









目录
概要
这篇论文主要讲的是凯明大佬在resent发表之后,对resent中的shortcut的公式理解和结构改进实验。文中通过对残差模块的改建实验得到了残差模块的最优形式,在层数不断增大时,效果得到了极大的提升。
整体架构流程
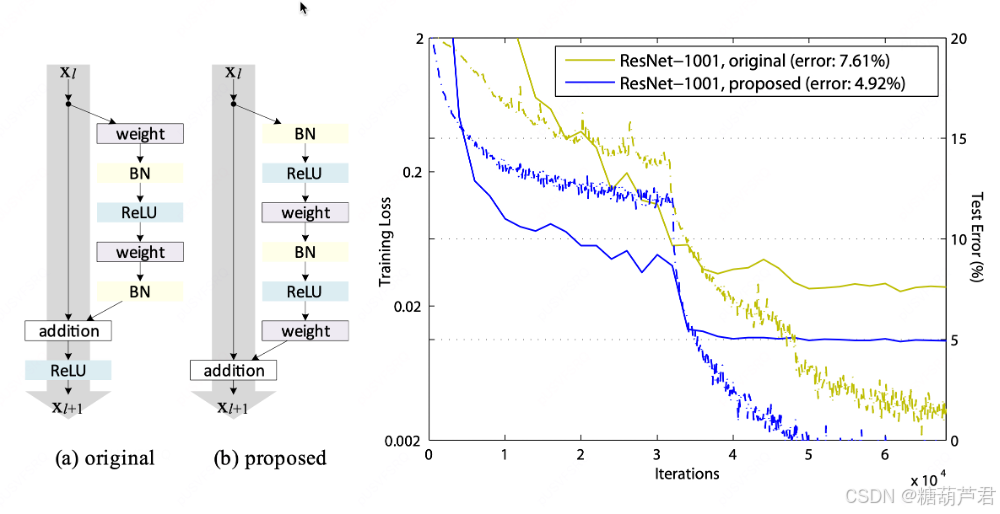
图a未原始的transformer结构,右图为该文改进后的结构,可以看到在train,test loss上都有很大的提升。
Residual Units:
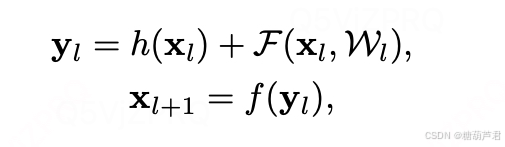
本文分别对h(x)与F(x)两个部分的内部结构进行改造,最终得到的结论为h(x)为恒等映射的话效果时最好的:
如果是恒等映射的话,那么当层数增加时,H(x)的梯度恒为1,
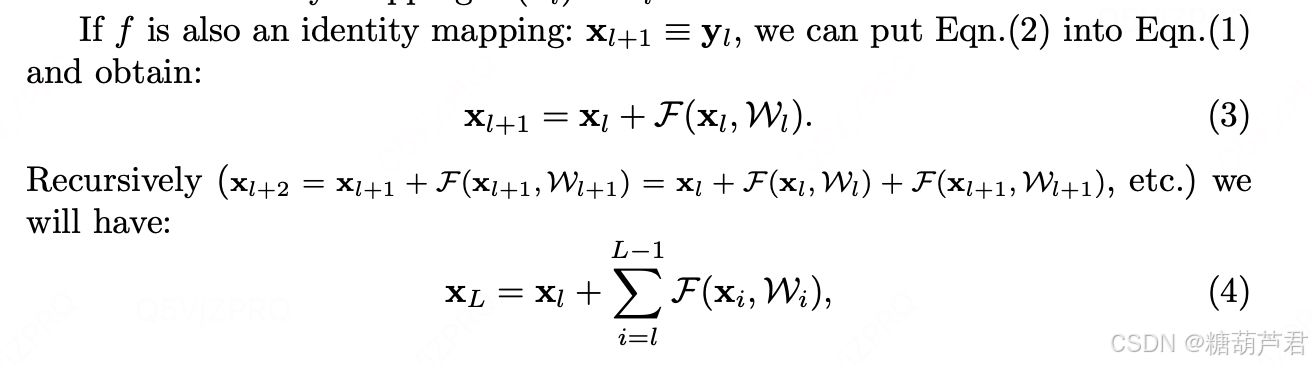
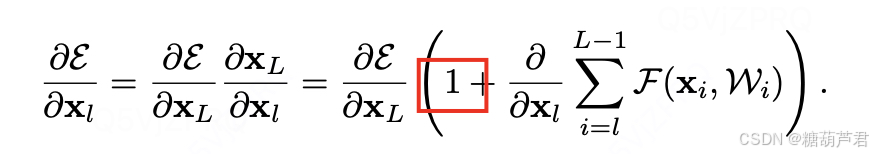
而如果不是恒等映射,而是增加了其他计算的话:
那么当层数增大时,H(x)的系数为L个个参数连乘,那么很容易发生系数很小,梯度消失,梯度难以回传到浅层的问题

对h(x)做了不同类型的尝试,最终确实是恒等映射的效果最好:
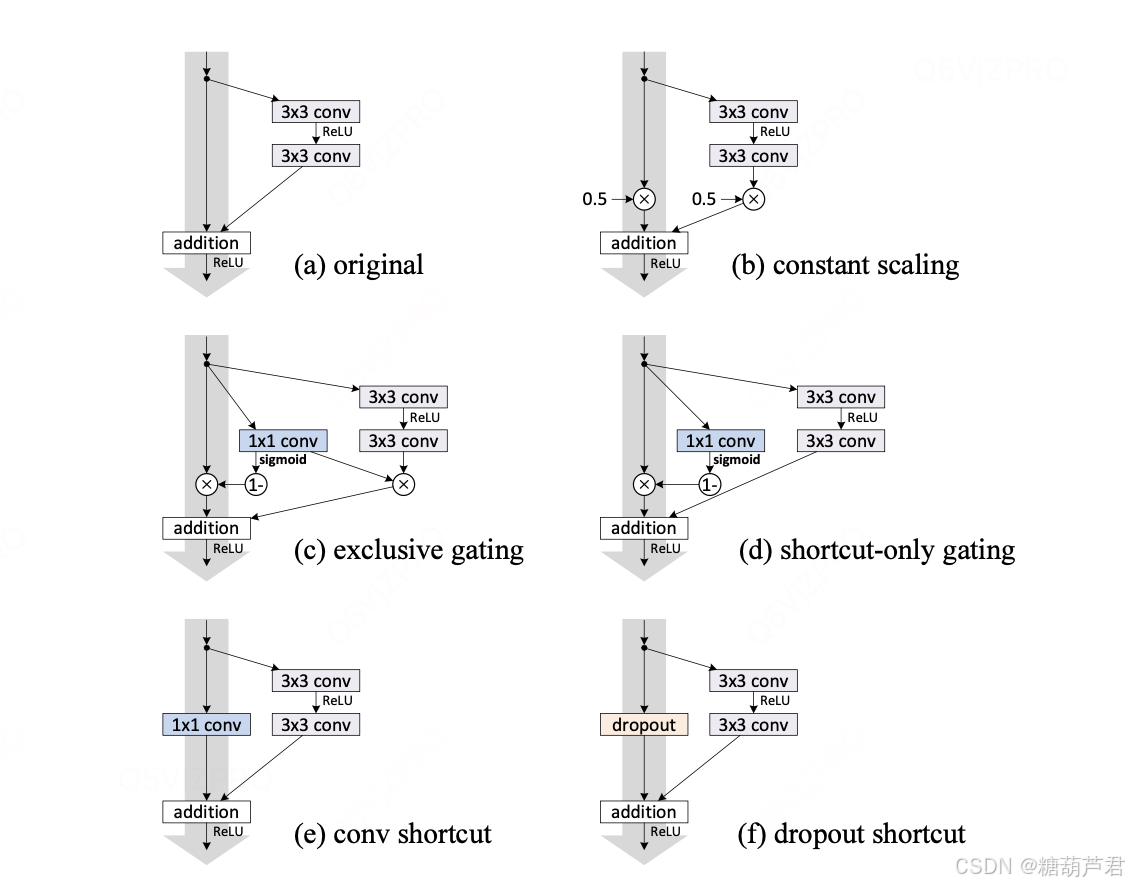
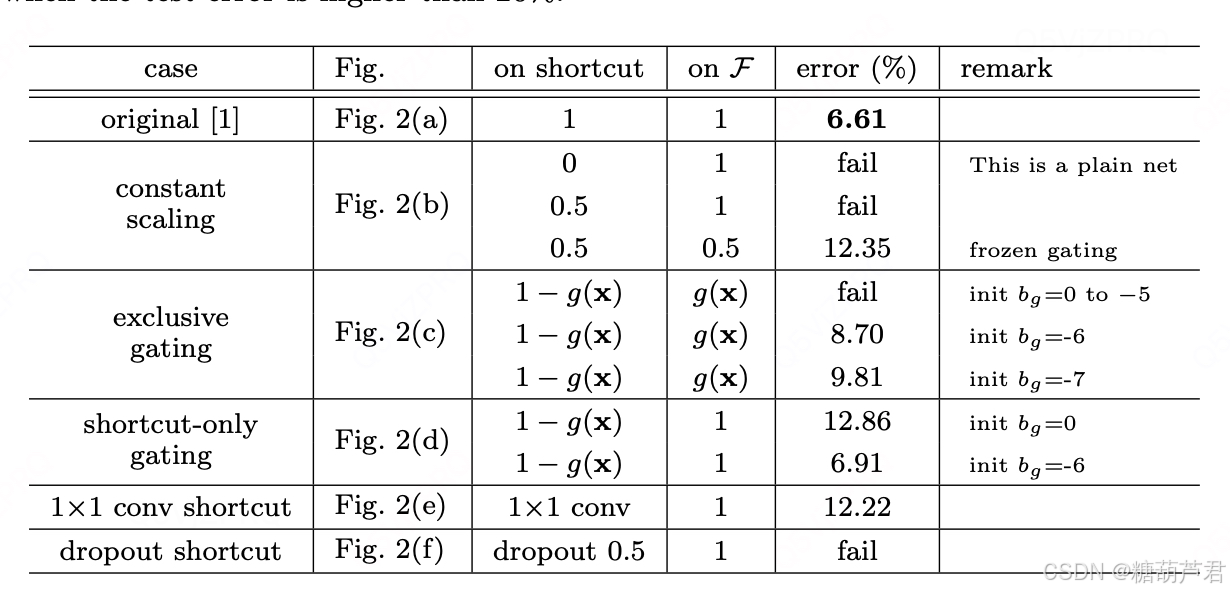
同时也对残差模块F(x)中激活,BN,addition的组合方式进行了探讨:
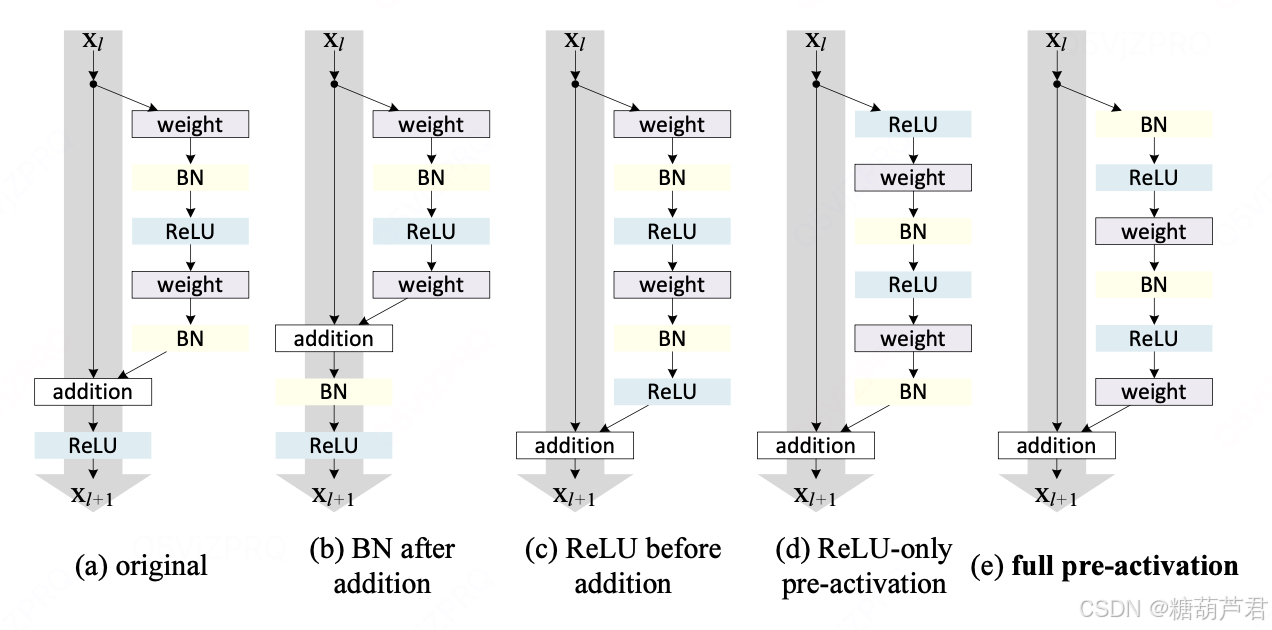
最终得到的full-pre-activation模式的组合效果是最好的
总结
- h,f 函数应该使用恒等映射,保证梯度可以直接回传至任意浅层,不容易产生梯度消失或爆炸,相比其它h,f函数效果更好
- h: 使用scale/gating/conv,会阻碍传播,产生优化问题
- f : 使用BN会阻断梯度的传播,不要加在addition之后
- ReLU不要加在残差模块的最后:希望残差模块的输出是-无穷-正无穷之间
- pre-activate:
- 1.保证f和h是恒等映射
- 2.在残差模块中将BN和Relu函数提前,效果最好
- 3.将BN放在weight之前:保证每一层残差模型的输入都是归一化的
实践
借鉴这篇论文在transormer中MHA和FFN中的残差模块模拟该文中提到的对比方式:
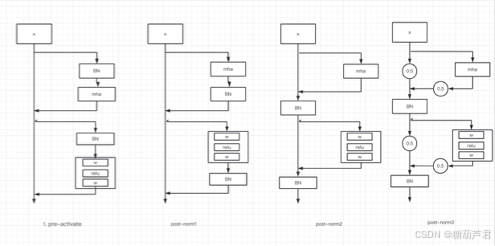
最终的结论与论文一致;pre-activation的效果是最好的。

















 1897
1897

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









