









目录
Bert-P/HSum
Bert用于ABSA;条件随机场AE;并行/分层聚合Bert的ASC
年份:2020
标题:Improving BERT Performance for Aspect-Based Sentiment Analysis(提高基于方面的情绪分析的BERT性能)
摘要:基于方面的情绪分析(ABSA)解决了从消费者产品评论等固执己见的数据中提取情绪及其目标的问题。分析复习中使用的语言是一项困难的任务,需要对语言有深入的理解。近年来,BERT等深度语言模型在这方面取得了很大的进展。在这项工作中,我们提出了两个简单的模块,即并行聚合和分层聚合,在BERT之上用于两个主要的ABSA任务,即方面提取(AE)和方面情绪分类(ASC)。通过所提出的模块,我们证明了BERT体系结构的中间层可以用来提高模型的性能。
代码:
论文内容
1.研究背景
在行业环境中,对消费者如何看待产品有一个有效的概念是极其重要的。如今,他们通过对产品的评论来传达自己的看法,主要使用社交网络。他们可能有积极的意见,可能导致企业的成功,或消极的意见,可能导致企业的消亡。由于这些观点在许多领域的丰富,他们的分析是一项耗时和劳动密集型的任务,这就是为什么各种机器学习技术,如支持向量机(SVM)(科尔特斯和瓦普尼克,1995;基里琴科等人,2014;巴萨里等人,2013年)、最大熵(Jaynes,1957;尼格姆等人,1999年)、朴素贝叶斯(杜达等人,1973年;加马洛和加西亚,2014年;迪努和尤加,2012年)和决策树(昆兰,1986年;Wakade等人,2012年)已被提议进行意见挖掘。
近年来,深度学习(DL)技术由于计算能力的提高和大量免费数据得到了广泛的应用(Zhang et al.,2015;Liu等人,2015;Wang等人,2016)。这些技术产生巨大影响的领域之一是自然语言处理(NLP),其中建模(即理解)语言起着至关重要的作用。BERT(Devlin等人,2019)是一种最先进的模型,已广泛应用于许多NLP任务(Kantor等人,2019;戴维森等人,2019)以及其他领域(彭等人,2019;阿尔森泽等人,2019年)。它已经在大量的维基百科文档和书籍的语料库上进行了训练,以便从上下文中学习语言、语法和语义。其架构的主要组件被称为变压器(Vaswani et al.,2017),由注意力头组成的块。这些头部被设计是为了特别注意与特定给定任务相对应的输入句子的部分(Vig和贝林科夫,2019)。在这项工作中,我们利用BERT来进行基于方面的情绪分析(ABSA)任务。
我们的主要贡献是提出了两个简单的模块,可以帮助提高BERT模型的性能。在我们的模型中,我们选择条件随机场(CRFs)作为序列标记任务,从而产生更好的结果。此外,我们的实验表明,训练BERT获得更多的时代并不会导致模型过拟合。然而,经过一定数量的训练时期后,学习似乎停止了。
2.相关方法
本文献研究时参考或使用的相关方法和思想
最近,有大量的工作利用本模型在各种任务如文本分类,问题回答,摘要总结,特别是ABSA任务。Zhao等人(2020)使用图卷积网络(GCNs),考虑了序列中的情感依赖性。换句话说,它们表明,当一个序列中有多个方面时,其中一个方面的情绪就会影响另一个方面的情绪。利用这些信息可以提高模型的性能。一些研究将方面提取(AE)任务转换为句子对分类任务。例如,Sun等人(2019a)使用序列的方面项构建辅助句。然后,利用这两个序列,他们在这个特定的任务上微调BERT。
模型的Word和句子级表示也可以使用特定领域的数据进行丰富。Xu等人(2019)通过对BERT模型进行后训练,他们称之为BERT-PT,证明了这一点。在我们的实验中,我们使用他们的预训练模型来初始化我们的模型。由于BERT模型的特殊架构,可以在它上面附加额外的模块。Li等人(2019)添加了不同的层,如RNN层和CRF层,以端到端方式执行ABSA。在我们的工作中,我们使用来自BERT体系结构的相同层模块,同时也使用隐藏层进行预测。
3.研究方法
ABSA中的两个主要任务是方面提取(AE)和方面情绪分类(ASC)。后者处理的是一个句子整体的语义,而前者处理的是寻找那个情感指的是哪个词。我们将在本节中简要地描述它们。
任务描述
方面提取
在AE中,目标是提取产品的特定方面,在评论中表达某种类型的情绪。例如,在这句话中,“笔记本电脑的电池很好。”,电池是被提取的方面。有时,方面词可以是多重的,在这种情况下,所有它们都需要相应地标记。这个任务可以看作是一个序列标记任务,其中单词从三个字母的集合中分配一个标签,即{B,I,O}。
序列中的每个单词可以是方面术语(方面词)的开头单词:B;也可以是在方面词当中:I;也可以不是方面词:O。将每个词分类为这三个类中的一个,是使用BERT架构上的全连接层并应用Softmax函数来完成的。
方面情感分析
在这项任务中,目标是提取消费者在评论中所表达的情绪。给定一个序列,正、负和中性三类中的一类被提取作为该序列的类。这个元素的表示体现在BERT模型的体系结构中。对于每个作为输入的序列,有两个额外的标记被BERT模型使用:

其中,wi是序列单词,[CLS]和[SEP]标记在输入阶段被连接到句子中。虽然[CLS]令牌用于存储句子的情绪表示,但[SEP]令牌用于分离输入序列,以防有多个输入序列(例如,在一个问题回答任务中)。在该体系结构的最后一层中,将一个Softmax函数应用于[CLS]嵌入,并计算出类概率。
提出模型
深度模型可以在语言成长的过程中获取更深层次的语言知识。如Jawahar等人(2019)所示,BERT的初始层到中间层可以提取语法信息,而语言语义则以更高的层次表示。 由于提取句子情感对语义要求很高,所以我们期望在网络的更高层次中看到这一点。这是我们模型背后的直觉,我们利用了BERT模型的最后一层。
我们在这里介绍的两个模型在原则上很相似,但在实现上略有不同。此外,对于这两个任务,损失的计算方式是不同的。而对于ASC任务,我们使用交叉熵损失,而对于AE任务,我们使用CRFs。选择这种选择的原因是,AE任务可以被视为序列标记。因此,在序列中考虑到之前的标签是非常重要的,而这正是CRF层所做的。
条件随机场(CRF)

CRFs(Lafferty等人et al.,2001)是一种图形模型,已在计算机视觉(如像素级标记(Zheng等人,2015))和NLP中用于序列标记。由于AE可以被认为是一个序列标记任务,所以我们选择在模型的最后一部分中使用CRF层。为方面提取使用CRF模块的理由是,这样做有助于网络考虑到标签的联合分布。这可能是很重要的,因为序列单词的标签依赖于出现在它们之前的单词。例如,如图1所示,形容词“好”的出现可以给模型一个线索,即下一个词可能不是另一个形容词。计算标签联合概率的方程如下:
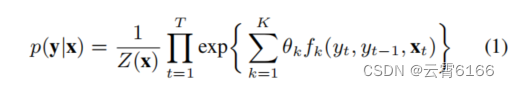
在式1中,x是观察到的序列,y是标签序列,k和t分别是序列中特征函数和时间步长的索引。序列字之间的关系用特征函数{fk}来表示。这些关系可以是强的,也可以是弱的,或者根本不存在。它们是由它们在训练阶段计算出的权重{θk}来控制的。最后,Z (x)是一个归一化因子。
并行聚合(Parallel Aggregation)
Rossi等人(2020)表明,可以更多地利用深度模型的隐藏层来提取特定区域的信息。受他们工作的启发,我们提出了一个名为P-SUM的模型,将性能最好的层模块应用到每个一个的BERT层上。图2显示了该模型的详细信息。我们利用了BERT模型的最后四层,再增加一个BERT层加上一个全连接层,并用Softmax函数和一个CRF层计算该分支在输入数据上的损失。

原因是所有更深层次都包含了有关任务的大部分相关信息。因此,从每个信息中提取这些信息并将它们组合起来可以产生更丰富的语义表示。为了计算总损失,将所有分支的损失值求和,并在图中用Σ符号表示。这样做是为了在优化参数时考虑到所有的损失。然而,为了计算网络的输出对数,我们对四个分支的输出对数进行平均。
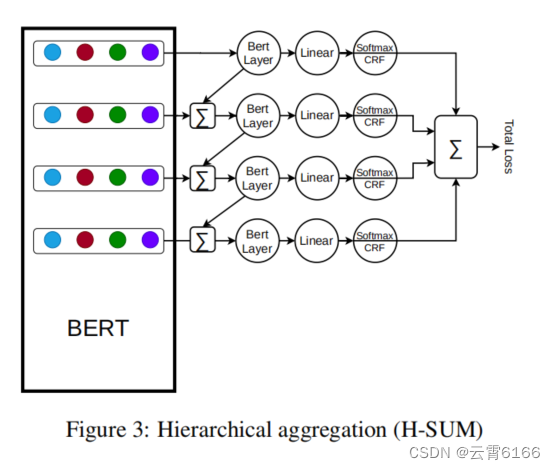
层次聚合(Hierarchical Aggregation)
我们的层次聚合(H-SUM)模型的灵感来自于特征金字塔网络(FPNs)的使用(Lin et al.,2017)。其目标是从BERT模型的隐藏层中提取更多的语义。H-SUM模型的体系结构如图3所示。在这里,在每个隐藏层上应用BERT层后,输出与前一个层聚合(按元素级)。同时,与P-SUM相似,每个分支产生一个损失值,该损失值对总损失的贡献相等,因为总损失是所有所有损失的总和。
4.实验效果
为了进行我们的实验,我们使用了与Xu等人(2019年)相同的代码库。我们在一个带有8 GB内存的GPU (GeForce RTX 2070) 上进行了实验,我们的模型和BERT-PT模型都使用了16个批次作为基线。在训练时,使用Adam优化器,学习速率设置为3e−5。从分布式训练数据中,我们使用了150个例子作为验证。为了评估模型,官方脚本用于AE任务,ASC任务使用来自同一代码库的脚本。结果报告在AE的F1和ASC的准确性和MF1中。F1分数是精确度和查全率的调和平均值,而MF1分数是每个班级的F1分数的平均值。
数据集
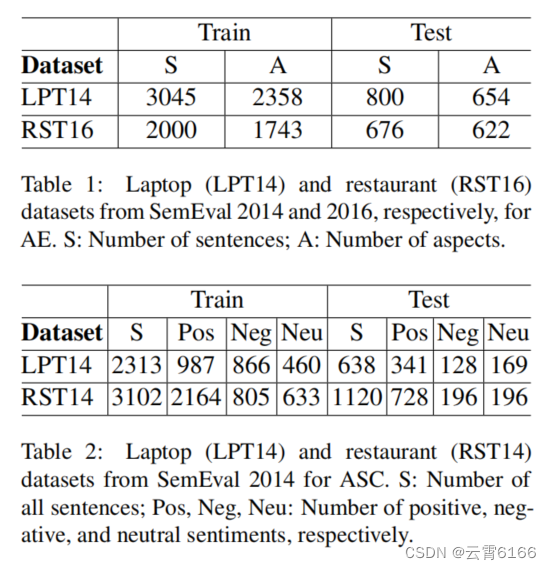
在我们的实验中,我们使用了来自SemEval 2014 subtask 2和SemEval 2016subtask1的Laptop笔记本电脑和Restaurant餐厅数据集。这些集合由经过手动注释的用户评论组成。表1和表2显示了这些数据集的统计数据。在选择数据集时,我们选择了之前工作中使用的数据集(Karimi等人,2020;Xu等人,2019),以便我们可以将我们的模型和这些模型的性能进行可靠的比较。
BERT层的性能
根据网络的深度,它的性能可能是不同的。因此,我们进行了实验,以找出BERT模型的每一层的表现。结果如图4所示。可以看出,在更深的层次中,特别是在最后四组中,可以获得更好的性能。因此,我们的模块在这四个层上进行操作,以实现一个改进的模型。
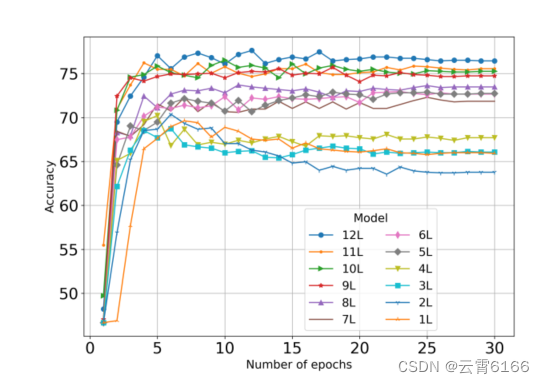
通过ASC在RST14验证数据上的BERT-PT权重初始化的BERT层的性能。每个模型都是使用指定的层数的BERT模型。1L表示使用第一层,2L表示使用前2层等等。精度值为百分比。
性能在几个Epoch内仍然有所提高,然后在随后的时期中出现波动,这表明,随着更多的训练,网络权值继续变化,直到它们在以后的时代几乎保持稳定,这表明没有更多的学习。从图4中,我们看到在4或5个训练阶段,我们接近最大性能
增加训练Epochs
更多的训练可以导致更好的网络性能。然而,一个风险是过拟合的风险,特别是当训练例子的数量比模型中包含的参数的数量不大时。然而,在BERT的情况下,正如Li等人(2019)也观察到的那样,似乎随着训练次数的增加,模型虽然训练数据点的数量相对较少,但并不会过拟合。这背后的原因可能是,我们使用的是一个已经预先训练过的模型,它已经看到了大量的数据(维基百科和书籍语料库)。因此,我们可以期望,通过进行更多的训练,该模型将仍然能够推广。
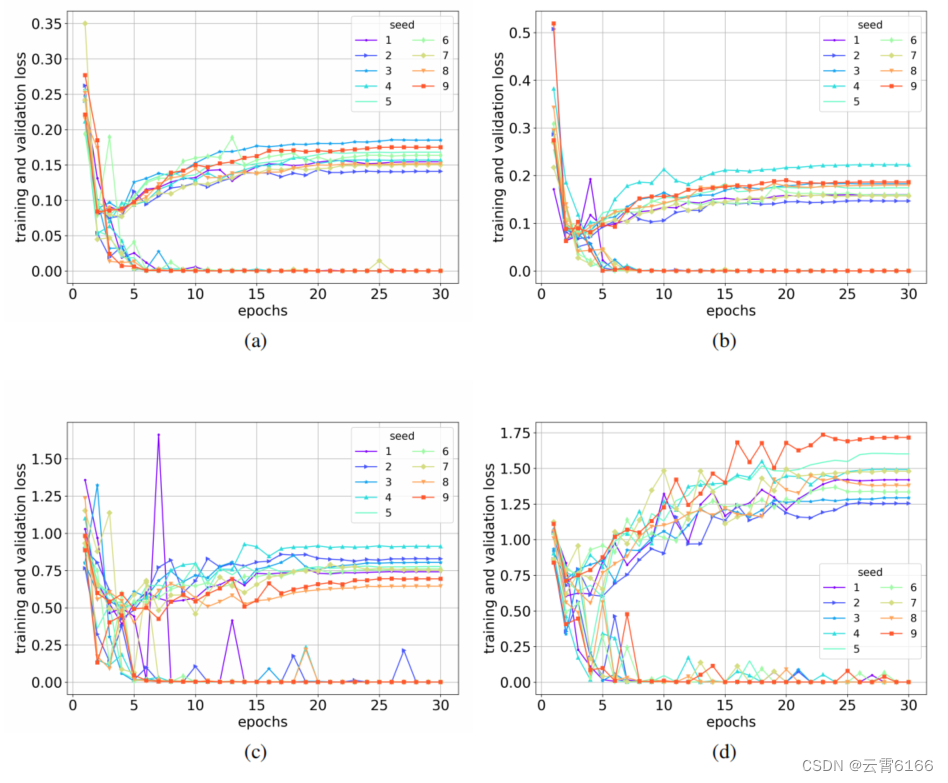
使用AE(笔记本(a)和餐厅(b))和ASC(笔记本©和餐厅(d))的BERT-PT权重初始化的12层BERT模型的训练和验证损失。在每个图中,上面的线是验证损失,底线是训练损失,每一行对应一个种子号。
通过查看图5中的验证损失,也可以得到同样的观察结果。如果出现过度适应,我们预计损失会上升,表现会下降。然而,我们可以看到,随着第二个Epochs之后损失的增加,性能在几个Epoch内仍然有所提高,然后在随后的时期中出现波动,趋于平缓。
实验结果
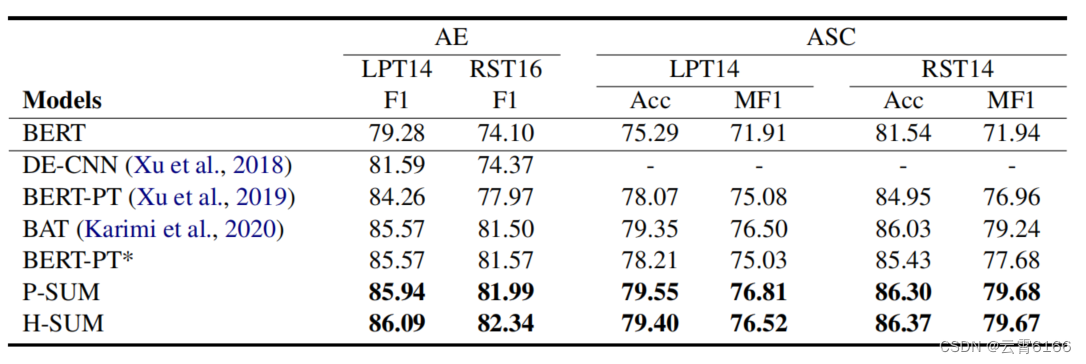
实验结果表明,随着训练时代的增加,BERT模型也得到了改善。为了将我们提出的模型与Xu等人(2019年)进行比较,我们对两者都进行了相同的模型选择。与Xu等人(2019)和Karimi等人(2020)根据最低的验证损失选择了他们最好的模型不同,我们在观察到验证集的精度上升后,选择了经过四个epoch训练的模型(图4)。因此,在表3中,我们报告了原始的BERT-PT分数以及我们的模型选择的分数。从表3中还可以看出,所提出的模型在数据集和任务上都优于新选择的BERT-PT模型,在笔记本电脑和餐厅的ASC中,MF1得分分别达到了+1.78和+2。同样值得注意的是,在精度方面,H-SUM模块在大多数情况下都优于P-SUM模块。这可以归因于该模块的层次结构,以及该模块的每个分支都受益于在上一个分支中处理的信息。
5.研究结论
提出了两个简单的模块,利用隐藏层的比特语言模型来生成输入序列的更深层次的语义表示。网络层以并行方式聚合,或者分层聚合。对于构建在选定的隐藏层之上的体系结构的每个分支,我们分别计算损失。然后将这些损失汇总,以产生模型的最终损失。我们使用条件随机场来处理方面提取,这有助于考虑序列标签的联合分布,以实现更准确的预测。我们的实验表明,所提出的方法优于训练后的普通BERT模型。
精读笔记
- vanilla:n. 香子兰,香草;香子兰荚;香子兰精,香草精 adj. 香草的;香草味的;相对没有新意的,普通的















 252
252











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









