









前面两篇我们学习实践的二叉查找树和平衡二叉树以及有序数组的二分查找、单链表的逐个查找,都需要进行比较和递归。那么有没有其他的查询技术呢?通过下图可以看到散列表我们还没有涉及,今天我们就来对散列表(哈希表)进行学习实践。

图片来源于《算法》
一、基本概念
散列技术,不需要比较和递归。通过记录存储位置和它的关键字之间建立一个确定的对应关系f,使得每个关键字key对应一个存储位置f(key)
把这种对应关系f称为散列函数,或者哈希函数。
采用散列技术将记录存储在一块连续的存储空间中,这块连续存储空间称为散列表或者哈希表(Hash table)
散列表的适用范围,针对一对一,有映射关系 查找效率比较高。一旦出现key重复的情况,查找效率就变低了。
散列表的查找步骤
-
存储时,通过散列函数计算出要存储的值对应的散列地址
-
当查找时,通过同样的散列函数要查找值的散列地址,并按照散列地址访问
二、散列表的构造方式
散列表的构造过程是 根据散列函数,把对应的key映射到对应的存储地址
散列函数的好坏直接影响散列表插入和查询的效率。
好的散列函数衡量的两个指标是 计算简单、分布均匀。
常见散列函数:有直接定值法、数字分析法、平法取中法、折叠法以及除留余数法等。除留余数法的效率一般情况下优于其他几种类型的散列函数,也是最常用的散列函数。这篇来学习实践通过除留余数法的方式构造散列表
对于散列表长度为m,其对应的除留余数法散列函数计算公式如下:
f(key) = key mod p. (p<=m)
这里的key就是要插入或者查询的值,mod是除留运算,p是取模的分母,一般p的值小于等于散列表的长度m。
a={12,25,38,15,16,29,78,67,56,21,22,47}
对于这个长为12数组,我们通过除留余数法进行散列表的构造
12 % 12 = 0
25 % 12 = 1
38 % 12 = 2
15 % 12 = 3
16 % 12 = 4
29 % 12 = 5
78 % 12 = 6
67 % 12 = 7
56 % 12 = 8
21 % 12 = 9
22 % 12 = 10
47 % 12 = 11
上述数组是比较理想的情况,除留运算后没有出现冲突,但是如果把数组改成如下值就会出现碰撞的情况
a={12,24,38,15,16,29,78,67,50,21,22,47}
对于这个长为12数组,我们通过除留余数法进行散列表的构造
12 % 12 = 0
24 % 12 = 0 --》出现了碰撞
38 % 12 = 2
15 % 12 = 3
16 % 12 = 4
29 % 12 = 5
78 % 12 = 6
67 % 12 = 7
50 % 12 = 2 --》出现了碰撞
21 % 12 = 9
22 % 12 = 10
47 % 12 = 11
这针对这种情况,我们该怎么处理呐?
关注+后台私信我,领取2022最新最全学习提升资料包+面试题+学习视频,内容包括(C/C++,Linux,FFmpeg ,webRTC ,rtmp ,hls ,rtsp ,ffplay ,srs)等等

三、散列表碰撞处理
一个散列函数能够将键转为数组索引,但是会出现两个或多个键的散列值相同的情况,即发生碰撞,处理碰撞的两种常用的方法是线性探测法和拉链法,下面我们一一学习实践。
3.1 线性探测(LinearProbingHashST)
用大小为M的数组保存N个键值对,其中M>N, 然后发生碰撞时,利用空位置进行处理。这类策略称为开放地址散列表,开放地址散列表最常见的方法就是线性探索法。
当碰撞发生时【当一个键的散列值f(k1),被另外一个不同的键k2占用】, 采用直接检查散列表中下一个位置,如果该位置没有被占用,则把k1存储在f(k1)+1的位置,否则继续+1探测,他对应的公式如下:f(key) = (f(key)+d) MOD m. (D = 1,2,…,m-1)
我们来看下如何解决上一小节的碰撞问题
a={12,24,38,15,16,29,78,67,50,21,22,47}
对于这个长为12数组,我们通过除留余数法进行散列表的构造
12 % 12 = 0
24 % 12 = 0 --》出现了碰撞 ((24 % 12)+1)% 12 = 1
38 % 12 = 2
15 % 12 = 3
16 % 12 = 4
29 % 12 = 5
78 % 12 = 6
67 % 12 = 7
50 % 12 = 2 --》出现了碰撞 ((50 % 12)+1)% 12 = 3,但是散列值为3的位置已经被15占用了,我们继续+1 探测,一直加到6时 ((50 % 12)+6)% 12 = 8
21 % 12 = 9
22 % 12 = 10
47 % 12 = 11
3.2 拉链法 (SeparateChainingHashST)
解决冲突的方式,处理上面介绍的开放寻址线形探测法外,还有一种比较常用的方式是拉链法:将大小为M的数组中的每个元素都指向一条链表,链表中的每个结点都存储了散列值为该元素索引的键值对。
这种方式的基本思想就是 选择足够大的数组M,使得所有链表都尽可能短,以保证高效的查询。
使用拉链法存储解决冲突,对应的查找分为两步
-
根据散列值找到对应的链表,
-
沿着链表顺序查找相应的键。

四、散列表代码实现
下面我们实现开放寻址线形探索方式解决碰撞,详见代码注释
#include<iostream>
const int DefaultSize = 128;
using std::cout;
using std::endl;
enum NodeInfo { Empty, Active };//记录节点的状态
template<typename T>
class HashTable
{
public:
HashTable(int d,int sz= DefaultSize);
~HashTable();
void printValue();
bool search(const T& k);//查看键k是否存在
bool insert(const T& k);//插入键k
private:
//寻找键k在哈希表的存储数组中对应的位置
int findPosByLinearProbing(const T& k)const; //使用线性探查法
int curSize; //curSize存储当前哈希表存储节点的数量
int maxSize; //maxSize为哈希表最多存储的节点的数量
NodeInfo* info;//存储每个节点的状态数组,作为辅助数组
int mod;//散列函数的MOD
T* value;//哈希表的存储节点的数组
};
template<typename K>
HashTable<K>::HashTable(int d, int sz)
{
mod = d;
maxSize = sz;
curSize = 0;
value = new K[maxSize];
info = new NodeInfo[maxSize];
for (int i = 0; i < maxSize; i++)//所有节点状态都设为空
info[i] = Empty;
}
template<typename K>
HashTable<K>::~HashTable()
{
if (value) delete[] value;
if (info) delete[] info;
}
template<typename K>
void HashTable<K>::printValue()
{
for (int i = 0; i < maxSize; i++)
{
if (info[i] == Active) cout << value[i] << " ";
else cout << 0 << " ";
}
cout << endl;
}
//查看键码k是否存在
template<typename K>
bool HashTable<K>::search(const K& k)
{
if (findPosByLinearProbing(k) >= 0)
{
return true;
}
return false;
}
template<typename K>
bool HashTable<K>::insert(const K& k)
{
if (findPosByLinearProbing(k) >= 0) return false;
int i = k % mod;
int j = i;//j作为移动的指针
do
{
if (info[j] == Empty) {//当节点状态为空时,进行插入,否则j将一直移动下去
value[j] = k;
info[j] = Active;
curSize++;
return true;
}
else
j = (j + 1) % maxSize;
} while (j != i);
return false;
}
//寻找键k在哈希表的存储数组中对应的位置,使用线性探测法
template<typename K>
int HashTable<K>::findPosByLinearProbing(const K& k) const
{
int i = k % mod;
if (info[i] == Empty) return -1;//如果info状态为空,那么该键码不存在哈希表中
int j = i;//j作为移动的指针
do
{
if (info[j] == Active && value[j] == k) return j;//如果节点转态为Active,且value数组在j处值为k
j = (j + 1) % maxSize;//位移
} while (j != i);
return -1;
}
int main()
{
HashTable<int> myhash(12, 12);
int a[] = { 12,38,24,15,16,29,78,47,67,50,21,22};
for (int i = 0; i < sizeof(a) / sizeof(int); i++)
{
myhash.insert(a[i]);
}
myhash.printValue();
return 1;
}
我们可以看到散列表的代码相比二叉查找树、平衡二叉树更简单,当然相比二叉树,散列表需要设计散列函数。性能对比如下
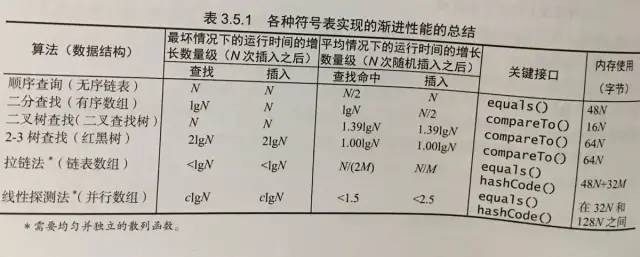
图片来源于《算法》
关于查找算法我们就先学习实践到这里,从下一篇我们继续CPP的其他学习,欢迎关注公众号“音视频开发之旅”,一起学习成长。
收获
-
了解了散列表的实现和原理
-
散列表解决冲突的常用方法
-
代码实现散列表查询














 137
137











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









