







 本文介绍了Spark作为MapReduce的替代品,因其内存计算和DAG执行模型而更快。Spark的DAG使得多阶段任务能高效执行,RDD的容错机制保证了稳定性。Spark还支持多种编程语言,提供了丰富操作,并能在不同运行模式下工作。Spark生态系统BDAS包括MLlib、GraphX、Spark Streaming等组件,扩展了Spark的功能。
本文介绍了Spark作为MapReduce的替代品,因其内存计算和DAG执行模型而更快。Spark的DAG使得多阶段任务能高效执行,RDD的容错机制保证了稳定性。Spark还支持多种编程语言,提供了丰富操作,并能在不同运行模式下工作。Spark生态系统BDAS包括MLlib、GraphX、Spark Streaming等组件,扩展了Spark的功能。
1、Spark是什么
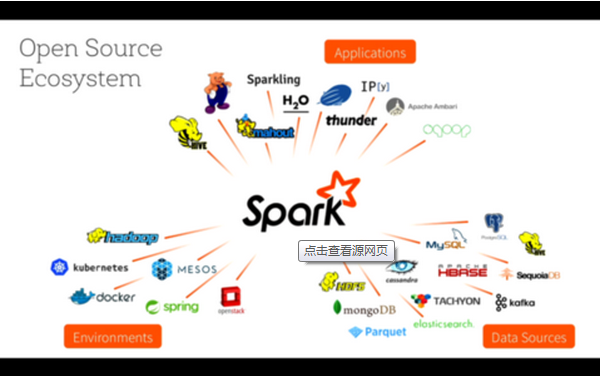
Spark是基于内存计算的大数据并行计算框架,是一个用来实现快速而通用的集群计算平台。它替代了广泛使用的MapReduce计算模型,并且支持交互式查询和流处理等其他高效计算模型。
2、Spark与Hadoop的关系
Spark是一个计算框架,它只是MapReduce的替代方案,当然随着spark发展壮大,现在spark也形成了它自己的生态系统;而Hadoop是一个生态系统,包含计算框架MapReduce和分布式文件系统HDFS,还有Hbase,Hive等。
2.1、为何Spark比MapReduce快
1、基于MapReduce的计算引擎通常会将中间结果输出到磁盘上,进行存储和容错,磁盘IO开销是造成MapReduce慢的主要原因。
MapReduce将任务划分成map和reduce两个阶段,map产生的中间结果写回磁盘。那么在这两个阶段之间的shuffle操作就需要从网络中的各个节点进行数据拷贝,那么就会有大量的时间耗费在网络磁盘IO中而不是在计算上。
举个例子,例如像逻辑回归这样的迭代式的计算,MapReduce的弊端会显得更加明显。

Hadoop磁盘读写 IO开销大
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1372
1372

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









