







RocketMQ 性能优化
调优层次图
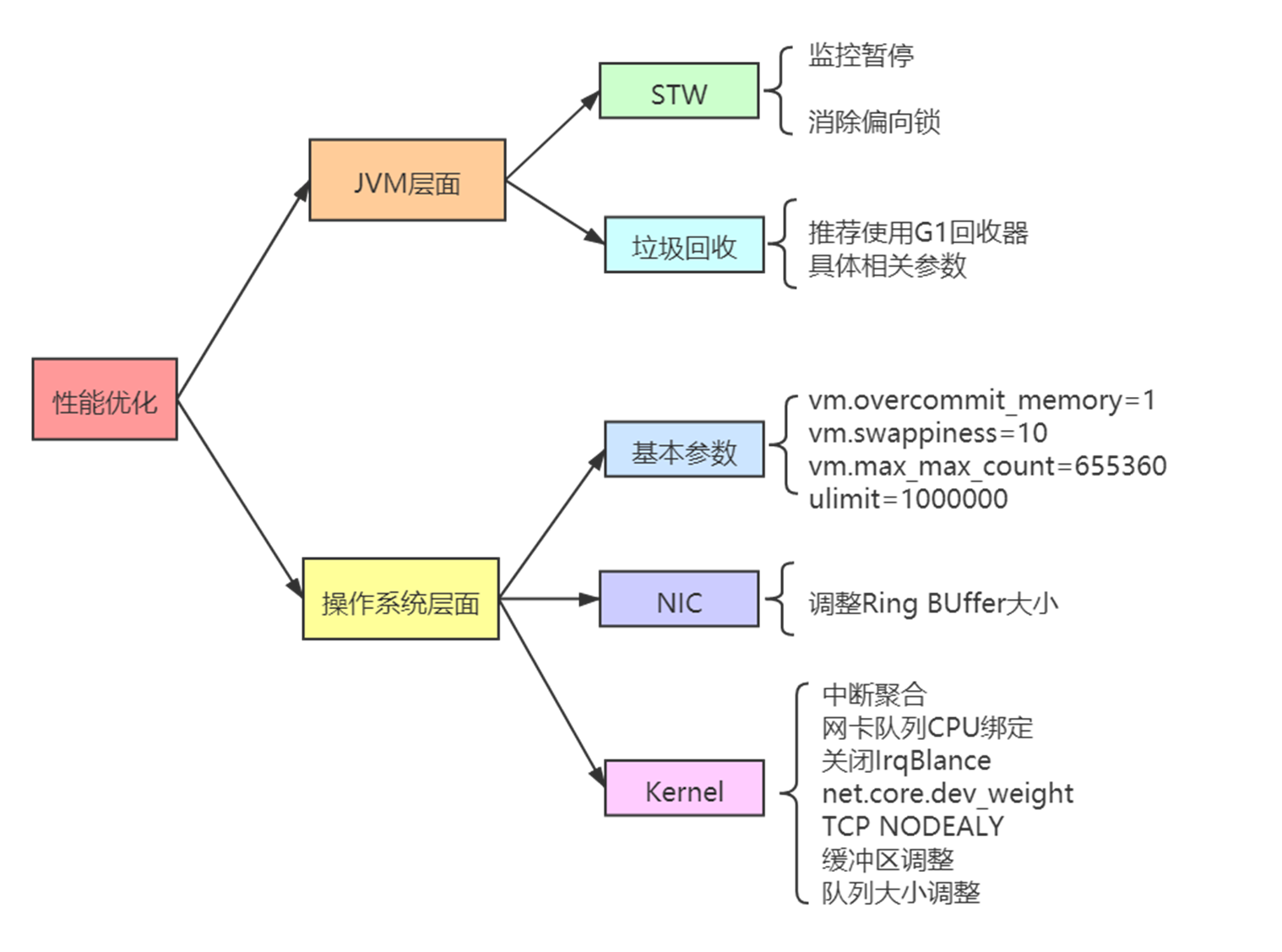
JVM 层面
STW
监控暂停
rocketmq-console(最新源码移动了位置,rocketmq-dashbroad, 下载链接0. RockerMq安装有) 这个是官方提供了一个 WEB 项目,可以查看 rocketmq 数据和执行一些操作。但是这个监控界面又没有权限控制,并且还有一些消耗性能的查询操作,如果要提高性能,建议这个可以暂停。
一般的公司在运维方面会有专门的监控组件,如 zabbix 会做统一处理。
或者是简单的 shell 命令
监控的方式有很多,比如简单点的,我们可以写一个 shell 脚本,监控执行 rocketmqJava 进程的存活状态,如果 rocketmq crash 了,发送告警
消除偏向锁
在 JDK1.8 sync 有偏向锁,但是在 RocketMQ 都是多线程的执行,所以竞争比较激烈,建议把偏向锁取消,以免没有必要的开销。
-XX:-UseBiasedLocking: 禁用偏向锁
垃圾回收
RocketMQ 推荐使用 G1 垃圾回收器。
-Xms8g -Xmx8g -Xmn4g:这个就是很关键的一块参数了,也是重点需要调整的,就是默认的堆大小是 8g 内存,新生代是 4g 内存。如果是内存比较大,比如有 48g 的内存,所以这里完全可以给他们翻几倍,比如给堆内存 20g,其中新生代给 10g,甚至可以更多些,当然要留一些 内存给操作系统来用
-XX:+UseG1GC -XX:G1 HeapRegionSize=16m:这几个参数也是至关重要的,这是选用了 G1 垃圾回收器来做分代回收,对新生代和老年代都是用 G1 来回 收。这里把 G1 的 region 大小设置为了 16m,这个因为机器内存比较多,所以 region 大小可以调大一些给到 16m,不然用 2m 的 region, 会导致 region 数量过多。
-XX:G1ReservePercent=25:这个参数是说,在 G1 管理的老年代里预留 25%的空闲内存,保证新生代对象晋升到老年代的时候有足够空间,避免老年代内存都满了,新生代有对象要进入老年代没有充足内存了。默认值是 10%,略微偏少,这里 RocketMQ 给调大了一些
-XX:initiatingHeapOccupancyPercent= :30:这个参数是说,当堆内存的使用率达到 30%之后就会自动启动 G1 的并发垃圾回收,开始尝试回收一些垃圾对象。默认值是 45%,这里调低了一些,也就是提高了 GC 的频率,但是避免了垃圾对象过多,一次垃圾回收耗时过长的问题
-XX:-OmitStackTraceInFastThrow:这个参数是说,有时候 JVM 会抛弃-些异常堆栈信息,因此这个参数设置之后,就是禁用这个特性,要把完整的异常堆栈信息打印出来。
-XX:+AIwaysPreTouch:这个参数的意思是我们刚开始指定 JVM 用多少内存,不会真正分配给他,会在实际需要使用的时候再分配给他所以使用这个参数之后,就是强制让 JVM 启动的时候直接分配我们指定的内存,不要等到使用内存的时候再分配
-XX:MaxDirectMemorySize=15g:这是说 RocketMQ 里大量用了 NIO 中的 direct buffer,这里限定了 direct buffer 最多申请多少,如果你机器内存比较大,可以适当调大这个值,不了解 direct buffer 是什么。
-XX:-UseLargePages:这个参数的意思是禁用大内存页,某些情况下会导致内存浪费或实例无法启动。默认启用。
操作系统层面
基本参数
vm.overcommit_memory=1
是否允许内存的过量分配
当为 0 的时候,当用户申请内存的时候,内核会去检查是否有这么大的内存空间
当为 1 的时候,内核始终认为,有足够大的内存空间,直到它用完了为止
当为 2 的时候,内核禁止任何形式的过量分配内存
vm.swappiness=10
swappiness=0 仅在内存不足的情况下,当剩余空闲内存低于 vm.min_free_kbytes limit 时,使用交换空间
swappiness=1 内核版本 3.5 及以上、Red Hat 内核版本 2.6.32-303 及以上,进行最少量的交换,而不禁用交换
swappiness=10 当系统存在足够内存时,推荐设置为该值以提高性能
swappiness=60 默认值
swappiness=100 内核将积极的使用交换空间
vm.max_max_count=655360
定义了一个进程能拥有的最多的内存区域,默认为 65536
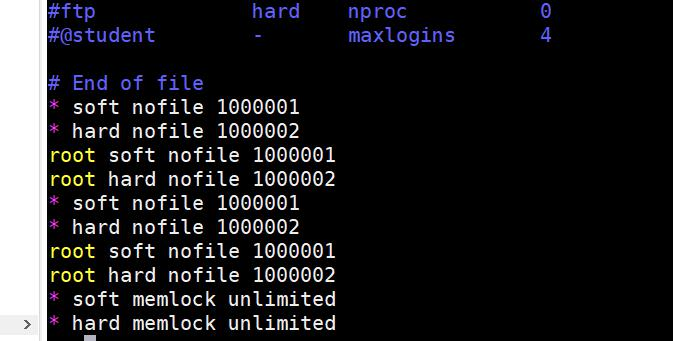
ulimit=1000000
limits.conf 设置用户能打开的最大文件数.
1、查看当前大小
ulimit -a

2、临时修改
ulimit -n 1000000
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ZbLfYf37-1638291143733)(img/rocketmq-note/image-.png)]](https://img-blog.csdnimg.cn/4c893574fccc47e4808fac7d219cb8d4.png)
3、永久修改
vim /etc/security/limits.conf
NIC
一个请求到 RocketMQ 的应用,一般会经过网卡、内核空间、用户空间。
![[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-CCMz1LI5-1638291143735)(img/rocketmq-note/image-.png)]](https://img-blog.csdnimg.cn/aab072c67d224aa5a76085324eeb4896.png)
网卡
网络接口控制器(英语:network interface controller,NIC)
因 Ring Buffer 写满导致丢包的情况很多。当业务流量过大且出现网卡丢包的时候,建议调整 Ring Buffer 的大小,这个大小的设置一定程度上是可以缓解丢包的状况。
Kernel
中断聚合
在中断(IRQ),在操作系统级别,是可以做软中断聚合的优化。什么是中断?
举例,假如你是一位开发同学,和你对口的产品经理一天有 10 个小需求需要让你帮忙来处理。她对你有两种中断方式:
-
第一种:产品经理想到一个需求,就过来找你,和你描述需求细节,然后让你帮你来改
-
第二种:产品经理想到需求后,不来打扰你,等攒够 5 个来找你一次,你集中处理
我们现在不考虑及时性,只考虑你的工作整体效率,你觉得那种方案下你的工作效率会高呢?或者换句话说,你更喜欢哪一种工作状态呢?
很明显,只要你是一个正常的开发,都会觉得第二种方案更好。对人脑来讲,频繁的中断会打乱你的计划,你脑子里刚才刚想到一半技术方案可能也就
废了。当产品经理走了以后,你再想捡起来刚被中断之的工作的时候,很可能得花点时间回忆一会儿才能继续工作。
对于 CPU 来讲也是一样,CPU 要做一件新的事情之前,要加载该进程的地址空间,load 进程代码,读取进程数据,各级别 cache 要慢慢热身。因此如果能适当降低中断的频率,多攒几个包一起发出中断,对提升 CPU 的工作效率是有帮助的。所以**,网卡允许我们对硬中断进行合并。**
网卡队列 CPU 绑定现在的主流网卡基本上都是支持多队列的,我们可以通过将不同的队列分给不同的 CPU 核心来处理,从而加快 Linux 内核处理网络包的速度。这是最为有用的一个优化手段。
每一个队列都有一个中断号,可以独立向某个 CPU 核心发起硬中断请求,让 CPU 来 poll 包。通过将接收进来的包被放到不同的内存队列里,多个 CPU就可以同时分别向不同的队列发起消费了。这个特性叫做 RSS(Receive Side Scaling,接收端扩展)。通过 ethtool 工具可以查看网卡的队列情况。
关闭 IRQBalance
IRQBalance 主要功能是可以合理的调配使用各个 CPU 核心,特别是对于目前主流多核心的 CPU,简单的说就是能够把压力均匀的分配到各个 CPU 核心上,对提升性能有很大的帮助。
但实际中往往影响 cpu 的使用均衡,建议服务器环境中关闭
net.core.dev_weight
每个 CPU 一次 NAPI 中断能够处理网络包数量的最大值,可以根据实际情况调整。
TCP NODELAY
Nagle 算法用于对缓冲区内的一定数量的消息进行自动连接。该处理过程(称为 Nagling),通过减少必须发送的封包的数量,提高了网络应用 程序
系统的效率。(Nagle 虽然解决了小封包问题,但也导致了较高的不可预测的延迟,同时降低了吞吐量。)
RocketMQ 通讯层已经禁止了
// org.apache.rocketmq.remoting.netty.NettyRemotingServer#start
.childOption(ChannelOption.TCP_NODELAY, true)
缓冲区调整
队列大小调整
















 2355
2355











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











