







源自: AINLPer(每日干货分享!!)
编辑: ShuYini
校稿: ShuYini
时间: 2025-4-13
引言
随着当前生成式AI的发展,视频生成成为了一个核心研究方向,从内容创作到虚拟仿真等应用场景,它能让人们很快的展示出自己内心想法。但是当前视频生成模型仍存在一些短板,例如:提示词理解偏弱、运动场景质量欠佳、视频时长受限等。然而,就在刚刚昆仑万维开源全球首款支持无限时长的高质量视频生成模型Skyreels-V2,支持视频时长自定义,具备“电影级视频”生成能力,稳坐开源SOTA。
以下是模型实际生成视频展示:

论文:https://arxiv.org/pdf/2504.13074
GitHub:https://github.com/SkyworkAI/SkyReels-V2
Skyreels-V2技术介绍
在视频生成方面,如果要让生成模型达到电影级视频生成能力,需要面临以下四大难题:
-
指令理解 当前视频生成模型多依赖通用型多模态大模型(如 Qwen2.5-VL)进行视频理解或标注。这些模型虽能处理普通视频内容,但面对“电影镜头语言”则力不从心,无法满足电影制作人对于镜头语言的精细化控制。比如:对相关镜头类型、人物的表情动作、摄影机运动方式等理解;
-
连贯性 当前主流视频生成模型在优化上更多关注每一帧的图像质量(appearance),而忽视了视频的时间一致性和运动连贯性。就比如:视频场景中快速移动或大幅运动时容易“失真”、存在违反物理规律的动作,如物体反重力上升、关节扭曲等;
-
视频长度限制 目前大部分视频生成模型受限于内存与训练结构,生成长度一般仅为 5–10 秒。其主要原因是因为扩散模型需要逐帧反向采样,计算开销大,同时长时间段的视频生成会带来 记忆累积误差,导致画面质量或一致性下降。虽然自回归模型可以进行扩展,但其精度下降非常厉害。
-
数据集缺乏:当前一些视频生成模型的训练数据中存在的字幕、logo、水印、镜头跳转等干扰因素,缺乏**对镜头语言(Shot Language)**的系统标注;而且常规的视频描述数据无法为专业电影镜头语言提供有效监督。真正要做到电影级视频生成需要相关的视频标注数据集,它需要包括主体类型、表情、动作、位置;镜头类型、角度、机位;摄影机运动方式、场景与光线特征等。
面对这些问题**昆仑万维的专家们逐个分析,大胆创新,**提出了一整套系统性的方法框架,结合多模态语言模型(MLLM)、结构化标注、扩散生成、强化学习与高质量微调等技术,旨在突破现有视频生成模型在时长、动态质量、指令理解等方面的关键瓶颈。
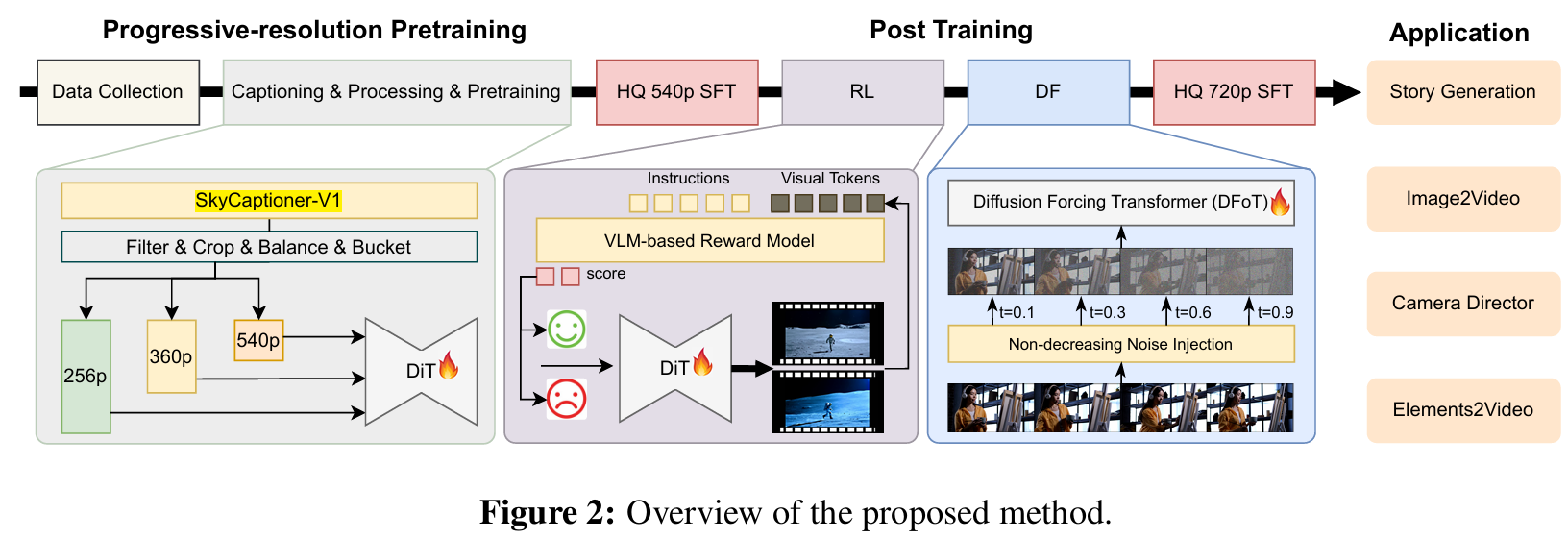
最终让Skyreels-V2打破了现有模型在提示理解、动态捕捉和时序延展上的限制,打通“剧本—画面”生成链路,支持自动故事叙述、镜头控制等电影制作流程;实现了高质量、长时间、电影级的视频生成。
数据质量控制
数据处理是模型训练根本,很多研究表明高质量的数据对于模型效果至关重要。作者将数据源(Data Sources)、处理流程(Processing Pipeline)以及人工在环验证(Human-In-The-Loop Validation)进行整合。如下图所示:
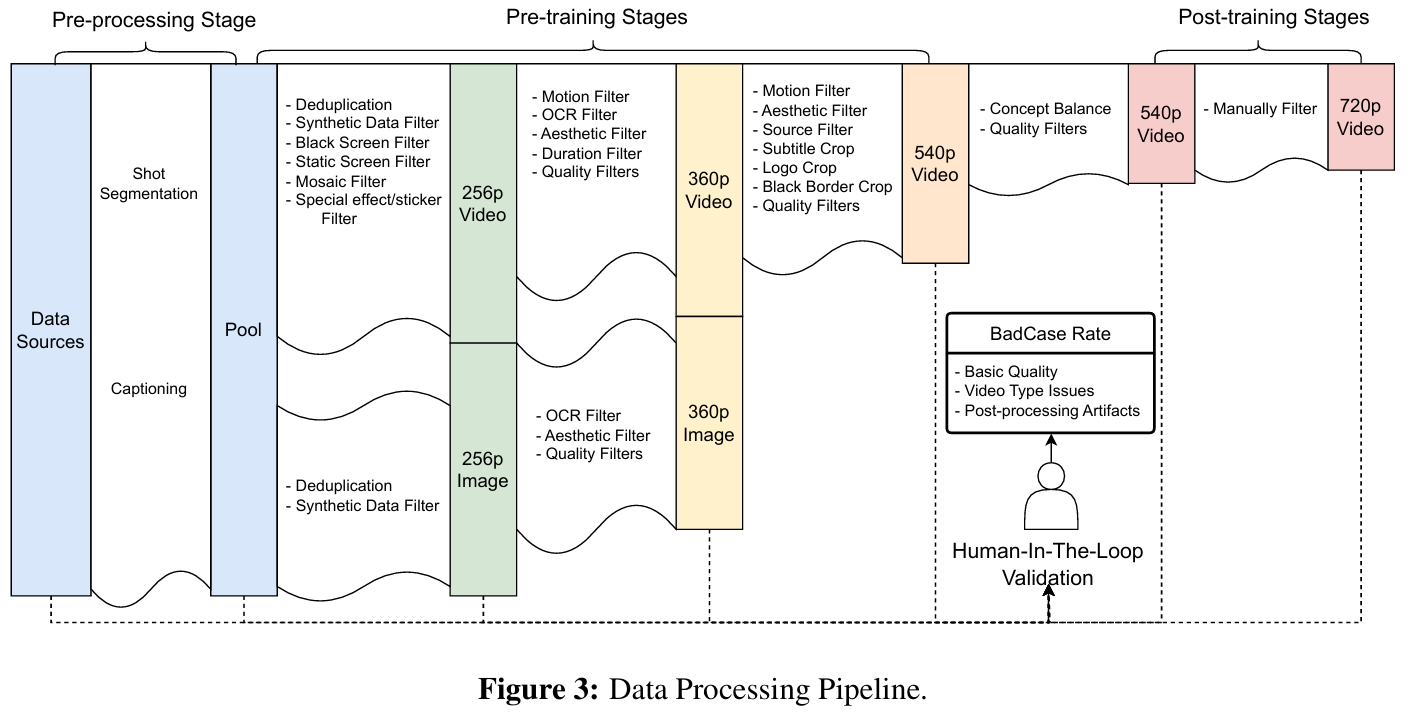
数据处理流程采用逐步过滤策略,从宽松到严格的标准逐步过渡,在整个训练过程中系统地减少数据量,同时提升质量。这一流程从多样化的数据源获取原始输入,然后通过一个自动化处理流程,通过不同的过滤阈值来控制样本的质量。
数据处理流程的关键支柱是人工在环验证的整合,它专注于对来自原始数据源和不同阶段训练样本的抽样数据进行人工评估。通过在关键阶段进行系统抽样检查确保识别并纠正模糊、错误或不符合要求的数据,最终保障对稳健模型训练至关重要的最终数据质量。
高质量视频描述
好的提示词可以激发大模型的潜力,为了突破通用多模态大模型(如 Qwen2.5-VL)无法理解“电影镜头语言”的限制。

本文作者使用 Qwen2.5-VL 作为基础模型生成结构化初步描述(如上图所示),并由多个子专家模型进行字段级替换提升视频描述精度。这些子专家包括:
-
Shot Captioner:负责镜头类型、角度、机位分类,准确率最高达 93.1%;
-
Expression Captioner:基于情绪分类 + VLM生成,支持细粒度的情绪强度、表情肌肉变化等;
-
Camera Motion Captioner:使用 6DoF 参数离散化建模(2187类组合),结合主动学习策略对复杂运动建模。
最终,通过结构融合与 Drop Rate 机制适配不同任务(如 text-to-video 或 image-to-video)需求,产出高质量的结构化视频描述文本,支撑模型训练中的指令对齐与镜头层级学习。
多阶段预训练
在预训练阶段采用逐级提升分辨率的多阶段策略,结合 Flow Matching 框架进行建模,并仅训练 Diffusion Transformer(DiT),复用 VAE 和文本编码器权重。
阶段1
在低分辨率数据(256p)上预训练,以获取基本生成能力。采用联合图像-视频训练,支持不同宽高比和帧长。通过严格的数据过滤和去重,确保数据质量与多样性。此阶段模型学会低频概念,生成视频虽模糊但具备基础能力。
阶段2
将分辨率提升至360p,继续联合图像-视频训练,应用更复杂的数据过滤策略,包括时长、运动、OCR、审美和质量过滤。生成视频的清晰度显著提升。
阶段3
分辨率提升到540p,专注于视频目标。实施更严格的运动、审美和质量过滤,并引入来源过滤,去除用户生成内容,保留电影级数据。生成视频的视觉质量和真实感显著增强。
预训练AdamW设置
使用AdamW优化器。阶段1初始学习率为
1
×
1
0
−
4
1 \times 10^{-4}
1×10−4,无权重衰减;损失稳定后,学习率调整为
5
×
1
0
−
5
5 \times 10^{-5}
5×10−5,权重衰减为
1
×
1
0
−
4
1 \times 10^{-4}
1×10−4。阶段2和3学习率进一步降低至
2
×
1
0
−
5
2 \times 10^{-5}
2×10−5。
后训练
后训练是提升模型整体性能的关键阶段。后训练包括四个阶段:540p的高质量SFT(监督微调)、强化学习、扩散强制训练以及720p的高质量SFT。为了提高效率,前三个后训练阶段在540p分辨率下进行,最后一个阶段在720p分辨率下进行。具体来说:
1、540p的高质量SFT:使用结构化标注 + 精选视频进行高质量监督微调,构建训练良好的初始状态,同时移除帧率嵌入优化结构简洁性,为后续阶段提供更好的初始化。
2、运动质量增强:为提升视频运动质量,引入 Direct Preference Optimization(DPO)策略,重点训练 Motion Reward Model。数据来源包括:
- 人工标注偏好对:专业评分器对同一提示下生成视频配对标注优劣;
- 自动生成失真样本:从真实视频通过 V2V/I2V/T2V 模式制造失真样本,同时包括“反物理规律”如倒放等策略。
Motion Reward Model 基于 Qwen2.5-VL-7B-Instruct 实现,用于引导生成模型迭代优化,共进行三轮 DPO 训练,逐步更新参考模型提升样本质量。
3、扩散强制训练:为实现无限长视频生成,SkyReels-V2 将传统同步扩散模型转换为 Diffusion Forcing 架构。该方法通过为每帧分配不同噪声等级,允许模型以部分遮掩方式自回归生成。关键机制包括:
- FoPP(Frame-oriented Probability Propagation)调度器:确保帧级时间步不递减;
- AD(Adaptive Difference)调度器:控制帧间差异实现自回归推理;
- 上下文因果注意力转换:支持历史帧缓存加速采样。
4、720p高质量SFT:在 720p 分辨率下再次进行 Supervised Fine-tuning,进一步提升视觉质量,使模型达到商用级别画面标准。
实验结果
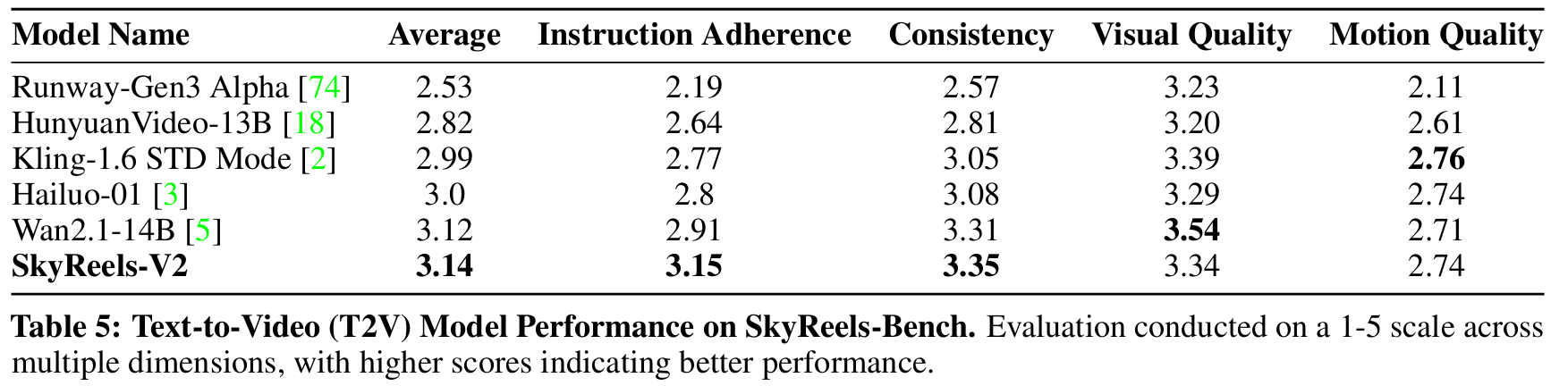
在SkyReels-Bench上的对比各个开源视频生成模型比较结果如下,平均得分最高。
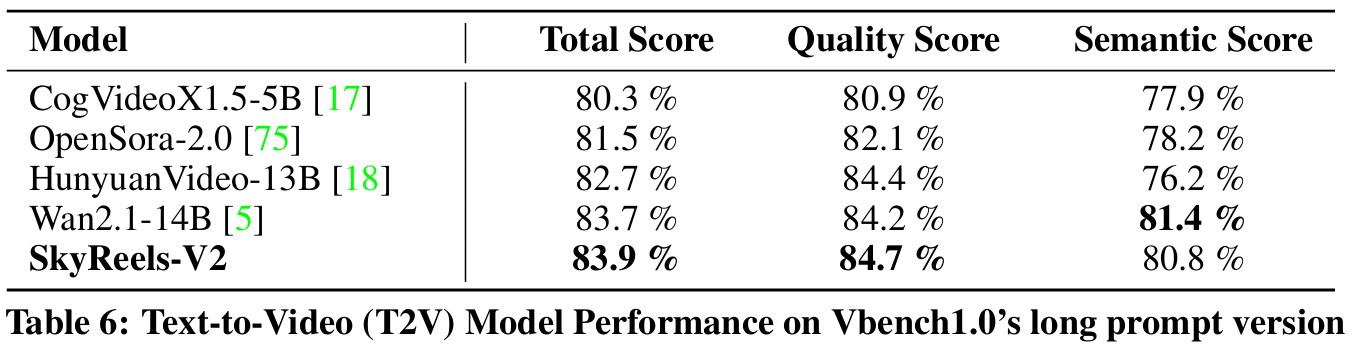
使用公共基准测试 VBench1.0 进行了综合评估,SkyReels-V2 与其他领先的开源视频生成模型比较结果如下:
Skyreels-V2颠覆能力体验
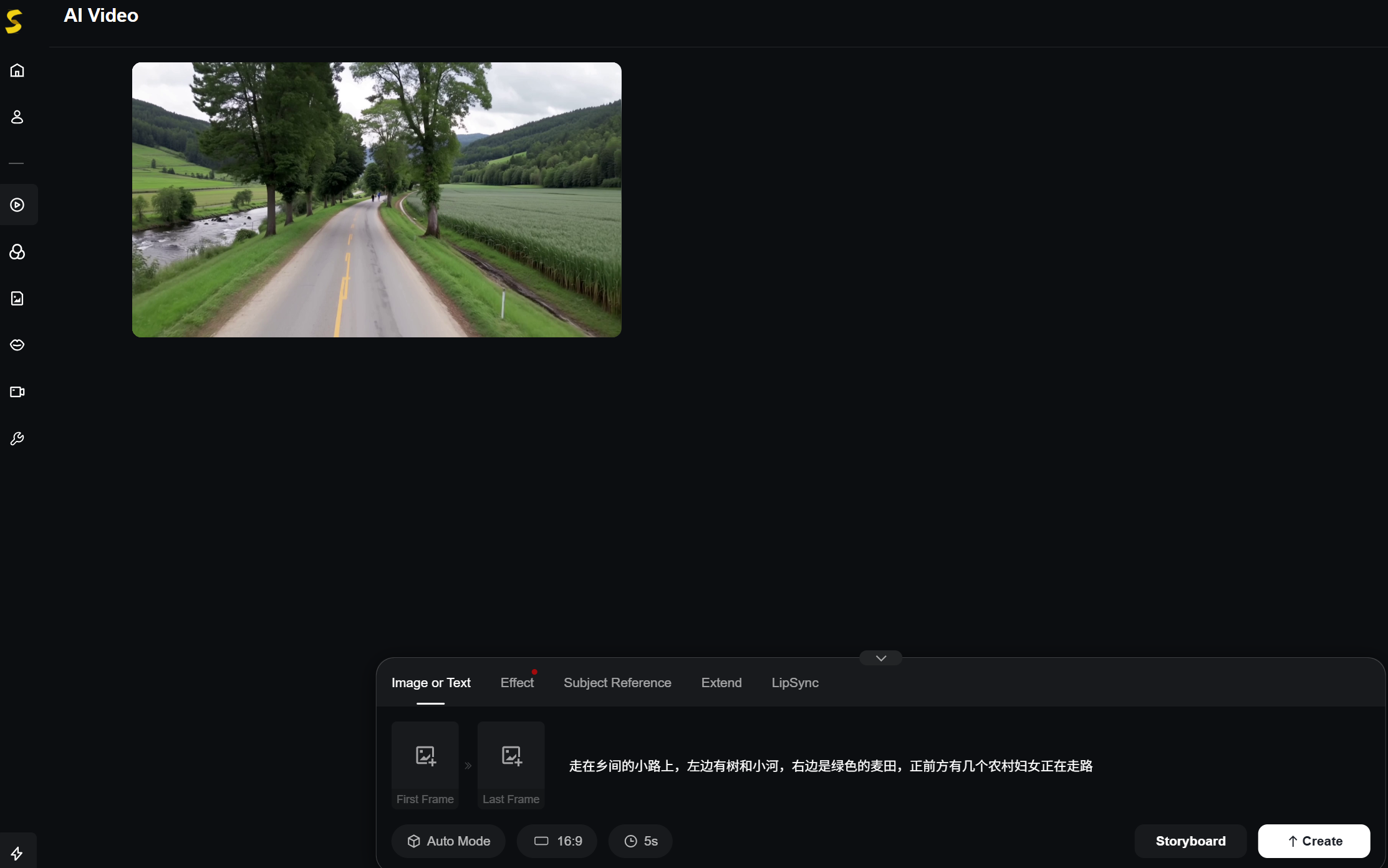
目前Skyreels-V2模型已经开源,各位小伙伴可以下载体验。如果没有显卡资源也没有关系,可以直接访问:https://www.skyreels.ai/ 进行在线视频Demo生成体验,且支持30s视频生成。点击下方 Create 就可以直接体验。
这里我输入的Prompt是:走在乡间的小路上,左边有树和小河,右边是绿色的麦田,正前方有几个农村妇女正在走路,生成的视频如下:
麦田
Prompt 女生化妆
Prompt:两只小鸟正在树枝上kiss
总结
昆仑万维开源SkyReels-V2是目前唯一同时支持“专业级电影级镜头理解”、“长时视频生成”、“高动态质量建模”且完全开源的视频生成模型,其生成画面高清、细节丰富、无撕裂变形,视觉体验媲美闭源模型。在 V-Bench1.0 长文本任务中拿下最高质量分(84.7%)和总分(83.9%),超过所有开源模型,稳坐开源视频生成SOTA。
AI-Agent文章推荐
[1]盘点一下!大模型Agent“花式玩法”
[2]2025年的风口!| 万字长文纵观大模型Agent!
[3]大模型Agent的 “USB”接口!| 一文详细了解MCP(模型上下文协议)
[4]2025年的风口!| 万字长文纵观大模型Agent!
[5]万字长文!从AI Agent到Agent工作流,一文详细了解代理工作流(Agentic Workflows)
更多精彩内容–>专注大模型/AIGC、Agent、RAG等学术前沿分享!

















 863
863

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









