







决策树
决策树模型,适用于分类、回归。
简单地理解决策树呢,就是通过不断地设置新的条件标准对当前的数据进行划分,最后以实现把原始的杂乱的所有数据分类。
就像下面这个图,如果输入是一大堆追求一个妹子的汉子,妹子内心里有个筛子,最后菇凉也就决定了和谁约(举栗而已哦,不代表什么~大家理解原理重要~~)
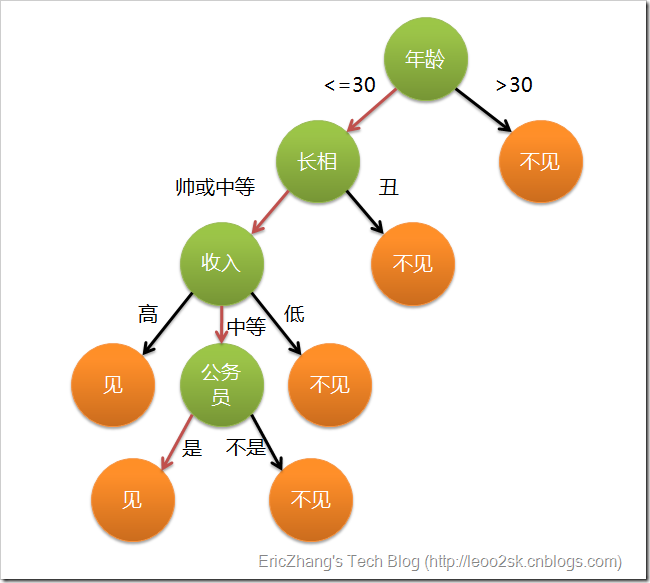
不难看出,构造决策树的关键就在于划分条件和终止条件的决定
一个属性能不能作为划分条件要看用他来分类好不好,我们说原始信息是无序的,那么他能不能很好地降低信息的无序性。
我们常用Gini不纯度、错误率(Error)、熵(Entropy)来衡量信息的混乱程度,公式定义分别如下:



P(i)表示事件i发生的概率,这三个数越大说明数据越不纯。
比较属性的划分效果的算法有C4.5、ID3。详细的可以参考这篇博文在spark中终止条件可以由决策树的构造方法
DecisionTree.trainRegressor(trainingData, categoricalFeaturesInfo, impurity, maxDepth, maxBins)
的参数:最大深度maxDepth、最大划分数(在构建节点时把数据分到多少个盒子中去)maxBins来决定
参数categoricalFeaturesInfo是一个映射表,用来指明哪些特征是分类的,以及他们有多少个类。比如,特征1是一个标签为1,0的二元特征,特征2是0,1,2的三元特征,则传递{1: 2, 2: 3}。如果没有特征是分类的,数据是连续变量,那么我们可以传递空表。
impurity表示结点的不纯净度测量,分类问题采用 gini或者entropy,而回归必须用 variance。
决策树的缺点是容易过拟合,导致训练出来的模型对训练集的拟合效果很好,对其他数据的效果却有所下降。对深度和最大划分数的设定就是为了避免这种情况,当然,在下面我们还将接触到决策树的优化版:随机森林,随机森林就可以很好地处理这个问题。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 271
271











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









