










Spark Streaming 整合 Kafka(Receiver方式)在生产集群运行
步骤概述
1 启动zookeeper
2 启动Kafa
3 创建kafka topic
4 通过控制台测试本kafka topic是否能够正常的生产和消费信息
5 写Spark Streaming代码
6 使用mvn命令打包
7 下载spark-streaming-kafka-0-8-assembly_2.11-2.2.0.jar
6 使用spark-submit启动Spark Streaming程序(传入参数zookeeper,group,topic,线程数)(传入参数 hadoop000:2181 test kafka_streaming_topic 1)
7 通过kafka-console-producer生产数据
8 查看spark终端是否成功处理数据
/Receiver没有Direct好,生产上一般使用Direct,Direct在Spark1.3之后才有/
1 启动zookeeper
./zkServer.sh start
2 启动Kafa
$KAFKA_HOME/bin/kafka-server-start.sh -daemon $KAFKA_HOME/config/server.properties
3 创建kafka topic
$KAFKA_HOME/bin/kafka-topic --list --zookeeper localhost:2181
4 通过控制台测试本kafka topic是否能够正常的生产和消费信息
// 启动消费者
$KAFKA_HOME/bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic kafka_streaming_topic
// 启动生产者
$KAFKA_HOME/bin/kafka-console-producer.sh --broker-list localhost:9092 --topic kafka_streaming_topic
向生产者发送数据,发送后查看消费者有没有接收到数据,如果消费者能够接收到数据证明kafka调通了


5 写Spark Streaming代码
// 向maven添加依赖
groupId = org.apache.spark
artifactId = spark-streaming-kafka-0-8_2.11
version = 2.2.0
package com.imooc.spark
import org.apache.spark.SparkConf
import org.apache.spark.streaming.kafka.KafkaUtils
import org.apache.spark.streaming.{Seconds, StreamingContext}
/*Spark Streaming 整合 Kafka Receiver 方法*/
object KafkaReceiverWordCount {
def main(args: Array[String]): Unit = {
if(args.length != 4) {
System.err.println("Usage: KafkaReceiverWordCount <zkQuorum> <group> <topics> <numThreads>")
}
val Array(zkQuorum, group, topics, numThreads) = args
val sparkConf = new SparkConf() //.setAppName("KafkaReceiverWordCount").setMaster("local[2]")
val ssc = new StreamingContext(sparkConf, Seconds(5))
val topicMap = topics.split(",").map((_, numThreads.toInt)).toMap
// Spark Streaming对接Kafka需要ssc,zookeeper,组,topic
val messages = KafkaUtils.createStream(ssc, zkQuorum, group, topicMap)
// 自己去测试为什么要取第二个
messages.map(_._2).flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).print()
ssc.start()
ssc.awaitTermination()
}
}
6 使用mvn命令打包
// 在项目的根目录运行该命令,或者直接在idea的终端中运行
mvn clean package -DskipTests
7 下载spark-streaming-kafka-0-8-assembly_2.11-2.2.0.jar
spark-streaming-kafka-0-8-assembly_2.11-2.2.0.jar
// 注意版本问题,这个是kafka版本为0.8,scala版本为2.11,spark版本为2.2.0
// 如果你用的组件版本和上面的不同请到下面这一个链接搜索
阿里云maven仓库
6 使用spark-submit启动Spark Streaming程序(传入参数zookeeper,group,topic,线程数)(传入参数 hadoop000:2181 test kafka_streaming_topic 1)
// 如果你下载了上面的jar包并上传到了spark服务器中,可以使用这一个启动命令,注意修改一下–jars路径和spark程序jar包路径
spark-submit \
--class com.imooc.spark.KafkaReceiverWordCount \
--master local[2] \
--name KafkaReceiverWordCount \
--jars /home/hadoop/lib/smj/spark-streaming-kafka-0-8-assembly_2.11-2.2.0.jar \
/home/hadoop/lib/smj/sparktrain-1.0.jar hadoop000:2181 test kafka_streaming_topic 1
7 通过kafka-console-producer生产数据
// 随便发一些数据,注意要用空格把词分开
$KAFKA_HOME/bin/kafka-console-producer.sh --broker-list localhost:9092 --topic kafka_streaming_topic
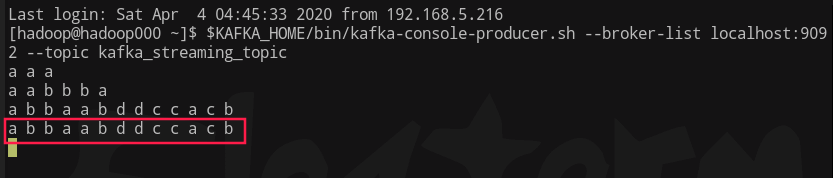
8 查看spark终端是否成功处理数据
















 728
728











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









