









前言
学完稀疏自编码器,参考http://deeplearning.stanford.edu/wiki/index.php/UFLDL%E6%95%99%E7%A8%8B中的Exercise:Sparse Autoencoder
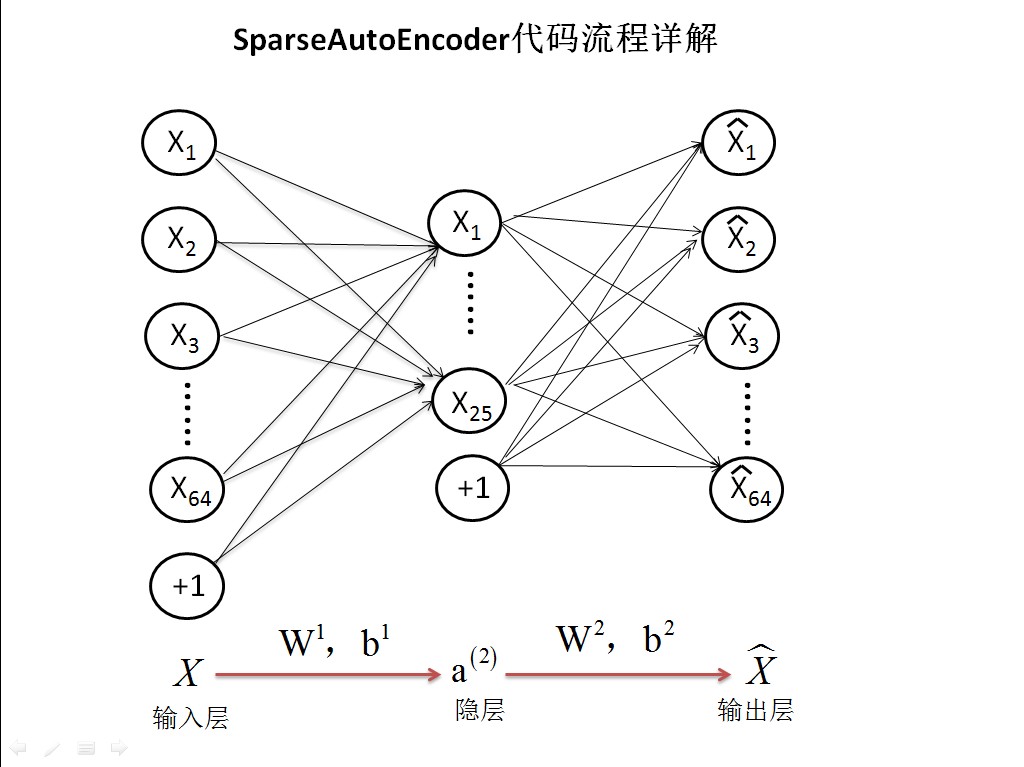
使用MatLab完成练习要求。这个例子所要实现的内容大概如下:从给定的数据文件IMAGES.mat(这是一个512*512*10的三维数组,里面存了10张图片,每张图片像素为262144)中截取出大小为8*8的小patches图片共10000张,现在需要用sparse autoencoder的方法训练出一个隐含层网络所学习到的特征。该网络共有3层,输入层是64个节点,隐含层是25个节点,输出层当然也是64个节点了。
实验基础:
其实实现该功能的主要步骤还是需要计算出网络的损失函数以及其偏导数,具体的公式可以参考这篇博文Deep learning:八(Sparse Autoencoder)。下面用简单的语言大概介绍下这个步骤,方便大家理清算法的流程。
1. 计算出网络每个节点的输入值(即程序中的z值)和输出值(即程序中的a值,a是z的sigmoid函数值)。
2. 利用z值和a值计算出网络每个节点的误差值(即程序中的delta值)。
3. 这样可以利用上面计算出的每个节点的a,z,delta来表达出系统的损失函数以及损失函数的偏导数了,当然这些都是一些数学推导,其公式就是前面的博文Deep learning:八(Sparse Autoencoder)了。
其实步骤1是前向进行的,也就是说按照输入层——》隐含层——》输出层的方向进行计算。而步骤2是方向进行的(这也是该算法叫做BP算法的来源),即每个节点的误差值是按照输出层——》隐含层——》输入层方向进行的。
一些malab函数:
bsxfun:
C=bsxfun(fun,A,B)表达的是两个数组A和B间元素的二值操作,fun是函数句柄或者m文件,或者是内嵌的函数。在实际使用过程中fun有很多选择比如说加,减等,前面需要使用符号’@’.一般情况下A和B需要尺寸大小相同,如果不相同的话,则只能有一个维度不同,同时A和B中在该维度处必须有一个的维度为1。比如说bsxfun(@minus, A, mean(A)),其中A和mean(A)的大小是不同的,这里的意思需要先将mean(A)扩充到和A大小相同,然后用A的每个元素减去扩充后的mean(A)对应元素的值。
rand:
生成均匀分布的伪随机数。分布在(0~1)之间
主要语法:rand(m,n)生成m行n列的均匀分布的伪随机数
rand(m,n,'double')生成指定精度的均匀分布的伪随机数,参数还可以是'single'
rand(RandStream,m,n)利用指定的RandStream(我理解为随机种子)生成伪随机数
randn:
生成标准正态分布的伪随机数(均值为0,方差为1)。主要语法:和上面一样
randi:
生成均匀分布的伪随机整数
主要语法:randi(iMax)在闭区间(0,iMax)生成均匀分布的伪随机整数
randi(iMax,m,n)在闭区间(0,iMax)生成mXn型随机矩阵
r = randi([iMin,iMax],m,n)在闭区间(iMin,iMax)生成mXn型随机矩阵
exist:
测试参数是否存在,比如说exist('opt_normalize', 'var')表示检测变量opt_normalize是否存在,其中的’var’表示变量的意思。
colormap:
设置当前常见的颜色值表。
floor:
floor(A):取不大于A的最大整数。
ceil:
ceil(A):取不小于A的最小整数。
imagesc:
imagesc和image类似,可以用于显示图像。比如imagesc(array,'EraseMode','none',[-1 1]),这里的意思是将array中的数据线性映射到[-1,1]之间,然后使用当前设置的颜色表进行显示。此时的[-1,1]充满了整个颜色表。背景擦除模式设置为node,表示不擦除背景。
repmat:
该函数是扩展一个矩阵并把原来矩阵中的数据复制进去。比如说B = repmat(A,m,n),就是创建一个矩阵B,B中复制了共m*n个A矩阵,因此B矩阵的大小为[size(A,1)*m size(A,2)*m]。
SUM(X,DIM) :
sums along the dimension DIM.
If X = [0 1 2; 3 4 5]
then sum(X, 1) is [3 5 7] and sum(X, 2) is [3; 12]
以上部分摘自博客:
http://www.cnblogs.com/tornadomeet/archive/2013/03/20/2970724.html
Andrew ng原文:http://deeplearning.stanford.edu/wiki/index.php/Exercise:Sparse_Autoencoder
源码以及数据:http://ufldl.stanford.edu/wiki/resources/sparseae_exercise.zip
程序过程解析
step0:参数初始化
visibleSize = 8*8; % 输入特征数,也是每个小图片的维数
hiddenSize = 25; % 隐层节点数
sparsityParam = 0.01; % 期望稀疏值
lambda = 0.0001; % 权值惩罚参数
beta = 3; % weight of sparsity penalty term
step1:调用sampleIMAGES函数,加载并处理数据
patches = sampleIMAGES; %patches函数的作用就是把每个小patch拉成一个列向量
display_network(patches(:,randi(size(patches,2),200,1)),8); %显示200个patch的随机样本
theta = initializeParameters(hiddenSize, visibleSize);1)sampleIMAGE函数关键部分解析
for imageNum = 1:10%在每张图片中随机选取1000个patch,共10000个patch
[rowNum colNum] = size(IMAGES(:,:,imageNum));
for patchNum = 1:1000%实现每张图片选取1000个patch
xPos = randi([1,rowNum-patchsize+1]);%randi用于生产随机整数矩阵randi([min max],m,n)
yPos = randi([1, colNum-patchsize+1]);
patches(:,(imageNum-1)*1000+patchNum) = reshape(IMAGES(xPos:xPos+7,yPos:yPos+7,...
imageNum),64,1);%reshap函数,将8*8的方阵,变形为64*1的列向量
end
end
处理数据
patches = normalizeData(patches);normalizeData()函数先使用标准差使数据范围变为-1到1,之后再变换到[0.1,0.9],以便和sigmoid函数输出值匹配
function patches = normalizeData(patches)
% Squash data to [0.1, 0.9] since we use sigmoid as the activation
% function in the output layer
% Remove DC (mean of images).
patches = bsxfun(@minus, patches, mean(patches));
% Truncate to +/-3 standard deviations and scale to -1 to 1
pstd = 3 * std(patches(:));
patches = max(min(patches, pstd), -pstd) / pstd;
% Rescale from patches:[-1,1] to [0.1,0.9]
patches = (patches + 1) * 0.4 + 0.1; 2)initializeParameters函数
通过输入层和隐层节点数,初始化权值矩阵和偏置项矩阵。
初始化权值矩阵是,是通过在[-r, r]区间内随机初始化矩阵r = sqrt(6) / sqrt(hiddenSize+visibleSize+1)=0.2582;(这个我不不清楚为啥,只知道Andrew教程中权值初始值要随机,且随机数值不应过大)
W1 = rand(hiddenSize, visibleSize) * 2 * r - r;
W2 = rand(visibleSize, hiddenSize) * 2 * r - r;
b1 = zeros(hiddenSize, 1);
b2 = zeros(visibleSize, 1);
theta = [W1(:) ; W2(:) ; b1(:) ; b2(:)];把矩阵向量化,通过向量来传递参数;个人猜测应该是通过向量传参效率高
STEP 2: 实现 sparseAutoencoderCost,稀疏损失函数
[cost, grad] = sparseAutoencoderCost(theta, visibleSize, hiddenSize, lambda, ...
sparsityParam, beta, patches);1)通过反转向量,把向量还原为权值矩阵
2)计算损失函数和梯度
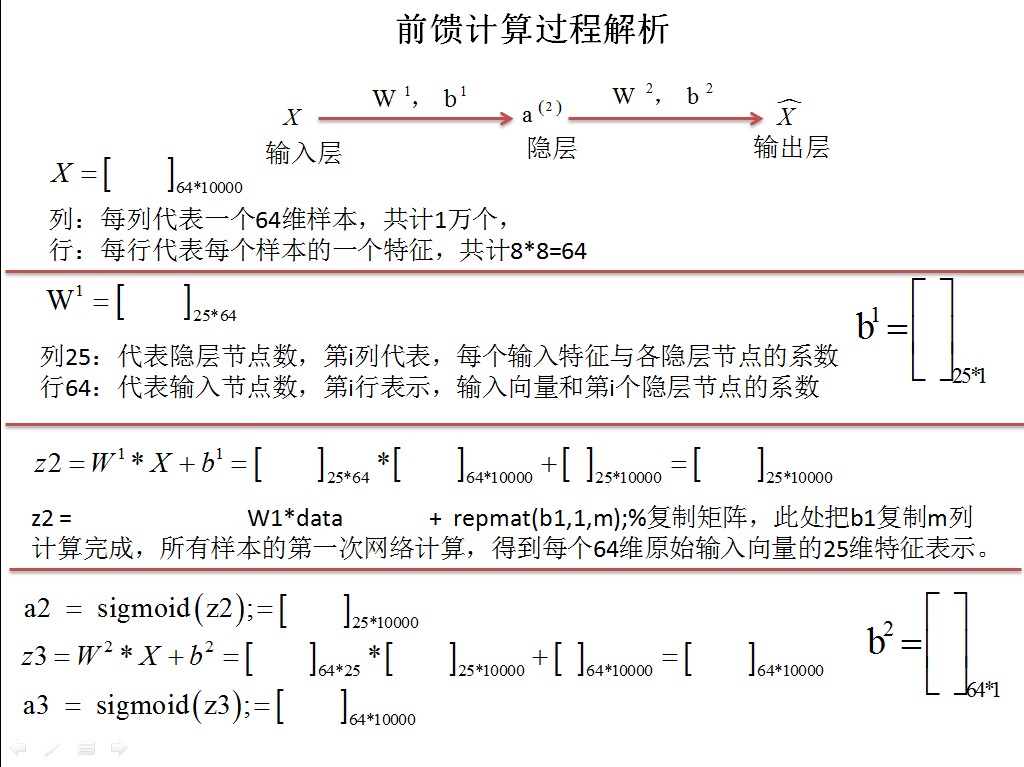




最后把矩阵权值向量化,当做参数传递出来
grad = [W1grad(:) ; W2grad(:) ; b1grad(:) ; b2grad(:)];
STEP 3: 通过l-bfgs算法优化训练稀疏矩阵
theta = initializeParameters(hiddenSize, visibleSize);
% Use minFunc to minimize the function
addpath minFunc/
options.Method = 'lbfgs'; % Here, we use L-BFGS to optimize our cost
% function. Generally, for minFunc to work, you
% need a function pointer with two outputs: the
% function value and the gradient. In our problem,
% sparseAutoencoderCost.m satisfies this.
options.maxIter = 400; % Maximum number of iterations of L-BFGS to run
options.display = 'on';
[opttheta, cost] = minFunc( @(p) sparseAutoencoderCost(p, ...
visibleSize, hiddenSize, ...
lambda, sparsityParam, ...
beta, patches), ...
theta, options);STEP4:可视化学习到的权值矩阵W1.
W1 = reshape(opttheta(1:hiddenSize*visibleSize), hiddenSize, visibleSize);
display_network(W1', 12);
print -djpeg weights.jpg % save the visualization to a file 
参考:http://blog.csdn.net/whiteinblue/article/details/20639629















 1032
1032











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









