果自行测试
import os
print(os.name) # windows is nt ; Linux\unix is posix
print(os.sep) # windows is \ ; Linux\unix is /
print(repr(os.linesep)) #windows is \r\n ; Linux\unix is \n\
print(os.stat("of.py"))
print(os.getcwd())
os.mkdir("of创建")
os.rmdir("of创建")
os.makedirs("A/B/C")
os.removedirs("A/B/C")
#注意删除只能删除空目录,其中有文件存在就无法删除了
#也就是说C中有文件存在你是不能删除的
os.makedirs(".../A/B/C")
#...表示当前目录上一级目录
os.chdir("c:")
os.mkdir("of创建")

结果自行测试
os.path模块提供了目录相关的操作,路径的判断、路径的拆分、路径的链接、文件夹的遍历。
判断:isabs()是否为绝对路径、isdir()是否为目录、isfile()是否为文件、exists()是否存在,其中都填充path
返回:getsize()返回文件夹的大小、abspath()返回绝对路径、dirname()返回目录的路径
getatime()返回最后访问时间、getmtime()返回最后修改时间、walk()递归方式遍历目录、join()链接多个路径
分割:split()对路径进行分割,以列表的形式返回、splitext()从路径中分割扩展名
os.walk()
walk()递归遍历所有文件和目录
os.walk()返回一个三元素的元组(要列出指定目录的路径、目录下的所有文件夹、目录下的所有文件)
import os
path=os.getcwd()
print(path)
list_files=os.walk(path)
print(list_files)
for dirpath,dirname,filename in list_files:
for dir in dirname:
print(dir,end=" ")
print(os.path.join(dirpath,dir))
pass
for file in filename:
print(file,end=" ")
print(os.path.join(dirpath,file))
pass
pass
D:\Python\mypy01\os
<generator object walk at 0x0000022283FA6A48>
A D:\Python\mypy01\os\A
B D:\Python\mypy01\os\B
C D:\Python\mypy01\os\C
of.py D:\Python\mypy01\os\of.py
__init__.py D:\Python\mypy01\os\A\__init__.py
__init__.py D:\Python\mypy01\os\B\__init__.py
__init__.py D:\Python\mypy01\os\C\__init__.py
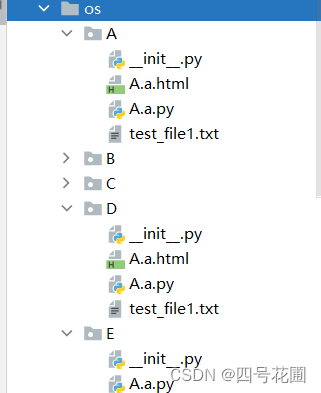
shutil模块(拷贝和压缩):
shutil模块是python标准库提供的模块,作为对于os操作文件或者目录的一个补充。
import shutil
shutil.copyfile(r"test_file1.txt","test_file2.txt")
shutil.copytree("A","D") #这里注意的是只能copy到不存在的文件夹中,如果D已经存在就会报错
shutil.copytree("A","E",ignore=shutil.ignore_patterns("*.txt","*.html")) #最后ignore是把不想拷贝的后缀文件
【注意不要同时运行,尝试哪一个就解开注释即可】
import zipfile
# shutil.make_archive("D/D.d","zip","A")
# # zipfile()更精细
# z1=zipfile.ZipFile("OS.zip","w")
# z1.write("A")
# z1.write("B")
z2=zipfile.ZipFile("OS.zip","r")
z2.extractall("C")
z2.close()
三、递归算法
递归是一种常见的解决问题的办法,把问题逐渐简单化。基本思想就是“自己调用自己”。
递归结构包括两部分:
(1)定义递归头:
如果没有这一部分就会陷入死循环,也就是说是递归结束条件。
(2)递归体:什么时候调用自己。
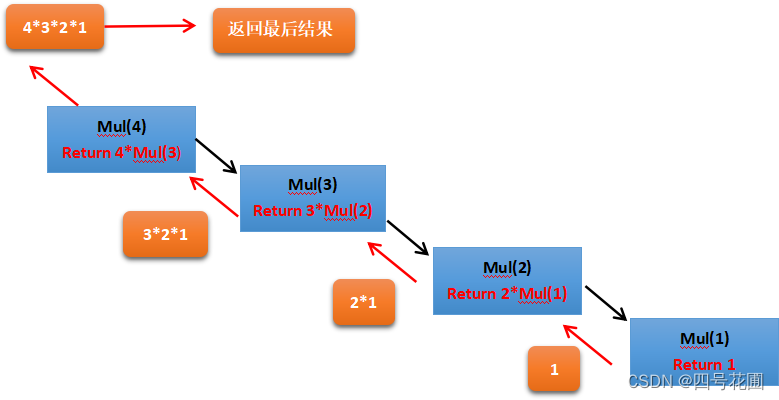
示例:阶乘计算
def mul(num):
if num==1:
return num
else:
return num*mul(num-1)
pass
def mul1(num):
if num==1:
return
result=num*mul(num-1)
return result
print(mul(5))
print(mul1(5))
120
120
我们说一下第一个mul()递归阶乘调用的过程。一开始传入的num数字,我们需要判断,不为1,走下面一条路,为mul(num-1)开辟空间,注意上一级的return并没有结束,只是开辟空间(栈帧)去mul(num-1),逐次这样我们到最后num=1,就会返回num=1,此时返回给上一级mul(2),mul(2)返回给上一级mul(3),依次知道最后到达mul(num),随着返回过程,调用的空间会被回收。
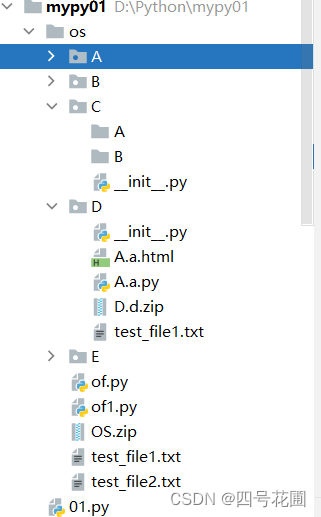
示例:目录树结构
import os
allfiles=[]
def getAllFile(path,level):
childfile= os.listdir(path)
for filename in childfile:
if os.path.isdir(filename):
getAllFile(filename,level+1)
pass
allfiles.append("\t"*level+os.path.join(path,filename))
pass
pass
getAllFile(r"d:/Python/mypy01",0)
for i in allfiles:
print(i)
pass
.idea\.gitignore
.idea\dataSources.local.xml
.idea\encodings.xml
.idea\inspectionProfiles
.idea\misc.xml
.idea\modules.xml
.idea\mypy01.iml
.idea\workspace.xml
d:/Python/mypy01\.idea
d:/Python/mypy01\01.py
d:/Python/mypy01\02.py
d:/Python/mypy01\03.py
d:/Python/mypy01\04.py
d:/Python/mypy01\05.py
d:/Python/mypy01\06.py
d:/Python/mypy01\07.py
d:/Python/mypy01\08.py
d:/Python/mypy01\09.py
d:/Python/mypy01\11.py
d:/Python/mypy01\12.py
d:/Python/mypy01\13.py
d:/Python/mypy01\14.py
d:/Python/mypy01\15.py
d:/Python/mypy01\16.py
d:/Python/mypy01\17.1.py
d:/Python/mypy01\17.py
d:/Python/mypy01\18.py
d:/Python/mypy01\19.py
d:/Python/mypy01\LeekCode.py
os\A
os\B
os\C
os\D
os\E
os\of.py
os\of1.py
os\OS.zip
os\test_file1.txt
os\test_file2.txt
d:/Python/mypy01\os
d:/Python/mypy01\singlelinklist10.py
d:/Python/mypy01\Some_Info.csv
d:/Python/mypy01\Some_Info_1.csv
d:/Python/mypy01\sort.py
d:/Python/mypy01\test_file1.dat
d:/Python/mypy01\test_file1.txt
d:/Python/mypy01\title.png
d:/Python/mypy01\title_copy.png
__pycache__\singlelinklist10.cpython-37.pyc
d:/Python/mypy01\__pycache__
Process finished with exit code 0















 781
781











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









