




来源: AINLPer公众号(每日干货分享!!)
编辑: ShuYini
校稿: ShuYini
时间: 2024-5-22
引言
当下,低秩适应 (LoRA)是一种常用的大模型参数高效微调方法。而本文作者反其道而行之提出了高秩适应(MoRA),摆明是硬刚LoRA了,那么让我们看看是怎么个事儿?
简单来说,作者通过实验验证发现,当前LoRA方法在指令调优任务上虽然可以与全参数微调(FFT)相媲美,但在新知识记忆方面却远不如FFT,主要原因是和秩的大小相关。为此作者提出了新的大模型微调方法:MoRA,该方法采用方阵(Square Matrix)来实现高秩更新,同时保持相同数量的可训练参数。在五项大模型评估任务中,MoRA在内存密集型任务上优于 LoRA,并在其它任务上实现了相当的性能。
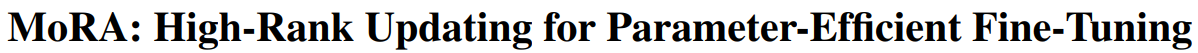
https://arxiv.org/pdf/2405.12130
背景介绍
随着大模型参数量的不断增加,参数高效微调(PEFT)已经成为了当前大模型微调的主流技术。相比大模型全参数微调(Full Fine-Tuning,FFT),该项技术仅修改模型参数的一小部分,经过较少的训练时间就可以快速适应下游任务。除此之外,有研究表示在某些任务中,只更新不到1%的参数量就可以实现FFT的性能,这显著降低了模型训练对内存资源的需求,减少了计算资源的浪费。
在现有的PEFT方法中,低秩适应 (LoRA)可以说是在大模型微调中应用的最为流行的一种方法。相比其它PEFT方法(例如:prompt tuning 、adapters tuning等 ),LoRA通过低秩矩阵更新参数,这些矩阵可以合并到原始模型参数中,从而避免推理过程中额外的计算成本。并且也出现了很多LoRA的改进版本,例如QLoRA、QL-LoRA、DLoRA等。
但是这些改进的LoRA版本,大部分都是基于GLUE 来验证其有效性,要么是实现更好的性能,要么是需要更少的可训练参数。随着学术研究的推进,今年很多研究人员逐步开始利用Alpaca 等指令调优任务、 GSM8K 等推理任务来评估其在LLM方面的表现。然而,前人评估过程中采用的不同设置和数据集,让我们很难理解此类方法的进展。
类LoRA分析
为此,本文在相同设置下对LoRA的各种任务进行了全面的评估,其中包括指令调优、数学推理和持续训练。作者发现类LoRA 的方法在这些任务中表现了相当的性能,并且它们在指令调优方面的性能与 FFT 相当,但在数学推理和持续预训练方面存在不足。如下图所示: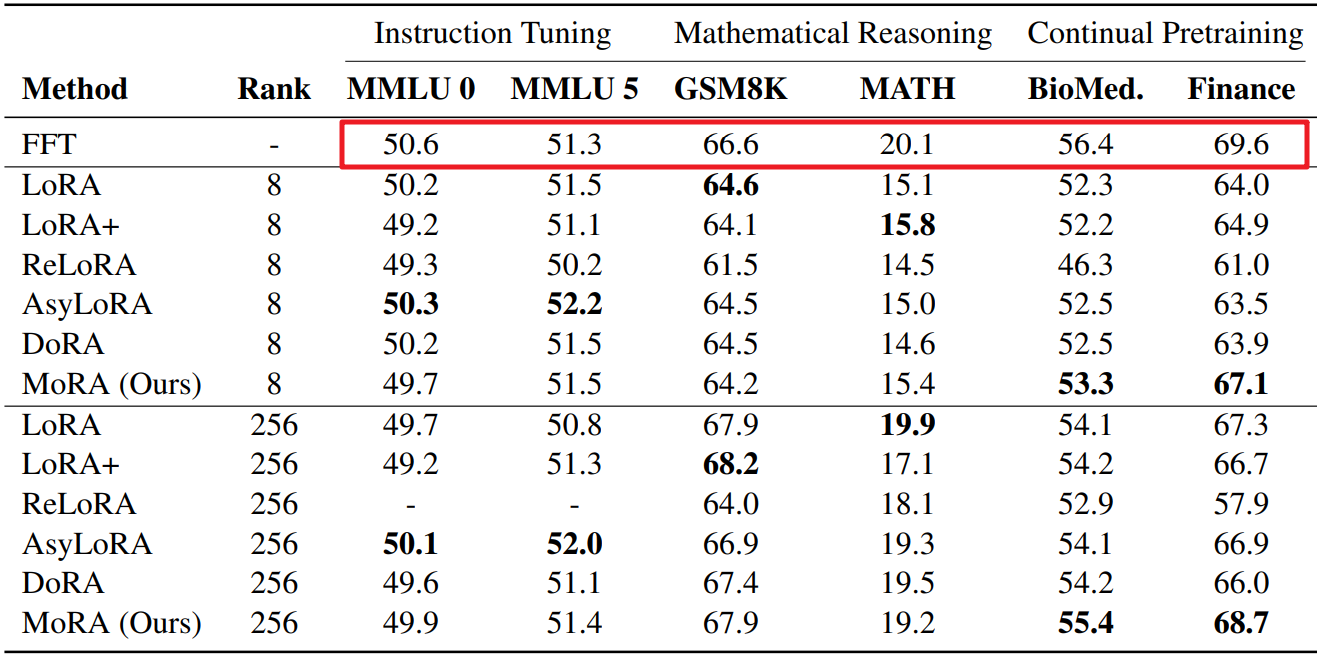
那么,为什么类似LoRA的方法能够在指令调优任务中表现出了与 FFT 相当性能呢?本文作者认为指令调优主要侧重于与格式的交互,而不是获取知识和能力,而这些知识和能力几乎完全是在预训练期间学习的。除此之外,作者还观察到LoRA 在处理其他需要通过微调来增强知识和能力的任务时却遇到了困难,为此,本文作者认为低秩更新矩阵
Δ
W
ΔW
ΔW 很难估计 FFT 中的满秩更新,特别是在需要记忆特定领域知识的持续预训练等内存密集型任务中。
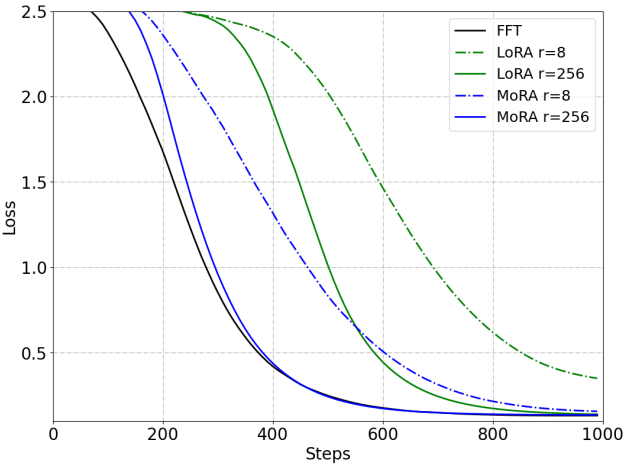
此外,当前LoRA变体方法无法改变低秩更新的固有特征。 为了验证这一点,作者使用伪数据进行了记忆任务验证,以评估 LoRA 在记忆新知识方面的表现,如下图所示。 与猜想的一样,作者发现 LoRA 的表现明显比 FFT 差,即使增加LoRA的秩的大小可以缓解。
MoRA
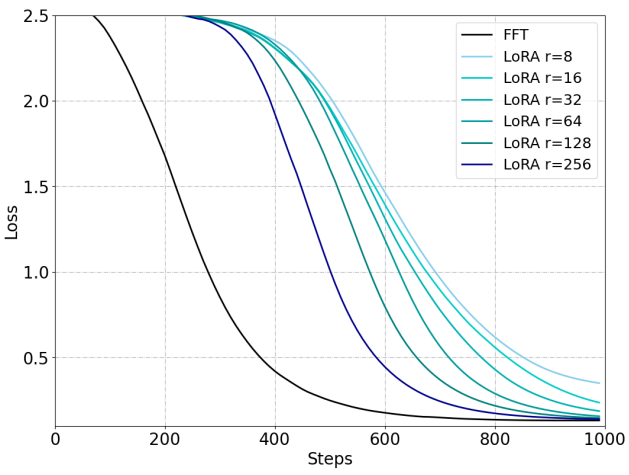
基于上面对类LoRA的分析,本文作者提出了一种新模型微调方法:MoRA,该方法并没有采用LoRA的低秩矩阵,而是采用了方阵 M M M,旨在最大化 Δ W ΔW ΔW ,同时保持相同数量的可训练参数。
例如,当使用隐藏大小为 4096 的 8 秩时,LoRA 采用两个低秩矩阵
A
∈
R
4096
×
8
A∈R 4096×8
A∈R4096×8 和
B
∈
R
8
×
4096
B ∈ R 8×4096
B∈R8×4096,其中
R
a
n
k
(
Δ
W
)
≤
8
Rank(ΔW) ≤ 8
Rank(ΔW)≤8。在相同数量的参数下,我们的 该方法使用方阵
M
∈
R
256
×
256
M ∈ R 256×256
M∈R256×256,
R
a
n
k
(
Δ
W
)
≤
256
Rank(ΔW)≤ 256
Rank(ΔW)≤256,如下图所示。
值得注意的是,为了使方阵
M
M
M能够适应不同维度的输入和输出,本文MoRA引入了非参数化的压缩
f
c
o
m
p
f_{comp}
fcomp 和解压(
f
d
e
c
o
m
p
f_{decomp}
fdecomp )操作,其中:
- 压缩操作( f c o m p f_{comp} fcomp):旨在将输入特征从维度 k k k减少到 r ^ \hat{r} r^,其中 r ^ \hat{r} r^是根据 r r r和模型维度计算得到的;
- 解压( f d e c o m p f_{decomp} fdecomp)操作:旨在将方阵 M M M的输出从维度 r ^ \hat{r} r^增加到原始维度 d d d;
本文MoRA设计的压缩( f c o m p f_{comp} fcomp)和解压( f d e c o m p f_{decomp} fdecomp)操作是可逆的,这意味着可以通过逆操作将方阵 M M M无损地转换回原始权重Δ𝑊,来确保本文方法可以像 LoRA 一样合并回 LLM。简单来说:MoRA通过选择合适的 r ^ \hat{r} r^,并利用压缩/解压操作,使得方阵 M M M能够达到比LoRA更高的秩,从而提高模型的学习能力。
实验结果
下表展示了不同方法在三个任务上的性能。MoRA在指令调整和数学推理任务上与LoRA表现相当,在持续预训练任务上优于LoRA。
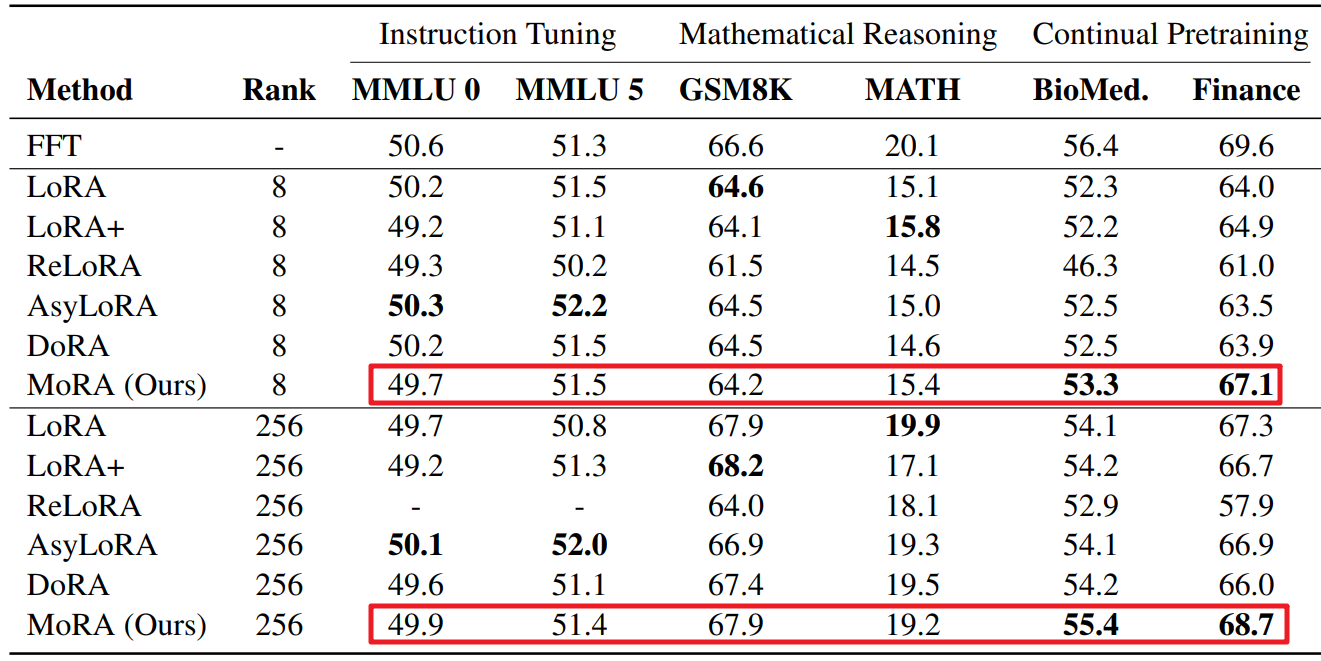
下图展示了LoRA系列方法在记忆UUID对的任务上性能,可以发现MoRA显著优于LoRA,并且与FFT相当,证明了高秩更新在记忆能力上的优势。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









