







目录
1.DDP(Distributed Data Parallel):
持续更新
性能衡量指标
1. 吞吐:
大模型吞吐量的计算需要综合考虑模型的计算需求、硬件性能、系统架构以及软件优化等多个方面(计算量、硬件性能、并行策略、内存限制、通信开销、模型结构、软件优化、数据加载等)可能没有一个简单的公式,而是需要具体问题具体分析,结合实测和理论估算。
2. FLOPS
- FLOPs(浮点运算次数)Floating Point Operations :完成一次计算任务所需的浮点运算(加法乘法等)的总次数
- FLOPS(每秒浮点运算次数)Floating Point Operations Per Second:硬件每秒能执行的浮点运算次数,是衡量计算设备性能的指标;
- FLOPs是计算量,FLOPS是算力;
3.QPS:
QPS = 每秒成功处理的请求数
例如:一个 API 接口在 1 秒内处理了 500 次用户请求,则其 QPS 为 500。

高效训练框架:
1.DDP(Distributed Data Parallel):
是 PyTorch 中用于多 GPU 训练的核心并行技术,旨在通过高效的数据并行策略加速模型训练,尤其适合大规模深度学习任务。通过多进程和 Ring-AllReduce 通信实现了高扩展性和低通信开销。其核心优势包括:
- 模型复制:每个gpu有一个完整的模型;支持单机多卡,多机多卡。
- 数据分片:数据均匀分配到GPU,每个GPU处理不同的数据子集;多进程(每个gpu一个进程)。
- 梯度同步:通过高效的通信协议Ring-AllReduce同步梯度,确保所有模型副本的参数一致。
实现:
1. 初始化进程组
设置分布式训练环境,指定通信后端(如 NCCL)和进程间通信方式
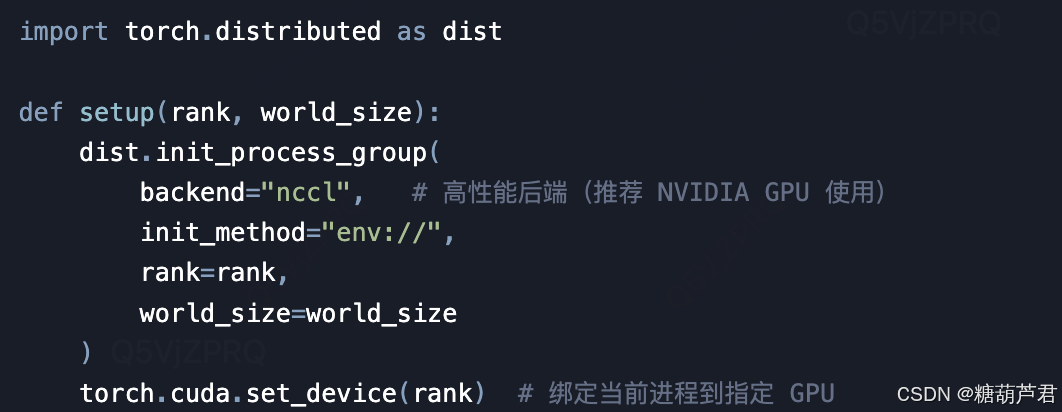
封装模型

数据加载器DistributedSampler确保gpu加载不同的数据分片

启动多进程:torch.multiprocessing.spawn
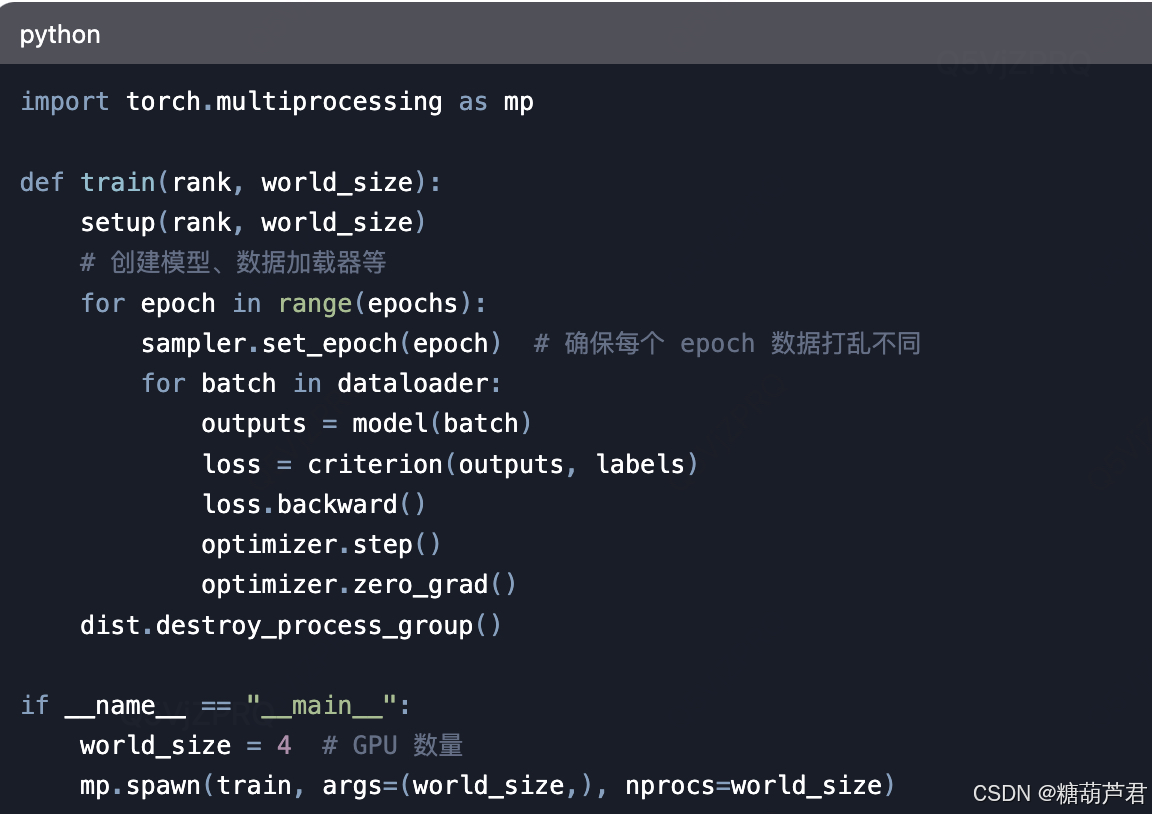
模型相关细节
1. 各模型参数量:

各模块参数量:
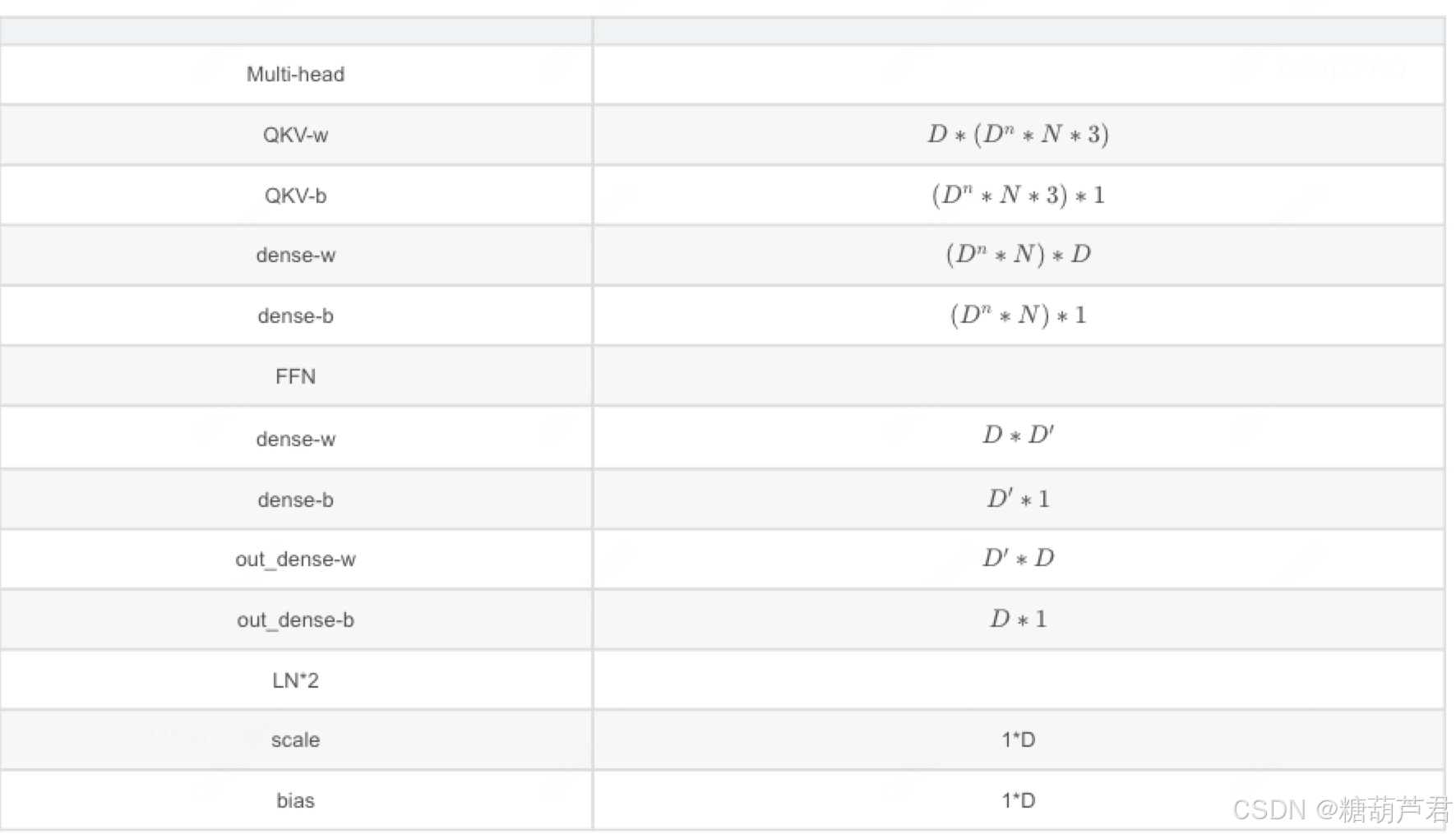
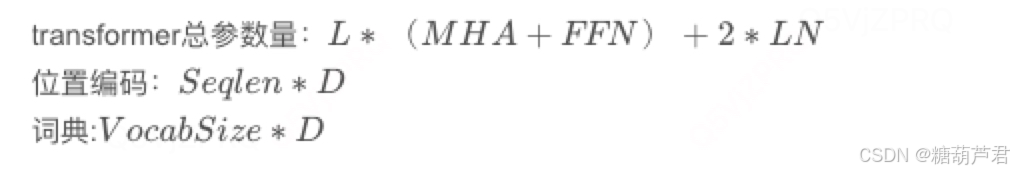
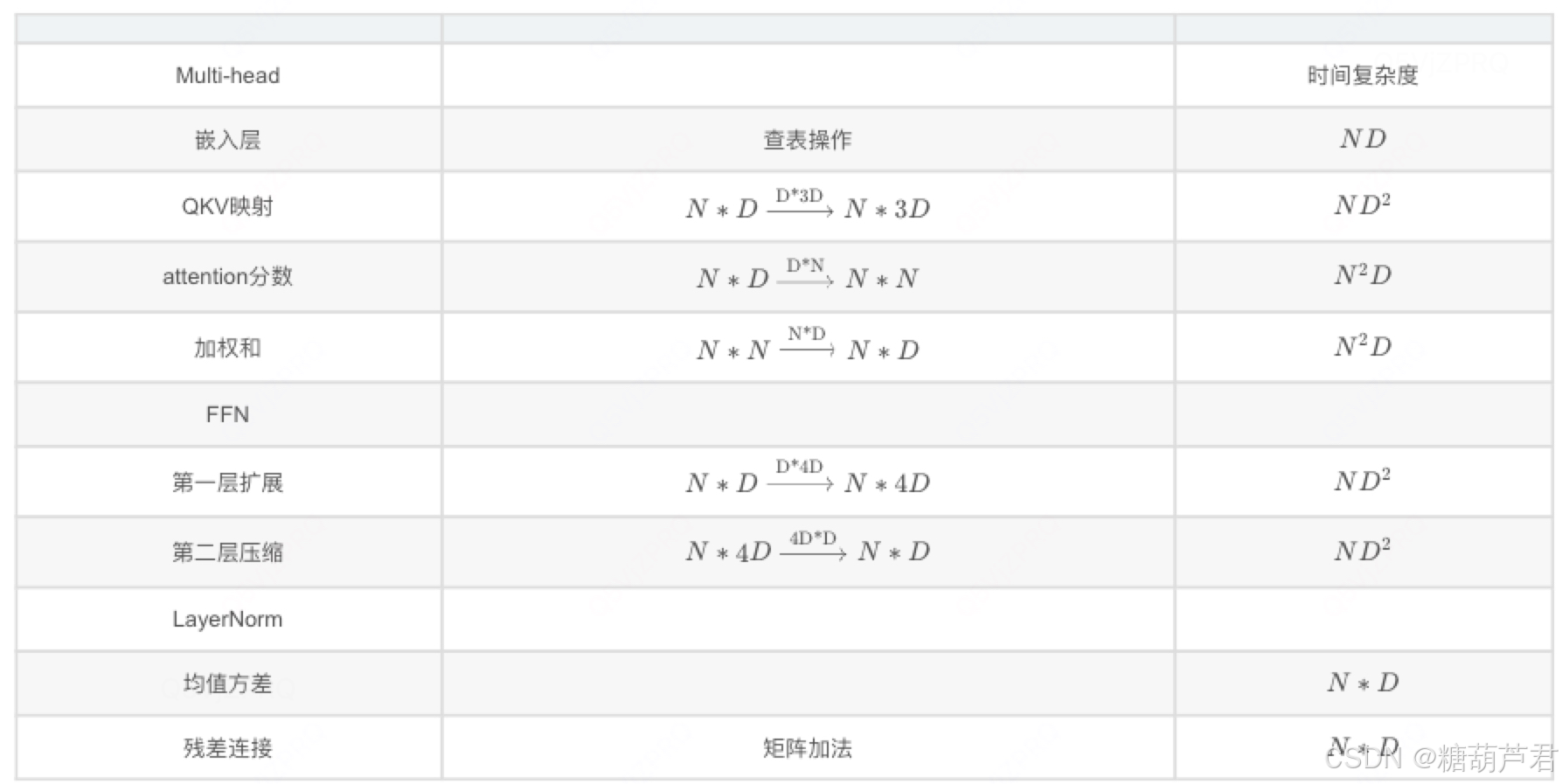
2. 时间复杂度
MHA 和 FFN是计算复杂度的主要贡献者。

3. 为什么attention计算要除以根号d
当增大时,
方差会变大, 方差变大会导致向量之间的差值变大。导致softmax退化为argmax,最大值softmax之后为1,其他值为0.这样的话反向传播梯度会变为0,也就是梯度消失。
推理相关:
1. KV cache:
推理时每一步不需要重新计算K,V,将新的输入token与之前序列返回的K,V进行拼接后得到新的K,V(空间换时间);


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









